機械学習のバイナリクラス分類用の手法の1つに、ロジスティック回帰モデルがあります。これはモデルの解釈性も良く、広く一般に使われています。この手法に関連した変数変換手法である WoE (Weight of Evidence) と、特徴量の重要度を測る指標である IV (Information Value) は、あまり一般的では無いかも知れませんが、金融工学等の世界ではよく利用されます。
この記事では、WoE と IV を用いた信用スコアカード分析の例題 (Case Study for Credit Scorecard Analysis) を解説します。この例題は、creditscorecard オブジェクトの作成、データのビン化、ビン化されたデータ情報の表示とプロットについて説明しており、また、ロジスティック回帰モデルを適合させ、スコアカードモデルのスコアを取得し、デフォルトの確率を決定し、3つの異なる指標を使用して信用スコアカードモデルを検証する方法も示しています。
実行環境
MATLAB Version
R2022b
Toolboxes
- Financial Toolbox
- Optimization Toolbox
- Statistics and Machine Learning Toolbox
Step 0. 金融分野以外の方のための予備知識
信用スコア
個人の属性 (年齢、性別、決済情報、デフォルトの有無、学歴、資産 ... etc ) をまとめた情報 (信用データカード) から、個人の信用力を評価して点数化したもの。
信用スコアカード
個人の属性のデータ要素、または変数を用いてリスク許容度を決定する数式 (数学モデル)。
デフォルト
債務不履行のこと。借入人が自らの借入について、約束通りの利払いや元本の返済が約束通りに出来なくなること。
ビン化
数値データを適当な境界で区切り、カテゴリカルデータ化すること。ビン分割 (Binning) とも呼ばれる。例えば、年齢を 10代、20代、... とするのもビン化。
Step 1. creditscorecard オブジェクトの作成
CreditCardData.mat ファイルを使用して、データをロードします(Refaat 2011 のデータセットを使用します)。データに多くの予測変数が含まれている場合、まず screenpredictors (Risk Management Toolbox) を使って、予測変数のセットを、信用スコアカードの応答変数に対して最も予測力のあるサブセットに絞り込むことができます。そして、creditscorecard オブジェクトを作成するときに、この予測変数のサブセットを使用することができます。さらに、Threshold Predictors(Risk Management Toolbox)を使用して、screenpredictors(Risk Management Toolbox)からの出力から、信用スコアカードの予測変数の閾値を対話的に設定することができます
creditscorecard オブジェクトを作成する場合、デフォルトでは、'ResponseVar' はデータの最後の列(この例では 'status')に、'GoodLabel' は頻度の最も高い応答値(この例では 0)に設定されています。creditscorecard のシンタックスは、'CustID' が予測変数のリストから除外する 'IDVar' であることを示します。また、この例では実演していませんが、creditscorecard を使って creditscorecard オブジェクトを作成するとき、オプションの name-value ペアの引数 'WeightsVar' を使って観測(サンプル)重みを指定することや、 'BinMissingData' を指定して欠損データのビン化をすることができます。
load CreditCardData
head(data)
| CustID | CustAge | TmAtAddress | ResStatus | EmpStatus | CustIncome | TmWBank | OtherCC | AMBalance | UtilRate | status | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 53 | 62 | Tenant | Unknown | 50000 | 55 | Yes | 1.0559e+03 | 0.2200 | 0 |
| 2 | 2 | 61 | 22 | Home Owner | Employed | 52000 | 25 | Yes | 1.1616e+03 | 0.2400 | 0 |
| 3 | 3 | 47 | 30 | Tenant | Employed | 37000 | 61 | No | 877.2300 | 0.2900 | 0 |
| 4 | 4 | 50 | 75 | Home Owner | Employed | 53000 | 20 | Yes | 157.3700 | 0.0800 | 0 |
| 5 | 5 | 68 | 56 | Home Owner | Employed | 53000 | 14 | Yes | 561.8400 | 0.1100 | 0 |
| 6 | 6 | 65 | 13 | Home Owner | Employed | 48000 | 59 | Yes | 968.1800 | 0.1500 | 0 |
| 7 | 7 | 34 | 32 | Home Owner | Unknown | 32000 | 26 | Yes | 717.8200 | 0.0200 | 1 |
| 8 | 8 | 50 | 57 | Other | Employed | 51000 | 33 | No | 3.0412e+03 | 0.1300 | 0 |
CreditCardData の変数は、顧客 ID、顧客年齢、現住所での居住歴、居住形態、雇用形態、顧客所得、銀行の利用歴 (Time with Bank)、他のクレジットカードの有無、月平均残高 (Average Monthly Balance)、利用率、デフォルト状態 (応答) です。
sc = creditscorecard(data,'IDVar','CustID')
sc =
creditscorecard のプロパティ:
GoodLabel: 0
ResponseVar: 'status'
WeightsVar: ''
VarNames: {'CustID' 'CustAge' 'TmAtAddress' 'ResStatus' 'EmpStatus' 'CustIncome' 'TmWBank' 'OtherCC' 'AMBalance' 'UtilRate' 'status'}
NumericPredictors: {'CustAge' 'TmAtAddress' 'CustIncome' 'TmWBank' 'AMBalance' 'UtilRate'}
CategoricalPredictors: {'ResStatus' 'EmpStatus' 'OtherCC'}
BinMissingData: 0
IDVar: 'CustID'
PredictorVars: {'CustAge' 'TmAtAddress' 'ResStatus' 'EmpStatus' 'CustIncome' 'TmWBank' 'OtherCC' 'AMBalance' 'UtilRate'}
Data: [1200x11 table]
最初のデータ探索を行います。カテゴリ変数 'ResStatus' の予測統計量について調べ、'ResStatus' でビン情報をプロットします。
bininfo(sc,'ResStatus')
| Bin | Good | Bad | Odds | WOE | InfoValue | |
|---|---|---|---|---|---|---|
| 1 | 'Home Owner' | 365 | 177 | 2.0621 | 0.0193 | 0.0002 |
| 2 | 'Tenant' | 307 | 167 | 1.8383 | -0.0956 | 0.0037 |
| 3 | 'Other' | 131 | 53 | 2.4717 | 0.2005 | 0.0059 |
| 4 | 'Totals' | 803 | 397 | 2.0227 | NaN | 0.0098 |
plotbins(sc,'ResStatus')
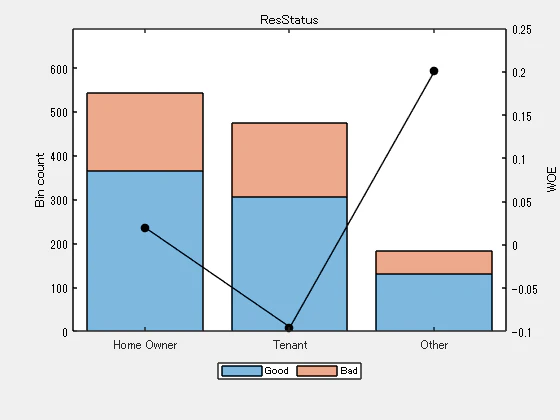
このビン情報には、"Good "と "Bad "の頻度、およびビンの統計量が含まれます。頻度が 0 のビンは、無限または未定義 (NaN) の統計量につながるため避けます。modibins 関数や autobinning 関数を用いて、適宜ビンを作成します。
数値データの場合、一般的な最初のステップは "細かなクラス分け " です。これはデータをいくつかのビンに分け、規則的なグリッドで定義することを意味します。これを説明するために、予測変数 'CustIncome' を使用します。
cp = 20000:5000:60000;
sc = modifybins(sc,'CustIncome','CutPoints',cp);
bininfo(sc,'CustIncome')
| Bin | Good | Bad | Odds | WOE | InfoValue | |
|---|---|---|---|---|---|---|
| 1 | '[-Inf,20000)' | 3 | 5 | 0.6000 | -1.2152 | 0.0108 |
| 2 | '[20000,25000)' | 23 | 16 | 1.4375 | -0.3415 | 0.0040 |
| 3 | '[25000,30000)' | 38 | 47 | 0.8085 | -0.9170 | 0.0652 |
| 4 | '[30000,35000)' | 131 | 75 | 1.7467 | -0.1467 | 0.0038 |
| 5 | '[35000,40000)' | 193 | 98 | 1.9694 | -0.0267 | 0.0002 |
| 6 | '[40000,45000)' | 173 | 76 | 2.2763 | 0.1181 | 0.0028 |
| 7 | '[45000,50000)' | 131 | 47 | 2.7872 | 0.3206 | 0.0143 |
| 8 | '[50000,55000)' | 82 | 24 | 3.4167 | 0.5242 | 0.0218 |
| 9 | '[55000,60000)' | 21 | 8 | 2.6250 | 0.2607 | 0.0016 |
| 10 | '[60000,Inf]' | 8 | 1 | 8 | 1.3750 | 0.0102 |
| 11 | 'Totals' | 803 | 397 | 2.0227 | NaN | 0.1347 |
plotbins(sc,'CustIncome')
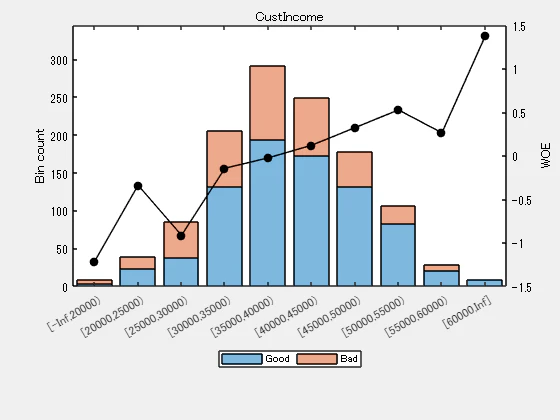
Step 2a. データを自動的にビン化
autobinning 関数を使用して、すべての予測変数について、デフォルトの 'Monotone' アルゴリズムをデフォルトのアルゴリズムオプションを使って、自動ビン化を実行します。
sc = autobinning(sc);
自動ビン化ステップの後,すべての予測変数のビンは,bininfo 関数と plotbins 関数を使用してレビューされ,微調整される必要があります。単調な、理想的には線形トレンドの Weight of Evidence (WOE) は、与えられた予測変数に対して線形なポイントに変換されるため,信用スコアカードには望ましいものです。WOEのトレンドは,plotbins を使用して可視化することができるます。
Predictor = 'TmWBank';
plotbins(sc,Predictor)
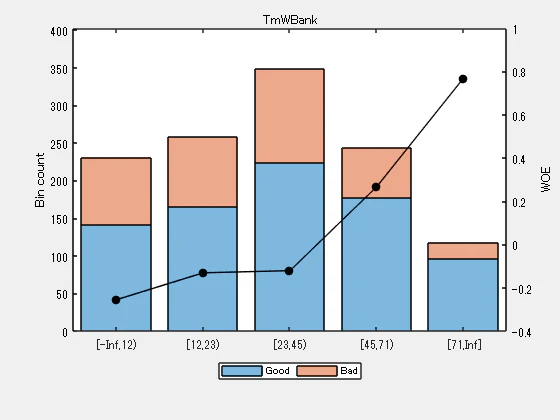
'ResStatus' の初期プロットとは異なり、スコアカード作成時の 'ResStatus' の新しいプロットは、増加する WOE トレンドを示しています。これは、 autobinning 関数がデフォルトでオッズの増加する順序でカテゴリをソートするためです。
これらのプロットは、’Monotone’ アルゴリズムがこのデータセットの単調な WOE トレンドを見つけるのに上手く機能することを示しています。ビンニングプロセスを完了するために、いくつかの予測変数については modifybins 関数を用いて、手動でいくらか調整する必要があります。
Step 2b. 手動ビニングでビンを微調整
ビンを手動で修正する一般的な手順は以下の通りです:
- 2つの出力引数(2番目の引数にはビニングルールが含まれる)を持つ
bininfo関数を使用する -
bininfoの2番目の出力引数を用いてビニングルールを手動で修正する - 更新されたビニングルールを
modifybinsで設定し、plotbinsまたはbininfoで更新されたビンを確認する
例えば、Step 2a. の 'CustAge' のプロットによると、ビン番号1と2は、ビン番号5と6と同様に WOE が似ていることがわかります。上記の手順を使用してこれらのビンをマージするには、以下の手順に従います:
Predictor = 'CustAge';
[~,cp] = bininfo(sc,Predictor)
| Bin | Good | Bad | Odds | WOE | InfoValue | |
|---|---|---|---|---|---|---|
| 1 | '[-Inf,33)' | 70 | 53 | 1.3208 | -0.4262 | 0.0197 |
| 2 | '[33,37)' | 64 | 47 | 1.3617 | -0.3957 | 0.0153 |
| 3 | '[37,40)' | 73 | 47 | 1.5532 | -0.2641 | 0.0073 |
| 4 | '[40,46)' | 174 | 94 | 1.8511 | -0.0887 | 0.0018 |
| 5 | '[46,48)' | 61 | 25 | 2.4400 | 0.1876 | 0.0024 |
| 6 | '[48,58)' | 263 | 105 | 2.5048 | 0.2138 | 0.0135 |
| 7 | '[58,Inf]' | 98 | 26 | 3.7692 | 0.6225 | 0.0352 |
| 8 | 'Totals' | 803 | 397 | 2.0227 | NaN | 0.0952 |
cp = 6x1
33
37
40
46
48
58
cp([1 5]) = []; % To merge bins 1 and 2, and bins 5 and 6
sc = modifybins(sc,'CustAge','CutPoints',cp);
plotbins(sc,'CustAge')
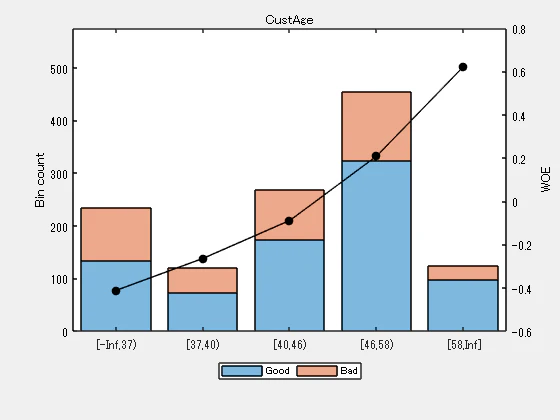
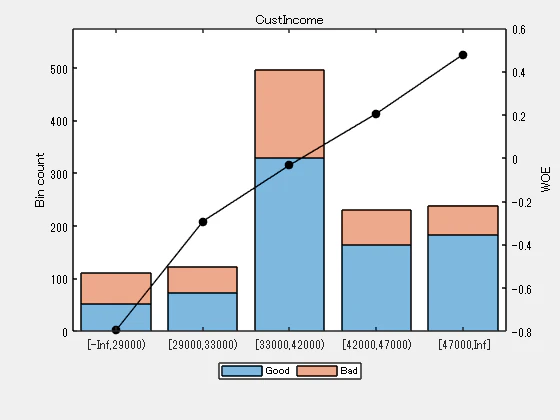
‘CustIncome’ については、上記のプロットによると、ビン3、4、5が似た WOE を持つため、マージすることが最善です。これらのビンをマージするには:
Predictor = 'CustIncome';
[~,cp] = bininfo(sc,Predictor)
| Bin | Good | Bad | Odds | WOE | InfoValue | |
|---|---|---|---|---|---|---|
| 1 | '[-Inf,29000)' | 53 | 58 | 0.9138 | -0.7946 | 0.0636 |
| 2 | '[29000,33000)' | 74 | 49 | 1.5102 | -0.2922 | 0.0091 |
| 3 | '[33000,35000)' | 68 | 36 | 1.8889 | -0.0684 | 0.0004 |
| 4 | '[35000,40000)' | 193 | 98 | 1.9694 | -0.0267 | 0.0002 |
| 5 | '[40000,42000)' | 68 | 34 | 2 | -0.0113 | 0 |
| 6 | '[42000,47000)' | 164 | 66 | 2.4848 | 0.2058 | 0.0078 |
| 7 | '[47000,Inf]' | 183 | 56 | 3.2679 | 0.4797 | 0.0417 |
| 8 | 'Totals' | 803 | 397 | 2.0227 | NaN | 0.1228 |
cp = 6x1
29000
33000
35000
40000
42000
47000
cp([3 4]) = []; % To merge bins 3, 4, and 5
sc = modifybins(sc,'CustIncome','CutPoints',cp);
plotbins(sc,'CustIncome')
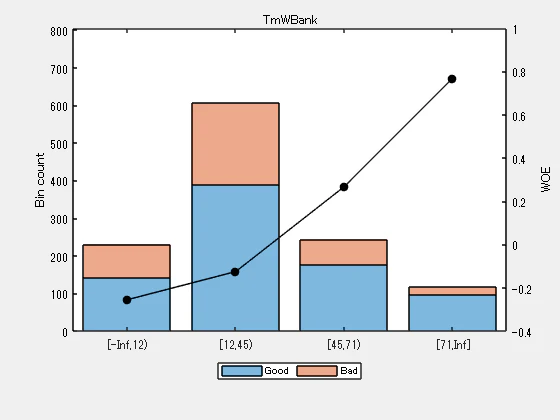
‘TmWBank’ については、上記のプロットによると、ビン2と3は似た WOE を持つため、マージすることが最善です。これらのビンをマージするには:
Predictor = 'TmWBank';
[~,cp] = bininfo(sc,Predictor)
| Bin | Good | Bad | Odds | WOE | InfoValue | |
|---|---|---|---|---|---|---|
| 1 | '[-Inf,12)' | 141 | 90 | 1.5667 | -0.2555 | 0.0131 |
| 2 | '[12,23)' | 165 | 93 | 1.7742 | -0.1311 | 0.0038 |
| 3 | '[23,45)' | 224 | 125 | 1.7920 | -0.1211 | 0.0043 |
| 4 | '[45,71)' | 177 | 67 | 2.6418 | 0.2670 | 0.0138 |
| 5 | '[71,Inf]' | 96 | 22 | 4.3636 | 0.7689 | 0.0493 |
| 6 | 'Totals' | 803 | 397 | 2.0227 | NaN | 0.0843 |
cp = 4x1
12
23
45
71
cp(2) = []; % To merge bins 2 and 3
sc = modifybins(sc,'TmWBank','CutPoints',cp);
plotbins(sc,'TmWBank')
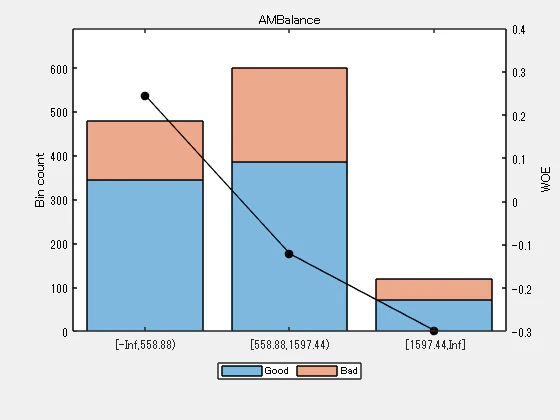
‘AMBalance’ については、上記のプロットによると、ビン2と3は似た WOE を持つため、マージすることが最善です。これらのビンをマージするには:
Predictor = 'AMBalance';
[bi,cp] = bininfo(sc,Predictor)
| Bin | Good | Bad | Odds | WOE | InfoValue | |
|---|---|---|---|---|---|---|
| 1 | '[-Inf,558.88)' | 346 | 134 | 2.5821 | 0.2442 | 0.0228 |
| 2 | '[558.88,1254.28)' | 309 | 171 | 1.8070 | -0.1127 | 0.0052 |
| 3 | '[1254.28,1597.44)' | 76 | 44 | 1.7273 | -0.1579 | 0.0026 |
| 4 | '[1597.44,Inf]' | 72 | 48 | 1.5000 | -0.2990 | 0.0093 |
| 5 | 'Totals' | 803 | 397 | 2.0227 | NaN | 0.0399 |
cp = 3x1
1.0e+03 *
0.5589
1.2543
1.5974
cp(2) = []; % To merge bins 2 and 3
sc = modifybins(sc,'AMBalance','CutPoints',cp);
plotbins(sc,'AMBalance')
ビニングの微調整が完了したので、すべての予測変数のビンは、ほぼ直線的なWOEトレンドを持ちます。
Step 3. ロジスティック回帰モデルのフィッティング
fitmodel 関数は、WOE データにロジスティック回帰モデルをあてはめます。fitmodel は、内部で学習データをビン分割し、WOE 値に変換し、応答変数を 'Good' が1になるようにマップし、線形ロジスティック回帰モデルをあてはめます。デフォルトでは、fitmodel はステップワイズの手順を用いて、モデルに含まれるべき予測変数を決定します。
sc = fitmodel(sc);
1。CustIncome, Deviance = 1490.8954, Chi2Stat = 32.545914, PValue = 1.1640961e-08 を追加中
2。TmWBank, Deviance = 1467.3249, Chi2Stat = 23.570535, PValue = 1.2041739e-06 を追加中
3。AMBalance, Deviance = 1455.858, Chi2Stat = 11.466846, PValue = 0.00070848829 を追加中
4。EmpStatus, Deviance = 1447.6148, Chi2Stat = 8.2432677, PValue = 0.0040903428 を追加中
5。CustAge, Deviance = 1442.06, Chi2Stat = 5.5547849, PValue = 0.018430237 を追加中
6。ResStatus, Deviance = 1437.9435, Chi2Stat = 4.1164321, PValue = 0.042468555 を追加中
7。OtherCC, Deviance = 1433.7372, Chi2Stat = 4.2063597, PValue = 0.040272676 を追加中
一般化線形回帰モデル:
logit(status) ~ 1 + CustAge + ResStatus + EmpStatus + CustIncome + TmWBank + OtherCC + AMBalance
分布は Binomial です
推定された係数:
Estimate SE tStat pValue
________ _______ ______ __________
(Intercept) 0.7024 0.064 10.975 5.0407e-28
CustAge 0.61562 0.24783 2.4841 0.012988
ResStatus 1.3776 0.65266 2.1107 0.034799
EmpStatus 0.88592 0.29296 3.024 0.0024946
CustIncome 0.69836 0.21715 3.216 0.0013001
TmWBank 1.106 0.23266 4.7538 1.9958e-06
OtherCC 1.0933 0.52911 2.0662 0.038806
AMBalance 1.0437 0.32292 3.2322 0.0012285
1200 の観測値、1192 の誤差の自由度
分散: 1
カイ 2 乗統計量 - 定数モデルとの比較: 89.7、p 値は 1.42e-16 です
Step 4. スコアカードポイントのレビューとフォーマット
ロジスティックモデルのフィット後、デフォルトではポイントはスケーリングされず、WOE 値とモデル係数の組み合わせから直接算出されます。displaypoints 関数は、スコアカードのポイントを要約します。
p1 = displaypoints(sc);
disp(p1)
Predictors Bin Points
______________ ____________________ _________
{'CustAge' } {'[-Inf,37)' } -0.15314
{'CustAge' } {'[37,40)' } -0.062247
{'CustAge' } {'[40,46)' } 0.045763
{'CustAge' } {'[46,58)' } 0.22888
{'CustAge' } {'[58,Inf]' } 0.48354
{'CustAge' } {'<missing>' } NaN
{'ResStatus' } {'Tenant' } -0.031302
{'ResStatus' } {'Home Owner' } 0.12697
{'ResStatus' } {'Other' } 0.37652
{'ResStatus' } {'<missing>' } NaN
{'EmpStatus' } {'Unknown' } -0.076369
{'EmpStatus' } {'Employed' } 0.31456
{'EmpStatus' } {'<missing>' } NaN
{'CustIncome'} {'[-Inf,29000)' } -0.45455
{'CustIncome'} {'[29000,33000)' } -0.1037
{'CustIncome'} {'[33000,42000)' } 0.077768
{'CustIncome'} {'[42000,47000)' } 0.24406
{'CustIncome'} {'[47000,Inf]' } 0.43536
{'CustIncome'} {'<missing>' } NaN
{'TmWBank' } {'[-Inf,12)' } -0.18221
{'TmWBank' } {'[12,45)' } -0.038279
{'TmWBank' } {'[45,71)' } 0.39569
{'TmWBank' } {'[71,Inf]' } 0.95074
{'TmWBank' } {'<missing>' } NaN
{'OtherCC' } {'No' } -0.193
{'OtherCC' } {'Yes' } 0.15868
{'OtherCC' } {'<missing>' } NaN
{'AMBalance' } {'[-Inf,558.88)' } 0.3552
{'AMBalance' } {'[558.88,1597.44)'} -0.026797
{'AMBalance' } {'[1597.44,Inf]' } -0.21168
{'AMBalance' } {'<missing>' } NaN
見た目の理由から、ビンのラベルを修正することに興味があれば、これはいい機会です。ビンのラベルを変更するために modifybins を使用します。
sc = modifybins(sc,'CustAge','BinLabels',...
{'Up to 36' '37 to 39' '40 to 45' '46 to 57' '58 and up'});
sc = modifybins(sc,'CustIncome','BinLabels',...
{'Up to 28999' '29000 to 32999' '33000 to 41999' '42000 to 46999' '47000 and up'});
sc = modifybins(sc,'TmWBank','BinLabels',...
{'Up to 11' '12 to 44' '45 to 70' '71 and up'});
sc = modifybins(sc,'AMBalance','BinLabels',...
{'Up to 558.87' '558.88 to 1597.43' '1597.44 and up'});
p1 = displaypoints(sc);
disp(p1)
Predictors Bin Points
______________ _____________________ _________
{'CustAge' } {'Up to 36' } -0.15314
{'CustAge' } {'37 to 39' } -0.062247
{'CustAge' } {'40 to 45' } 0.045763
{'CustAge' } {'46 to 57' } 0.22888
{'CustAge' } {'58 and up' } 0.48354
{'CustAge' } {'<missing>' } NaN
{'ResStatus' } {'Tenant' } -0.031302
{'ResStatus' } {'Home Owner' } 0.12697
{'ResStatus' } {'Other' } 0.37652
{'ResStatus' } {'<missing>' } NaN
{'EmpStatus' } {'Unknown' } -0.076369
{'EmpStatus' } {'Employed' } 0.31456
{'EmpStatus' } {'<missing>' } NaN
{'CustIncome'} {'Up to 28999' } -0.45455
{'CustIncome'} {'29000 to 32999' } -0.1037
{'CustIncome'} {'33000 to 41999' } 0.077768
{'CustIncome'} {'42000 to 46999' } 0.24406
{'CustIncome'} {'47000 and up' } 0.43536
{'CustIncome'} {'<missing>' } NaN
{'TmWBank' } {'Up to 11' } -0.18221
{'TmWBank' } {'12 to 44' } -0.038279
{'TmWBank' } {'45 to 70' } 0.39569
{'TmWBank' } {'71 and up' } 0.95074
{'TmWBank' } {'<missing>' } NaN
{'OtherCC' } {'No' } -0.193
{'OtherCC' } {'Yes' } 0.15868
{'OtherCC' } {'<missing>' } NaN
{'AMBalance' } {'Up to 558.87' } 0.3552
{'AMBalance' } {'558.88 to 1597.43'} -0.026797
{'AMBalance' } {'1597.44 and up' } -0.21168
{'AMBalance' } {'<missing>' } NaN
ポイントは通常、スケールされ、またしばしば丸められます。これを行うには、formatpoints 関数を使用します。例えば、目標とするオッズ水準に対応する目標ポイント水準を設定し、また要求される PDO (points-to-double-the-odds) を設定することができます。
TargetPoints = 500;
TargetOdds = 2;
PDO = 50; % Points to double the odds
sc = formatpoints(sc,'PointsOddsAndPDO',[TargetPoints TargetOdds PDO]);
p2 = displaypoints(sc);
disp(p2)
Predictors Bin Points
______________ _____________________ ______
{'CustAge' } {'Up to 36' } 53.239
{'CustAge' } {'37 to 39' } 59.796
{'CustAge' } {'40 to 45' } 67.587
{'CustAge' } {'46 to 57' } 80.796
{'CustAge' } {'58 and up' } 99.166
{'CustAge' } {'<missing>' } NaN
{'ResStatus' } {'Tenant' } 62.028
{'ResStatus' } {'Home Owner' } 73.445
{'ResStatus' } {'Other' } 91.446
{'ResStatus' } {'<missing>' } NaN
{'EmpStatus' } {'Unknown' } 58.777
{'EmpStatus' } {'Employed' } 86.976
{'EmpStatus' } {'<missing>' } NaN
{'CustIncome'} {'Up to 28999' } 31.497
{'CustIncome'} {'29000 to 32999' } 56.805
{'CustIncome'} {'33000 to 41999' } 69.896
{'CustIncome'} {'42000 to 46999' } 81.891
{'CustIncome'} {'47000 and up' } 95.69
{'CustIncome'} {'<missing>' } NaN
{'TmWBank' } {'Up to 11' } 51.142
{'TmWBank' } {'12 to 44' } 61.524
{'TmWBank' } {'45 to 70' } 92.829
{'TmWBank' } {'71 and up' } 132.87
{'TmWBank' } {'<missing>' } NaN
{'OtherCC' } {'No' } 50.364
{'OtherCC' } {'Yes' } 75.732
{'OtherCC' } {'<missing>' } NaN
{'AMBalance' } {'Up to 558.87' } 89.908
{'AMBalance' } {'558.88 to 1597.43'} 62.353
{'AMBalance' } {'1597.44 and up' } 49.016
{'AMBalance' } {'<missing>' } NaN
Step 5. データにスコアを付ける
score 関数は、学習データに対するスコアを計算します。検証データの様なオプションのデータ入力も、スコアリングのために渡すことができます。各顧客の予測変数ごとのポイントは、オプションの出力として提供されます。
[Scores,Points] = score(sc);
disp(Scores(1:10))
528.2044
554.8861
505.2406
564.0717
554.8861
586.1904
441.8755
515.8125
524.4553
508.3169
disp(Points(1:10,:))
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
80.796 62.028 58.777 95.69 92.829 75.732 62.353
99.166 73.445 86.976 95.69 61.524 75.732 62.353
80.796 62.028 86.976 69.896 92.829 50.364 62.353
80.796 73.445 86.976 95.69 61.524 75.732 89.908
99.166 73.445 86.976 95.69 61.524 75.732 62.353
99.166 73.445 86.976 95.69 92.829 75.732 62.353
53.239 73.445 58.777 56.805 61.524 75.732 62.353
80.796 91.446 86.976 95.69 61.524 50.364 49.016
80.796 62.028 58.777 95.69 61.524 75.732 89.908
80.796 73.445 58.777 95.69 61.524 75.732 62.353
Step 6. デフォルト確率を計算する
デフォルトの確率を計算するには、probdefault 関数を使用します。
pd = probdefault(sc);
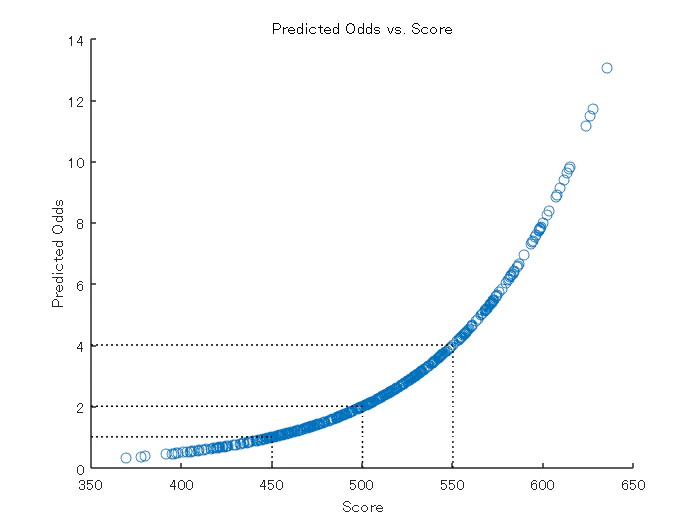
"Good” である確率を定義し、予測オッズをフォーマットされたスコアに対してプロットします。目標ポイントと目標オッズが一致し、PDO (points-to-double-the odds) の関係が成立していることを視覚的に分析します。
ProbGood = 1-pd;
PredictedOdds = ProbGood./pd;
figure
scatter(Scores,PredictedOdds)
title('Predicted Odds vs. Score')
xlabel('Score')
ylabel('Predicted Odds')
hold on
xLimits = xlim;
yLimits = ylim;
% Target points and odds
plot([TargetPoints TargetPoints],[yLimits(1) TargetOdds],'k:')
plot([xLimits(1) TargetPoints],[TargetOdds TargetOdds],'k:')
% Target points plus PDO
plot([TargetPoints+PDO TargetPoints+PDO],[yLimits(1) 2*TargetOdds],'k:')
plot([xLimits(1) TargetPoints+PDO],[2*TargetOdds 2*TargetOdds],'k:')
% Target points minus PDO
plot([TargetPoints-PDO TargetPoints-PDO],[yLimits(1) TargetOdds/2],'k:')
plot([xLimits(1) TargetPoints-PDO],[TargetOdds/2 TargetOdds/2],'k:')
hold off
Step 7. CAP, ROC, KS 統計量を用いた信用スコアカードモデルの検証
creditscorecard クラスは、累積精度プロファイル (CAP), 受信者操作特性 (ROC), Kolmogorov-Smirnov 統計量 (KS) の3つの検証手法をサポートしています。CAP, ROC, KS の詳細については,Cumulative Accuracy Profile (CAP), Receiver Operating Characteristic (ROC), そして Kolmogorov-Smirnov statistic (KS) を参照します。
[Stats,T] = validatemodel(sc,'Plot',{'CAP','ROC','KS'});
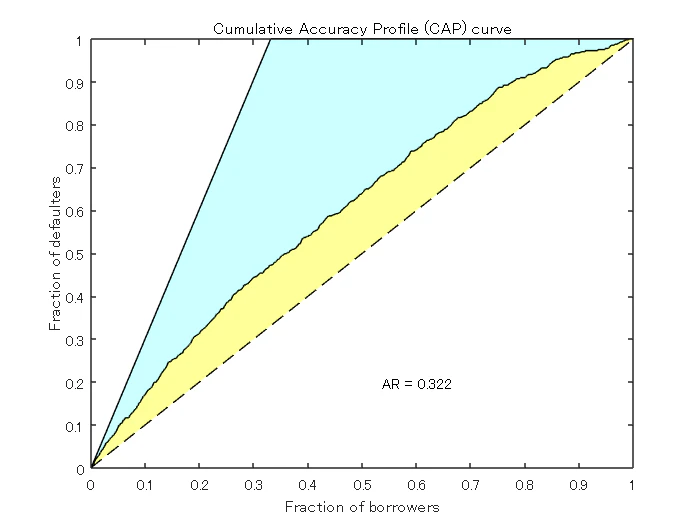
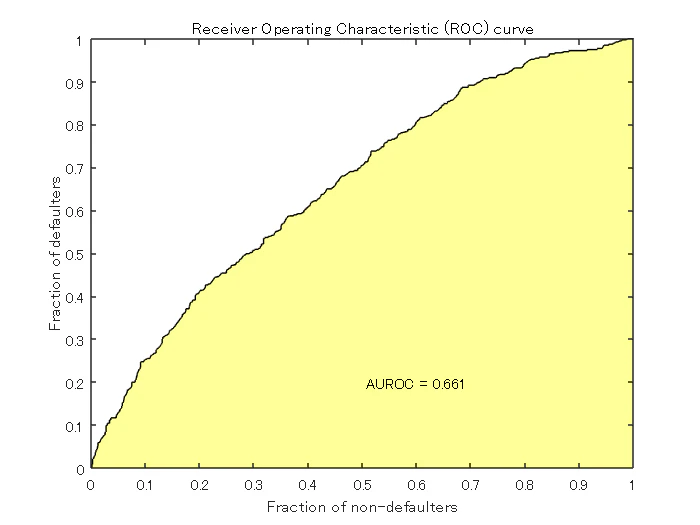
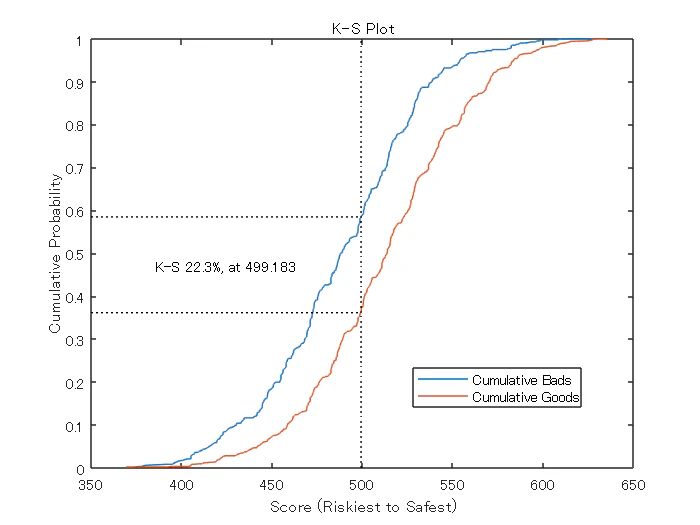
disp(Stats)
Measure Value
________________________ _______
{'Accuracy Ratio' } 0.32225
{'Area under ROC curve'} 0.66113
{'KS statistic' } 0.22324
{'KS score' } 499.18
disp(T(1:15,:))
Scores ProbDefault TrueBads FalseBads TrueGoods FalseGoods Sensitivity FalseAlarm PctObs
______ ___________ ________ _________ _________ __________ ___________ __________ __________
369.4 0.7535 0 1 802 397 0 0.0012453 0.00083333
377.86 0.73107 1 1 802 396 0.0025189 0.0012453 0.0016667
379.78 0.7258 2 1 802 395 0.0050378 0.0012453 0.0025
391.81 0.69139 3 1 802 394 0.0075567 0.0012453 0.0033333
394.77 0.68259 3 2 801 394 0.0075567 0.0024907 0.0041667
395.78 0.67954 4 2 801 393 0.010076 0.0024907 0.005
396.95 0.67598 5 2 801 392 0.012594 0.0024907 0.0058333
398.37 0.67167 6 2 801 391 0.015113 0.0024907 0.0066667
401.26 0.66276 7 2 801 390 0.017632 0.0024907 0.0075
403.23 0.65664 8 2 801 389 0.020151 0.0024907 0.0083333
405.09 0.65081 8 3 800 389 0.020151 0.003736 0.0091667
405.15 0.65062 11 5 798 386 0.027708 0.0062267 0.013333
405.37 0.64991 11 6 797 386 0.027708 0.007472 0.014167
406.18 0.64735 12 6 797 385 0.030227 0.007472 0.015
407.14 0.64433 13 6 797 384 0.032746 0.007472 0.015833
Copyright 2022 The MathWorks, Inc.