この記事ははんなりPython Advent Calendar 2020 - Qiitaの24日目の記事です。
前日は、@masayuki14さんの「Kaggleを始めたので1年後にはコンペに出れるようにぼちぼちやっていこう」でした。
はじめまして、@HW_a_pythonistaという、Twiter idで活動している、わたなべです。
私は、はんなりPythonの常連で、Pythonとベイズ統計に関して、12月のはんなりPythonのLT会で発表しましたので、どのような発表をしたかについて、このページにまとめたいと思います。
(上記の発表は、Pycon mini Hiroshima2020で発表した内容を縮小して、一部の情報のアップデートを含めたものです。)
ベイズ統計って、どんなもの?
ベイズ統計というのは、観測を行う前に持っている、自分の事前確率(予想確率)から、実際に得た観測データを情報を反映させて、その時点での最もマシな推測を行う統計学の方法です。機械学習の方法にも、ベイズ統計・ベイズモデリングは、統計学でよく使われているパラメータの少ないモデルと多数のハイパーパラメータを含むそのチューニングを必要とする機械学習モデルのある種、中間的なものと考えてもらってよいかもしれません。(雑な言い方で、語弊もあるかと思いますが)
なぜ、ベイズなのか?
なぜ、ベイズかを説明するにあたって、まず、最近のAIやPythonを取り巻く状況について振り返ってみたいと思います。近年のAI・機械学習ブームは、大量のデータを使ったディープニューラルネットワークなどに代表される方法に牽引されてきました。ここで、注目され一気に人気となったのが、Pythonです。TensorFlow、Chainer、PyTorch、Theano、MXnetといったディープラーニングのライブラリについて、軒並みPythonからの使用が、推奨されていたため、Pythonが一躍脚光を浴びました。また、Scikit-LearnやNumpyなどディープラーニングに限らない機械学習のライブラリや、その基盤となる数値計算のライブラリが充実していることも、人気を支えるものでした。最近では、AutoTunerと呼ばれる自動的にパラメータチューニングなどが発展してきていますし、PyconJP2020でもMLOpsや、機械学習のWebアプリの応答速度などについて、発表がなされていました。今後、データサイエンティストや、機械学習エンジニアは、これらの問題だけ考えていればよいのでしょうか?
機械学習を現場で使用する際の問題点
-
解釈性 ショッピングサイトなどのWebシステムでは、Webシステム自身が自動で応答が返します。したがって、解釈がしづらいモデルでも、性能が良いモデルを採用しておけば事足ります。しかし、それ以外の実応用となれば、運用時にシステムの中に必ず人が関わります。その場合、単にブラックボックスとしての学習モデルが今までより良い性能をだしていたからというだけでは、人が動いてくれないということは、容易に起こり得ます。
-
データの量 正解ラベル付きのデータは、ショッピングサイトなどでは、多くの購買データやどのサイトに訪れ、その後、どのサイトに履歴のデータが大量に得ることが可能です。しかしながら現実には、そういった大量のラベル付きデータが得られる問題は、案外多くないのではないでしょうか?そのような場合、内部パラメータを多数持つ機械学習の方法は、パラメータ決めることが困難になりますし、パラメータを決定しても、過学習や、より単純なモデルとの性能差を出すことは、難しくなります。
-
学習モデルへデータに含まれるノイズの性質の反映が可能 データが物理的な測定器に由来する場合には、当然、その測定器の誤差が含まれます。回帰を行う場合には、ガウス分布が仮定しますが、これは、必ずしも測定器の性質を表しているわけではありません。
-
(クロスバリデーションなどで捉えられない)真の汎化性能 通常の機械学習では、クロスバリデーションなどの手法を用いて、学習モデルの性能を測り、最適なモデルを考えます。しかしながら実応用の場合、単純にランダムにクロスバリデーションを行っただけでは、よいモデルが、得られることがあります。これは、データ点の数が極端に少ない場合や、学習に使ったデータ点と、テストに使ったデータ点、さらに実運用時に得られるデータ点の距離が大きく離れていたり、異なるクラスタに属する場合に起こり得ます。
ベイズ統計・ベイズモデリングの意義
こういった問題に対応する一つの手段として、ベイズ統計やベイズモデリングの使用が挙げられます。ベイズ統計では、 誤差の情報を分布として取り扱うことが可能ですし、階層モデルを導入するなどデータの背後にある関係を丁寧にモデルの取り込むことで、データ量の少なさや偏りに対応が可能です。
Pythonで使えるベイズ統計のライブラリの紹介
既に使用実績の多いもの

-
PyMC3
PyMCは名前の通り、PythonからMC(モンテカルロ計算)を行うライブラリの第3段で、自動微分を得意とするライブラリTheanoをバックエンドとして開発されました。公式サイトにも多数のサンプルコードが紹介されていますし、多くの書籍が出版されていますので学習が比較的容易です。また、Google colabratoryからも使えますし、condaやpipを使って容易にインストールが可能です。 -
PyStan
ベイズモデリングを行う際に使われる代表的なソフトであるStanのPythonラッパーです。
Stanは、独自のStan言語を用いて、モデルを記述しますが、数式の対応が付けやすい文法になっています。PyStanに関する書籍は少ないですが、RStanに関する本は、数多く出版されていますので、データ読み込みと前処理の部分を作れば、同じStanコードで動作をさせることでき、学習が可能です。
今後の注目株
今後、Pythonから使えるベイズ統計のライブラリを書きたいと思います。ここに挙げるものはある程度、計算規模の大きい学習モデルを取り扱うことが期待されています。(GPUによる高速化も期待されていると思います。)
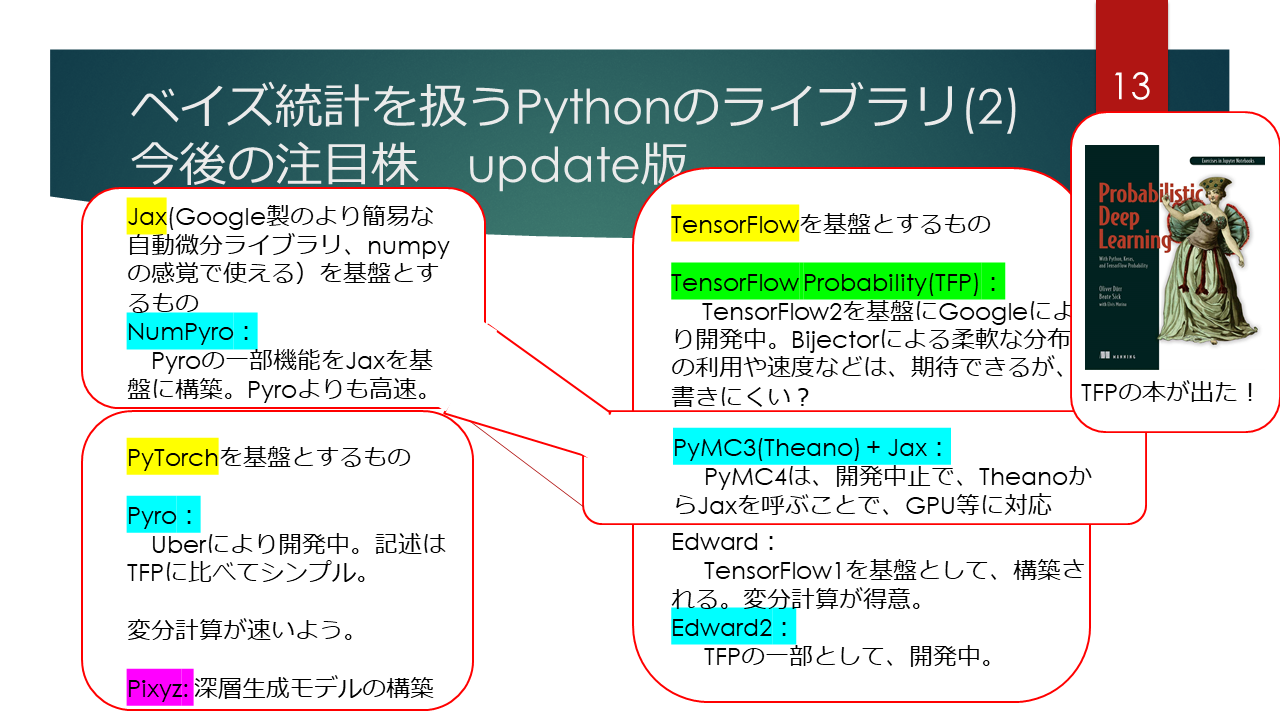
-
Jaxを基盤としたもの
Jaxというのは、比較的最近でてきたGoogle製の自動微分のライブラリです。TensorFlowやPyTorchよりも、後発な分、Numpy感覚で使えるという手軽さが売りで、普及が進んでいます。、そのJaxを基盤としたNumpyroが挙げられます。変分計算?が速い、また、PyMC4が、後述のTensorFlow Probabilityを基盤として開発されてきましたが、それに代わって、PyMC3のバックエンドとして、Theanoを介して、Jaxを使うという方向に開発が変更されました。既に、PyMC3で書かれたコード資産がそのまま活かされることが期待できます。 -
PyTorchを基盤としたもの
PyTorchは、ディープラーニングなどを、比較的早い段階(Chainerよりは後発ですが)でdefine by runを取り入れたことにより、特に学術系では、TensorFlowを超える採用数となっています。PyTorchを基盤としたライブラリとして、Pyroがあります。Pyroの開発元は、あのUberの研究部門であり、企業のリソースが投入されたライブラリということで、その信頼性が期待がされています。 -
TensorFlow及びTensorFlow Probabilityを基盤にしたもの
TensorFlowは、Google開発のテンソル計算のライブラリであり、ディープラーニングのフレームワークとして、Caffe、 Theanoなどを抑え、最も普及が進みました。上述のように、最近では、PyTorchに追いつかれているところもありますが、現在運用されている機械学習を含んだ商用システムでは、使用されてている数は未だに多い(最多?)のではないでしょうか。TensorFlow Probabilityは、そのTensorFlowを基盤にした、確率的プログラミングのライブラリです。TensorFlowを基盤とした、確率プログラミングのライブラリということで、主に高速性や、細かなカスタマイズが売りと思われますが、他のライブラリに比べて、若干コードが書きにくいという面がある思います。
ただし、"Probabilistic Deep Learning: With Python, Keras and TensorFlow Probability"という英語の書籍が発売されましたので、こちらを足場に、ディープラーニング+ベイズのような課題に取り組んでみるのは、手ではないかと思います。
PyMC3を用いたベイズモデリングを行うときの例
外れ値を含む場合の線形回帰によるモデリングの例と、いくつかの集団の対する階層モデルを導入した線形回帰の例を紹介しました。前者は、データ点の誤差に関する知識を丁寧に反映された例ということができますし、後者は、一つの集団に対するデータが少ない場合にも、他の集団のデータの情報を取り入れて、適切に学習モデルを構築をする例となっています。
まとめ
2020年12月のはんなりPythonのLT会で、「Pythonとベイズ統計」についてのLTを行いました。Pythonには、ベイズ統計を扱うライブラリが多数存在しています。ベイズ統計・ベイズモデリングを行うことで、通常の機械学習に比べて小回りを利かせ、かゆいところに手が届く解決策を得ることが可能です。みなさんに積極的に使っていきましょう。