音声合成とは
今回は僕が初めて勉強する領域である「テキスト音声合成(Text-to-speech synthesis : TSS)」について、まとめます!
初めての領域なので、誤りなどがございましたらコメントいただけると幸いです。
身近で使用されている音声合成技術
自動車のカーナビ、駅などの自動アナウンス、スマートスピーカー、電話などでの自動音声ガイダンスなど、TSS は僕らの生活のほぼ一部として使用されています。
音声合成の大まかな歴史
- 隠れマルコフモデル(Hidden Mar-kov model: HMM)に基づく統計的音声合成
2012 年ごろまで主流だった技術で、こちらを用いて合成された音声は、話している内容は問題なく聞き取れるようです。しかし、人間の話す音声と比較すると、自然には聞こえず、機械が話しているようなもので大きな課題を持っていました。
- Deep neural network: DNN の登場
今の AI ブームが始まった頃、音声合成についても DNN が使用されることによって、上記の HMM を上回る精度を出すことができるようになりました。
- WaveNet の登場
2016 年、Google DeepMind が発表した音声波形生成ニューラルネットモデル(WaveNet)、2017 年に提案された Tacotron2 により、TSS で自然な音声を生成することができるようになりました。
現在では、CPU だけでも高品質でリアルタイムに音声合成生成を行うことができるそうです。
(すごい)
TSS での音声波形生成問題の難しさ
従来の TSS
入力テキストと出力音声の中間表現として、音声波形を短時間フレームごとに周波数分析した音響特徴量が使用されています。
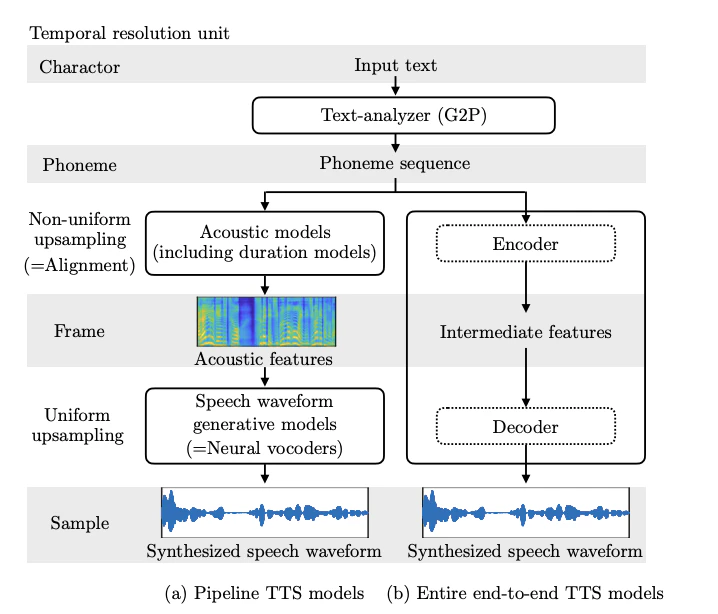
▼図1(a) について
まず、入力文が Text-analyzer(G2P)(テキスト解析)によって、音素系列へと変換されます。
音素とは、言葉の最小単位のことを表します。
そして音響モデルによって、音響特徴量に変換されます。
音響特徴量とは、音声の特徴を数値で表したものです。
次に、音声波形生成モデルにより、音響特徴量から音声波形を生成します。
音素から音響特徴量への変換で、各音素の長さが異なると不均一なアップサンプリングが必要となります。次に音響特徴量から音声波形への変換では、一定間隔でアップサンプリングする必要があります。
▼図1(b) について
End-to-end モデルでは、音響特徴量を使わず、テキストから直接音声波形を生成します。エンコーダからフレーム単位の中間特徴量を生成して、でlこー那によって、音声波形を生成します。
「hello」 について
-
テキスト
- 5 文字
- コンピュータで扱うデータ量は非常に小さい
-
音声
- 約 1 秒くらいの発音
- 音声をデジタル変換する
- サンプリング周波数:24,000Hz(1 秒間に 24,000 回音を記録)
- フレームシフト量:12.5 ms(0.0125 秒ごとに音の特徴を分析)
→ 80 フレームの音の特徴情報(1秒 ÷ 0.0125 秒 = 80)
24,000サンプル(24,0000Hz × 1 秒)の音声データ
-
人間の発音
- 全く同じ発音は二度と発音できない
- →聞こえ方は同じでも、フレーム単位・サンプル単位では発話ごとに毎回異なる
-
問題
- 入力された系列長の数千倍以上の出力系列を「確率的」に求める問題となり、これがすごく難しい
(自然なゆらぎを含めたり、毎回少しずつ違う出力を生成する必要がある→ここ、確率的な出力)
機械学習における一般的な問題と音声合成の違いについて
- 回帰問題の例
- 目標:予測値と実際の値の差を小さくする
- 方法:平均二条誤差(MSE)を最小化する
- 音声合成の例
- 特徴:音声には予測できない要素(非周期成分)が含まれる
- 問題点:MSE を使うと、平均的な音声しか生成できない
- 結果:自然さや豊かさが失われ、音質が低下する
従来の音声合成手法:素変接続方式
- 方法:多数の短い音声断片を繋ぎ合わせる
- 利点:実際の音声を使用するため、自然に聞こえる
- 欠点:大量の音声データが必要、接続部分で音質が劣化
HMM や DNN を使用した方式
- 原理:音声を 3 つの要素に分解
- 基本周波数(声の高さ)
- スペクトラム包絡(声の特徴)
- 非周期成分(ノイズなど)
- 方法:上記の要素を別々に生成し、組み合わせる
- 問題点:音声の周期性に関する仮定が現実と合わない、音声の特徴を分析する際に情報が失われる
DNN で高精度な音響特徴量を推定できても、完全に自然な音声にはならなかったり、人間の持つ豊かさ(肉声感)を表現するのが難しいのです。
そこで、肉声感のある音声合成を実現したのが、WaveNet なのです。
音声波形生成モデル:WaveNet
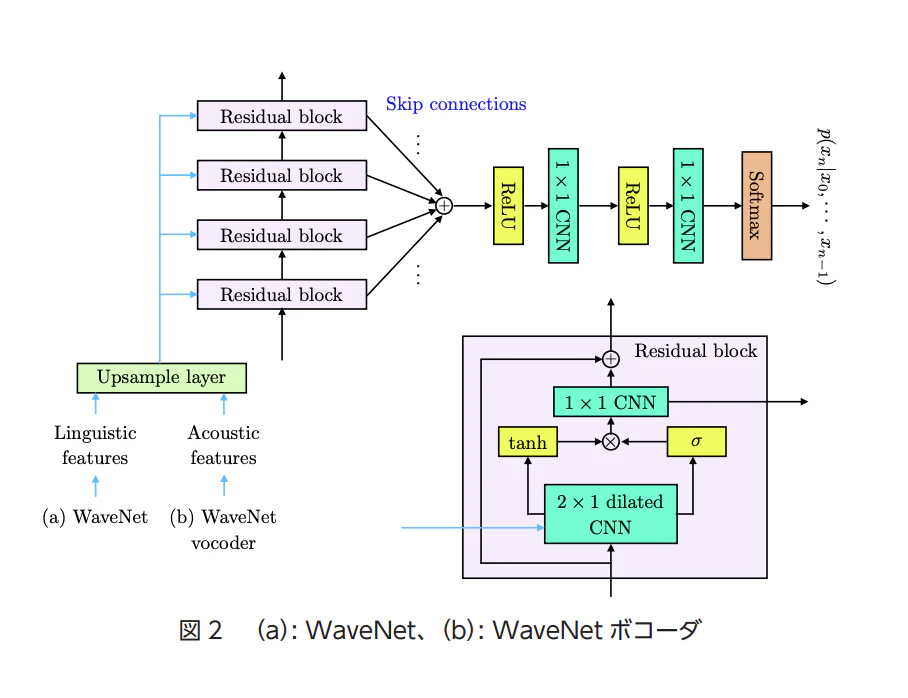
-
基本的な仕組み
- 入力:過去の音声データとテキストから得た情報
- 出力:次の瞬間の音声データの確率
-
特徴
- 多層の CNN を使用
- 音声の周期的な部分と不規則な部分の両方を学習できる
- 音声を 256 段階に分ける(回帰問題ではなく分類問題として扱う)
- 複雑な音声パターンを表現するために、単純な予測ではなく、確率の分布を学習する
- 交差エントロピー損失を最小化するようにモデルを学習する
- 従来の方法の問題点を解決
- より人間らしい音声を生成できる
-
音声の生成方法
- 学習した確率分布に基づいて、次の音声データを選ぶ
- 周期的な部分:ほぼ決まった値を選ぶ
- 不規則な部分:ランダムに値を選ぶ
WaveNet の進化
上記の WaveNet の後に「WaveNet ボコーダ」という新しい技術が生まれます。
これは、より詳細な音声の特徴を使って、さらに良い品質の音声を生成できるようになりました。
また、WaveNet ボコーダの後に多くの「ニューラルボコーダ」と呼ばれる技術が開発され、これらは音声合成や声の変換、歌声の合成に広く使われるようになりました。
しかし、WaveNet は高品質な音声を生成するためにかなりの時間を要しました。
【当時の例】1 秒の音声を生成するために 200 秒かかっていた
→新しい解決
-
Parallel WaveNet の登場
- ランダムなノイズと言語の情報を使って、すべての音声データを一度に生成することができる
- リアルタイムで音声を生成することができるようになった
-
NICT(National Institute of Information and Communications Technology:国立研究開発法人情報通信研究機構)による研究
- ノイズシェーピング
- 高い音域の音質を改善する技術
- WaveNet 以外の音声生成モデルにも使える
- サブバンド WaveNet
- 音声を複数の周波数帯に分けて処理
- 音声生成の速度を向上させる
- ニューラル話速変換
- 話す速さを変えても高品質な音声を生成できる
- ノイズシェーピング
-
Tacotron2 の登場
- Sequence-to-sequence モデルを採用
- 注意機構を導入し、外部モデルなしで直接テキストと音声を対応づけ
- テキストと音声の対応づけに外部モデルが必要で、前後の音素情報を含める必要があったが、必要無くなった
→問題点もある
- 再起的ニューラルネットワークを使用しているため、学習に時間がかかる
- Transfomer モデルを音響モデルに適用することで Tacotron2 と同等の高品質音声を実現しつつ、学習速度を改善した
Tacotron2 と Transfomer の課題
- 注意機構の予測失敗による発話の破綻
- 自己回帰モデルのため、生成速度が遅い
そこで FastSpeach が開発されました。
また、Parallel Tacotron2 もあります。
FastSpeach
- 非自己回帰 Sequence-to-sequence 型モデル
- 安定かつ高速な TSS(テキスト音声合成)を実現
- 音素継続長モデルを使用
- 自己注意型ネットワークでエンコードとデコード
Parallel Tacotron2
- 教師モデルや外部アライメントが不要
- Soft-DTW を使用して音素アライメントを自動獲得
- 自己回帰モデルと同等の品質を実現
NICT の取り組み
- 外部アライメントモデルを導入した Parallel Tactron2 を実装
- Multi-stream HiFi-GAN を組み合わせて使用
結果、CPU のみでリアルタイム生成可能な高品質 TSS を実現しました。
自己回帰モデルと非自己回帰モデルについて
- 自己回帰モデル:過去の出力を次の入力として使用するモデル
- 順次的に出力を生成
- 前の出力に依存して次の出力を決定
- 高品質な出力が可能
- 自然な連続性を持つ出力を生成
- 生成速度が遅い
- エラーが蓄積する可能性あり
- 非自己回帰モデル:過去の出力に依存せず、一度にすべての出力を生成するモデル
- 並列処理が可能
- 入力から直接出力を生成
- 高速な生成が可能
- エラーの蓄積が少ない
- 出力の連続性や一貫性の維持が難しい場合あり
どちらが良いというわけではなく、問題や課題によって適切なモデルを選択することが重要です。
前半戦終了
このあとは、ニューラル音声波形生成モデルなどを触れていきます。
いろいろなモデルが登場しましたが、まずはモデルの詳細を触れる前に音生成声の概要を大まかにつかめればと思います。
後半戦もよろしくお願いいたします!