
概要
**「複数の学習器を組み合わせて予測を行う|アンサンブル学習」**を用いて、
ECにおける「初回離脱客か/継続客か」の区別が付けられた顧客データ10000件で学習し、
未知の顧客に対し**「その客は初回離脱客になるか、継続客になるか」**の二値分類予測を行う
何のためにこの予測をするのか
「このままだと初回で離脱しそうな顧客」を見つけ出し、カムバッククーポン等で重点的にフォローすることで、効率的に継続客に転換していく、ための予測
全体の流れ
- 準備|データ内容確認
- 前処理
- 正規化
- 欠損値補完
- 次元削減
- アンサンブル学習|予測
- 性能評価
- 混同行列
準備
import numpy as np
import pandas as pd
可視化
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
アンサンブル
from sklearn.ensemble import VotingClassifier
アンサンブルに使う、5つの学習器
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
データ分割
from sklearn.model_selection import train_test_split
モデル評価
from sklearn.metrics import (
accuracy_score, #正解率表示
confusion_matrix, #混同行列
classification_report #適合率/検出率/F値の表示
)
CSVをデータフレームに変換
df = pd.read_csv('/content/ec_user.csv')
データ内容確認
内容の一部を確認
df.head()

df.tail()

. . . . .
データは**「とあるECサイトの顧客データ10000件」を想定**しており、年齢等のパーソナルデータとともに、全員に「初回離脱客となったか/継続客となったか」のラベルが付けられている
- target|初回離脱客(=1)か、継続客(=0)か
- name|氏名(匿名化として全て「yamada」としている)
- sex|性別
- age|年齢
- height|身長
- weight|体重
- price|初回の購入金額
- job|職業
- address|住所
データサイズ確認
df.shape
(10000, 10)
要約統計量を確認
df.describe()

. . . . .
初回離脱客か継続客かを表す「target」の内容と、比率を確認
sns.countplot('target',data=df)
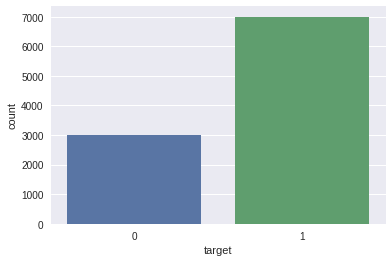
0(=継続客)と、1(=初回離脱客)は「3:7」の割合
前処理
現時点で不要であることが明らかな、「顧客ID」と「氏名」の列を削除
df = df.drop(["id","name"], axis=1)
正規化
文字データを数値データに変換
性別はシンプルに「男性=0」「女性=1」として変換
#性別を数値データに変換
df["sex"][df["sex"] == "male"] = 0
df["sex"][df["sex"] == "female"] = 1
One-hot
「住所」「職業」に関しては、単純に「埼玉=5」「千葉=6」...等の連番を振っていってしまうと、数値が予測に影響を及ぼしてしまうため、「カテゴリの各内容に該当する=1/該当しない=0」の二値に変換する「One-hot変換」を行う
df = pd.get_dummies(df, columns=['address', 'job'])
df.head()
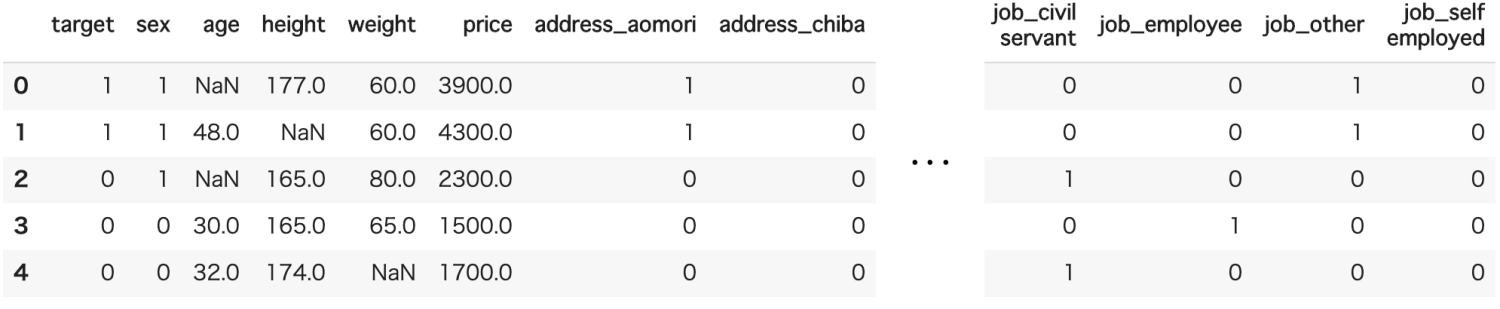
欠損値補完
欠損数の確認
df.isnull().sum()
target 0
sex 0
age 374
height 310
weight 246
price 366
address_aomori 0
address_chiba 0
...
job_other 0
job_self employed 0
dtype: int64
「年齢/身長/体重/初回購入金額」に、欠損がある
今回は各項目の「中央値」を当てはめることで、欠損の補完とする
df["age"].fillna(df.age.median(), inplace=True)
df["height"].fillna(df.height.median(), inplace=True)
df["weight"].fillna(df.weight.median(), inplace=True)
df["price"].fillna(df.price.median(), inplace=True)
次元削減
予測精度向上のため各列の相関係数の算出を行い、target列とあまり関係の無い(予測への貢献度の低い)列を見つけ出し、取り除く
相関係数の算出
objectデータは相関係数算出の対象外となるので、まずは現状のデータ型がどうなっているかを確認する
df.dtypes
target int64
sex object
age float64
height float64
weight float64
price float64
address_aomori uint8
address_chiba uint8
...
job_other uint8
job_self employed uint8
dtype: object
object型をint型に変換
df['sex'] = df['sex'].astype(int)
改めてデータ型を確認
df.dtypes
target int64
sex int64
age float64
height float64
weight float64
price float64
address_aomori uint8
address_chiba uint8
...
job_other uint8
job_self employed uint8
dtype: object
corrで各列の相関係数を算出
df_corr = df.corr()
算出結果を可視化
sns.heatmap(df_corr, vmax=1, vmin=-1, center=0)
plt.savefig('/content/corr_heatmap.png')
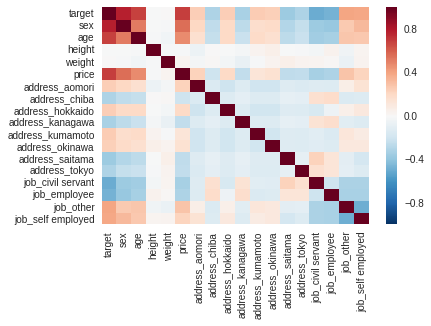
色が薄い箇所が、相関の低い列関係となっている
targetと特に相関が低いのは「身長」と「体重」
この2列は予測への貢献度が低いと考え、削除する
df = df.drop(["height","weight"], axis=1)
訓練/テストデータの用意
目的変数/説明変数の定義
「target以外の列」を説明変数に定義
df_except_y = df.drop(["target"], axis=1)
X = df_except_y.as_matrix()
X = X.astype(int)
「target列」を目的変数に定義
y = df['target'].as_matrix()
データ分割
データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
学習/予測
アンサンブル学習
アンサンブル学習では、複数の弱学習器の予測値を組み合わせて、多数決などで最終的な予測を出すことで、予測エラーを小さくし、極端な間違いを回避します
boostingやstacking等の手法がありますが、今回はvotingという手法をとります
votingにはhardとsoftの2タイプがあり、今回はデフォルトのhard votingを行います
hard voting
ラベル単位のシンプルな多数決を行う
例えば3つの学習器の予測内容が
- 学習器A「これは陽性だと思います」
- 学習器B「これは陰性だと思います」
- 学習器C「これは陽性だと思います」
という予測をした場合、「陽性2票/陰性1票」で、陽性が採用されます
soft voting
各分類器でクラスごとに出した予測確率の平均で判断する
例えば3つの学習器の予測内容が
- 学習器A「これが陽性である確率は60%です」
- 学習器B「これが陽性である確率は20%です」
- 学習器C「これが陽性である確率は40%です」
という予測をした場合、陽性である確率は「(60+20+40)/3 = 40」で、40%となり、
陰性である確率の方が高い、という予測結果となります
変数ensembleに、以下の5つの学習器をセット
- GaussianNB|ナイーブベイズ
- MLPClassifier|多層パーセプトロン
- LogisticRegression|ロジスティック回帰
- RandomForestClassifier|ランダムフォレスト
- SVC|サポートベクターマシン
estimators = [
('gnb', GaussianNB()),
('mlp', MLPClassifier(hidden_layer_sizes=(80, 40), max_iter=10000)),
('log', LogisticRegression(solver='lbfgs', max_iter=10000)),
('rfc', RandomForestClassifier(n_estimators=500)),
('svc', SVC(gamma='scale', probability=True))
]
アンサンブル学習器を作成
ensemble = VotingClassifier(estimators)
訓練データで学習
ensemble.fit(X_train, y_train)
テストデータで予測
y_pred = ensemble.predict(X_test)
性能評価
まずは単純に正解率を表示
acc = accuracy_score(y_test, y_pred)
print(acc)
0.9853333333333333
正解率は約98.5%
混同行列
「正解率」は評価指標として信頼性に欠ける場合があるため、続いて混同行列で精度を評価する
その前に、今回の混同行列における「陰性/陽性」の設定について記載
陰性/陽性の設定
病気の検査において
- 病気の反応無し|陰性
- 病気の反応有り|陽性
となり、「検出したいもの/取りこぼしたくないもの」を「陽性」に設定するのがベターかと考えます
今回は「初回離脱客」を検出し、重点的にフォローしたいため、こちらを陽性に設定
- 継続客|陰性
- 初回離脱客|陽性
混同行列とは
「予測」と「実際はどうだったか」の関係を表にしたもの
二値分類の場合、以下のような行列となります
|予測:陽性|予測:陰性|
:-:|:-:|:-:
実際:陽性|TP|FN
実際:陰性|FP|TN
. . . . .
-
TP|True Positive
- 初回離脱客(陽性)を、ちゃんと「初回離脱客(陽性)だと予測」できた数
-
FN|False Negative
- 初回離脱客(陽性)を、間違って「継続客(陰性)だと予測」してしまった数
-
FP|False Positive
- 継続客(陰性)を、間違って「初回離脱客(陽性)だと予測」してしまった数
-
TN|True Negative
- 継続客(陰性)を、ちゃんと「継続客(陰性)だと予測」できた数
. . . . .
今回は初回離脱客を見つけ出し、重点的にフォローしたいので、極力小さい値にしたいのは「FN」です
confusion_matrixで混同行列を表示
print(confusion_matrix(y_test, y_pred))
[[ 876 20]
[ 24 2080]]
複数の指標での評価
混同行列を元に、適合率/検出率/F値という指標で予測を評価します
. . . . .
適合率/検出率/F値を表示
print(classification_report(y_test, y_pred))

-
正解率|Accuracy
- 単純な正解率。F値等と比べると指標としての信頼感は低い印象
- 「どんな場合でも陰性という予測結果しか出さないモデル」は、どう考えても使いものにならないが、1000人中1人が病気(陽性)だった場合、そのモデルの正解率は99.9%であり、良いモデルに見えてしまう。よってこのような場合には指標として適さない
-
適合率|Precision
- 陽性判定において、どれだけ間違いが少なかったかの割合
- 初回離脱客(陽性)と予測したが、実際は継続客(陰性)だった、という数がどれだけかの指標
-
再現率|Recal
- 陽性の人の何割を、ちゃんと陽性と判定できたか。つまり陽性の人をどれだけ取りこぼさなかったか
- 初回離脱客(陽性)なのに、予測で継続客(陰性)と判定してしまったのがどれだけかの指標
-
F値|F-score
- 適合率と再現率の調和平均を求めて、極端に振れないようにする値
- 適合率と再現率をバランス良く持ち合わせているかを示す指標
. . . . .
今回の内容だと、適合率よりは再現率の方が重要と言えますが、偏った評価とならないよう、一般的にF値が指標として重視されることが多いかと思います
総括
EC顧客データをアンサンブル学習し、未知の顧客に対し「初回離脱客になるか、継続客になるか」を、F値0.99で予測する学習器を作成した
今後の目標
- グリッドサーチ等でパラメータの調整
- 学習器ごとの評価を個別表示
- 特徴量エンジニアリング
- 前処理の改善
- 交差検証
を行い、学習/予測の質を向上させていきたい