はじめに
株式会社POLという会社でエンジニアをやっている @HHajimeW です。
この記事は「POL Advent Calendar 2021」の19日目の記事です。
昨日の @yiwi さんからバトンを頂きました。
「POL Advent Calendar 2021」の14日目の記事にも記載されていたのですが、POL ではギルド活動という制度があり、毎週木曜の午後を活動時間に充てて、割と自由に開発することができます。
ギルド自体はフロントエンド, バックエンド, インフラなどがあります。どういった活動をするかについては特に指示されるわけではないのですが、今回はインフラのキャッチアップのために 「リリース時の Aurora バックアップ手順の自動化」 をやってみました。
何をつくるのか
弊社ではリリースの手順書があり、それに記載してある手順をそのままコードにします。
手順書は以下(画像内の id はマスクしています)

手順は大きく分けて3つとなります。
- スナップショットの取得
- スナップショットが利用可能になるまで待機
- 取得したスナップショットを元にクラスタの復元
環境構築 と ライブラリの準備
Python を初めて使う人もいると思うので、環境構築の方法も軽く触れようと思います。人にもよると思うのですが、僕は conda を使っています。
この方と同じように僕も環境ごとに Python を Install して、その中で pip install でライブラリを入れています。僕は各環境に余分なライブラリが入るのが嫌なので、minidonda を使っています。
以下のコマンドで conda の環境を作ることができます。
> conda create -n <my_env> python=3.8
以下のコマンドで conda の仮想環境をアクティベート。
> conda activate <my_env>
boto3 をインストールします。
(<my_env>)> pip install boto3
これで準備は完了です。
コード
コードは以下です。
import boto3
import os
import re
import datetime
DB_CLSUTER_SNAPSHOT_IDENTIFIER = "test-aurora-mysql"
SOURCE_DB_CLSUTER_IDNETIFIER = "test-aurora-mysql-cluster"
rds = boto3.client('rds')
# スナップショット名を生成する関数
def create_db_cluster_snapshot_identifier():
dt_now = datetime.datetime.now()
return DB_CLSUTER_SNAPSHOT_IDENTIFIER + '-' + dt_now.strftime('%Y-%m-%d-%H-%M-%S')
# 復元するDBクラスタ名を生成する関数
def create_db_cluster_identifier():
dt_now = datetime.datetime.now()
return SOURCE_DB_CLSUTER_IDNETIFIER + '-replica-' + dt_now.strftime('%Y-%m-%d-%H-%M-%S')
# DBクラスタのスナップショットを取得する関数
def create_db_cluster_snapshot() -> dict:
response = rds.create_db_cluster_snapshot(
DBClusterSnapshotIdentifier=create_db_cluster_snapshot_identifier(),
DBClusterIdentifier=SOURCE_DB_CLSUTER_IDNETIFIER,
Tags=[
{
'Key': 'test',
'Value': 'testtest'
},
]
)
print(response)
return response
# DBクラスタを復元する関数
def restore_db_cluster(snapshotIdentifier: str) -> dict:
response = rds.restore_db_cluster_from_snapshot(
DBClusterIdentifier=create_db_cluster_identifier(),
SnapshotIdentifier=snapshotIdentifier,
Engine = 'aurora-mysql',
EngineVersion = 'あなた Aurora MySQL のバージョン',
EnableCloudwatchLogsExports = [
'error',
'slowquery'
],
VpcSecurityGroupIds=[
'あなたのVPCのセキュリティグループID',
],
DBSubnetGroupName='あなたのDBのサブネットグループ',
DBClusterParameterGroupName='あなたのDBクラスタのパラメータグロープ名',
Tags=[
{
'Key': 'testtesttest',
'Value': 'testtesttesttest'
},
],
)
print(response)
return response
def main():
# スナップショットの作成
snapshotResponse = create_db_cluster_snapshot()
snapshotIdentifier = snapshotResponse.get('DBClusterSnapshot').get('DBClusterSnapshotIdentifier')
# スナップショットが利用可能になるのを待機
snapshotWaiter = rds.get_waiter('db_cluster_snapshot_available')
snapshotWaiter.wait(
WaiterConfig={
'Delay': 60,
'MaxAttempts': 60
}
)
print(snapshotIdentifier)
# インスタンスの復元
restoreResponse = restore_db_cluster(snapshotIdentifier)
print(restoreResponse)
if __name__ == '__main__':
main()
実行
CLI から実行しますが、認証情報が必要なので、AWS のログイン画面で準備を行います。
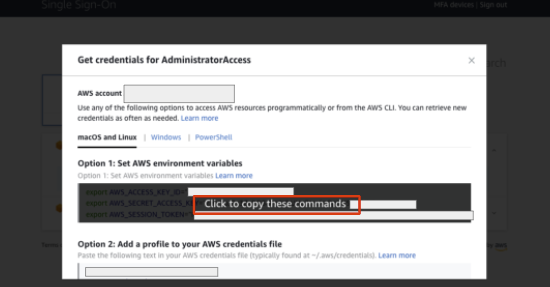
上図の "Command line or programmatic access" をクリックすると、下図のようなモーダルが表示されます。モーダルの真ん中あたりにカーソルを持っていき、 "Click to copy these commands" をクリックすると、AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY と AWS_SESSION_TOKEN がコピーされるので、それをCLI 上で貼り付けます。
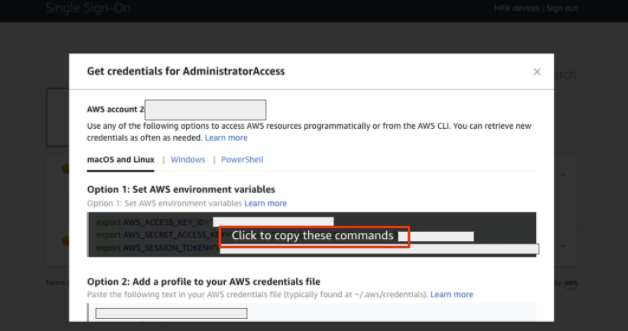
以下のような感じになれば、準備は完了です。

以下のコマンドで先程作成した Python ファイルを実行します。
$ python create_db_restore.py
実行結果が以下のように出力されれば成功です!!
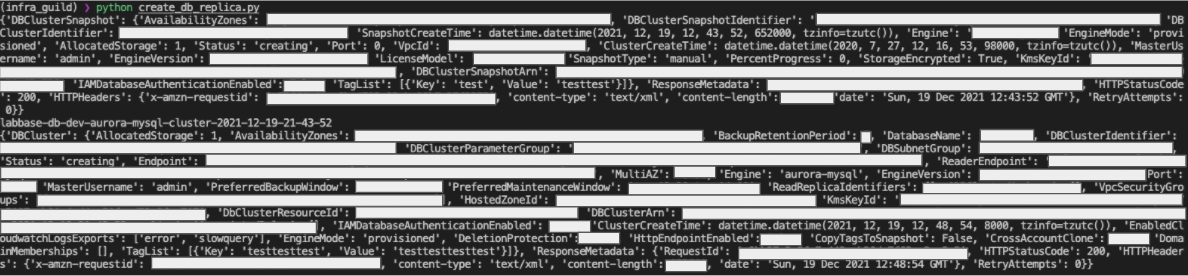
まとめ
Python で気軽に環境をつくって、SDKを触れるのでインフラへの抵抗感もそんなに感じることなくやってみることができました。本番に実装するにはまだテストを書いたり、CIに組み込んだりしないとなのですが、引き続きやっていこうと思います!
明日は最近はじめてオフラインでお会いした千さんです。