はじめに
今日やっていたDataRobotのイベントに仕事の休憩の時とか参加してて、面白そうなので、触ってみました。ちょうどQiita夏祭りだったので、記事にします!
背景としては、修士学生のときの、HateSpeechの検出を研究していたので、その時使っていた手法の一つで抽出した特徴量を入力として、DataRobotを使ってみたという感じです。
使いやすさだったり、精度だったり、見ていこうかなと思います。
論文概要
こちらの論文ですね。興味ある方は読んでみてください。
Hate, Clean の2クラス分類と、Hate, Offensive, Clean の3分類で実験しています。それぞれ使用する特徴量は同じものを使っていました。2クラスだと正解率が 87.4 % で、3クラスだと正解率が78.4%でした。Offensiveクラスは分類が難しいので、正解率だけで判断はできないですが、テストデータは各クラス、同数用いていたので、それなりの結果だと思います。
使用したデータと特徴量を抜粋
使用するデータは過去の英語の Tweet データから特徴量を抽出したものです。
Number_of_Posirive_Words:Positiveな単語の数(Long型)
Number_of_Negative_Words:Negativeな単語の数(Long型)
Number_of_Posirive_Emoticons:Positiveな絵文字の数(Long型)
Number_of_Negative_Emoticons:Negativeな絵文字の数(Long型)
・
・
・
Pattern[x]:各クラスに特徴的に出現する品詞パターンの有無(Boolean型)
TopWords[x]:各クラスに特徴的に出現する単語の有無(Boolean型)
今回はデータが100MBしか入らなかったので、少しデータ量が少ないものを使用。
トライアルじゃなければ、もっと入力できるのかな。

DataRobot使ってみた
データの入力画面はこんな感じでした。ローカルファイルを選択します。
サポートされているファイル形式は、「.csv, .tsv, .dsv, .xls, .xlsx, .sas7bdat, .bz2, .gz, .zip, .tar, .tgz」で、
サポートされている特徴量の型は、「数値、カテゴリー、ブール、テキスト、日付、通貨、割合、および長さ」でした。マルチモーダルAIでは画像とか、位置情報も組み合わせられるらしいです。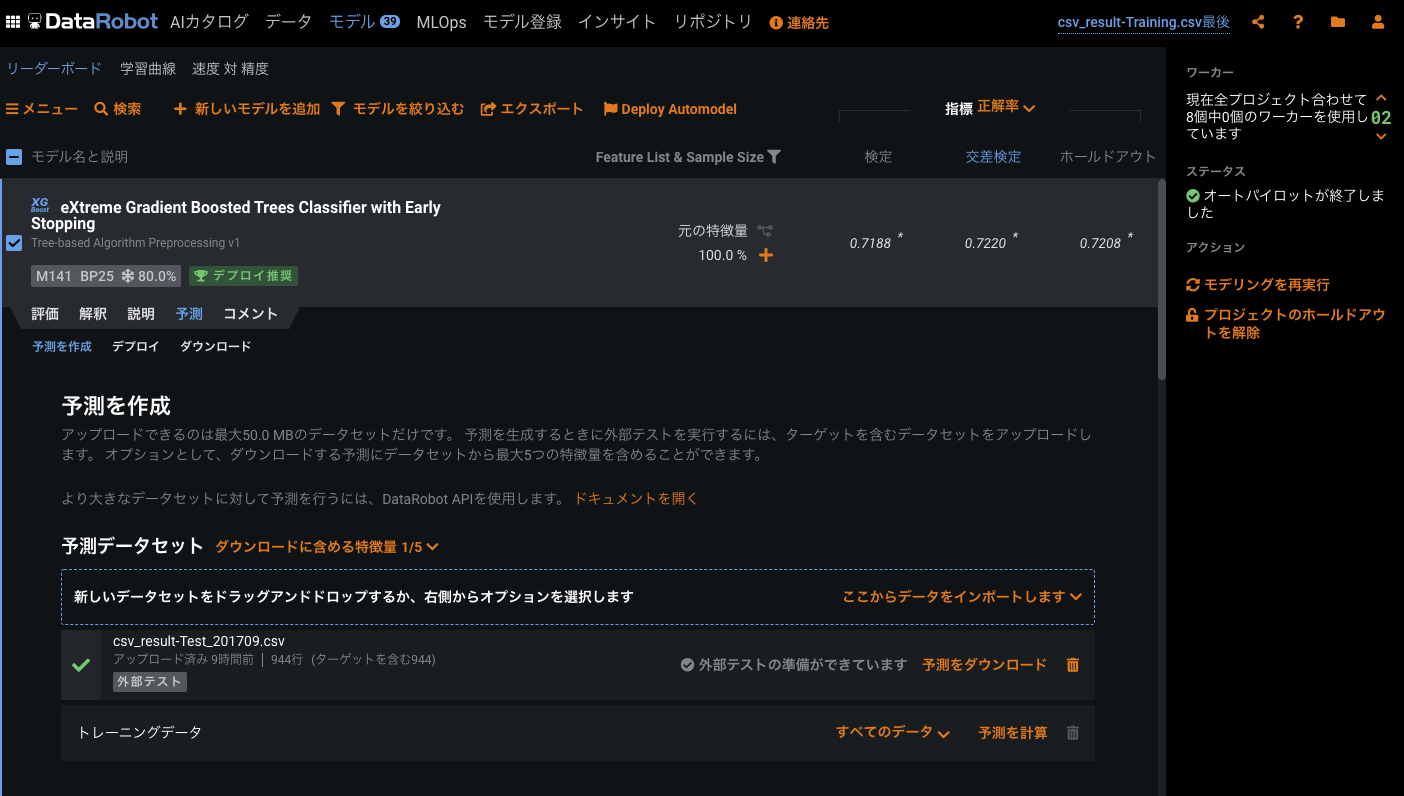
データ数:5355 , 特徴量数:862でした。
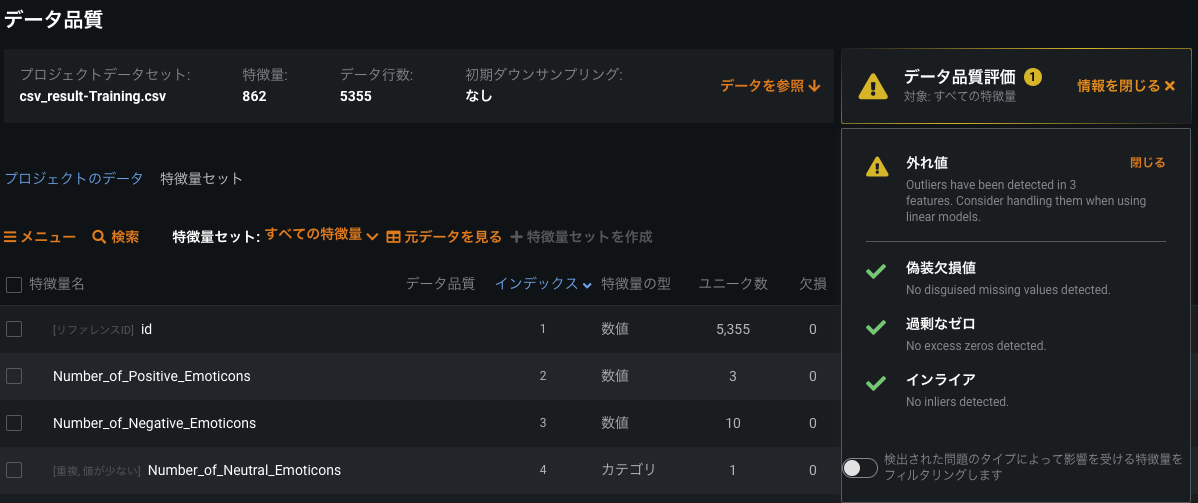
外れ値チェックとか、欠損値チェックとか、地味にありがたいですね。
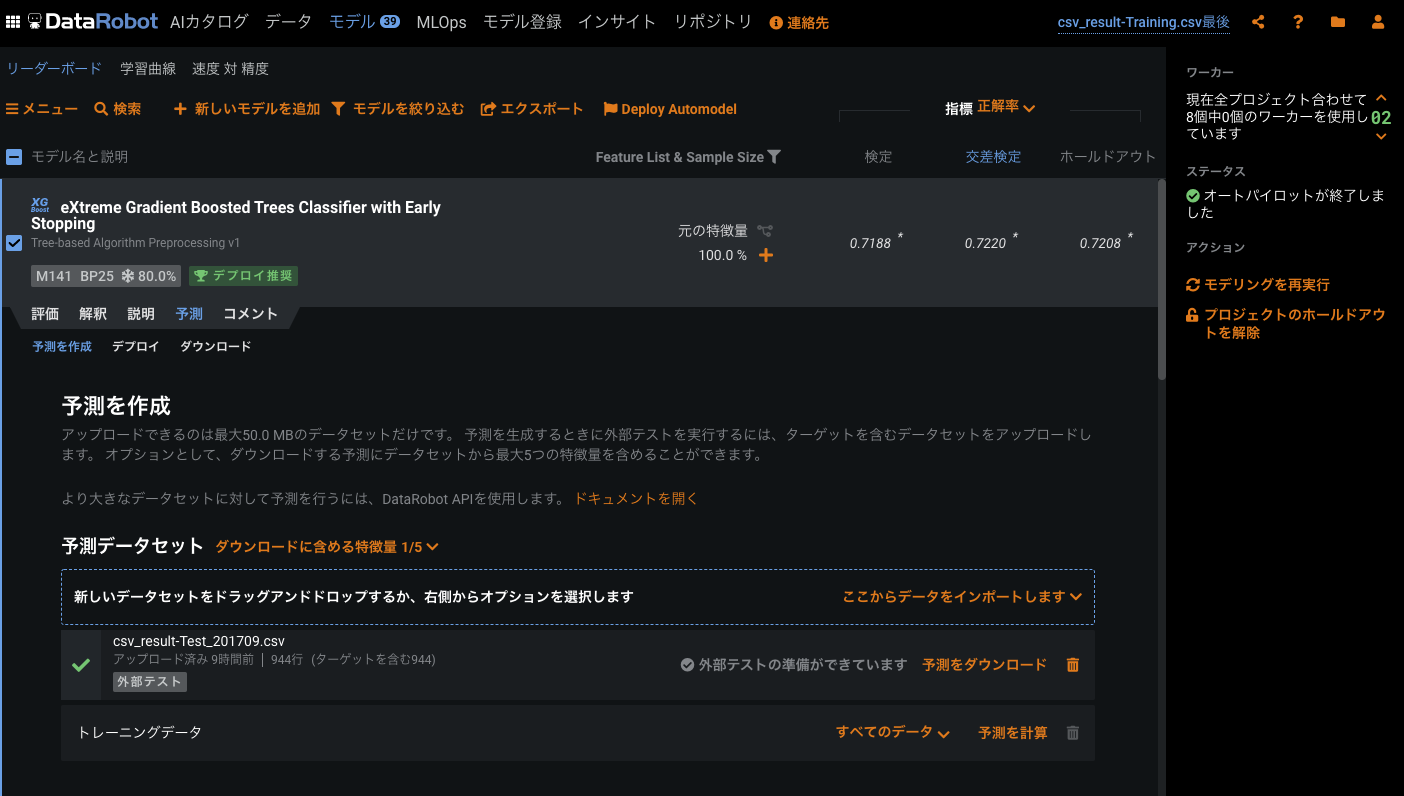
予測モデル一覧とCVの結果などは、こちらの画面になります。ホールドアウトで正解率が 72%くらいなので、良いのでは。トータルの作業時間も試すだけであれば、1時間くらいなので、便利だなあという感じ。まだまだ使いこなせていない感じがあるので、チューニングとかいろいろしたら、もっと上がりそうではあります。
感想
入力のデータの前処理が済んでいれば、秒でモデルをつくって、予測できるのは、楽ちんで良い!
論文を執筆した時よりもデータ数少なかったので、単純比較できないのですが、まあまあ良い精度出て、お手軽なので、コード書く人がいなくて、価格払える企業さんとかは使いやすそう。
とはいえ、前処理とかできないとどうしようもないから、こういうところを買収したり、自動特徴量探索があるって感じなんですかね。
イベントのこのセッションでも、言及されていましたが、予測だけではなく、データ準備とか、運用周り、意思決定のための説明が機能として実装されてるのはすごいなと。
あとは、モデルを並列でバンバン実行してくれるので、いろいろ試しながら、比較とかすごくしやすいのもよいのかなとおもいました。
デプロイとかも、いろんなやり方あるみたいだし、お手軽はお手軽ですね!!