WHY
実装面と今後の伸びしろに期待を込めて下記の観点から紹介します。
- Google Researchの人が共著者
- BackEndがTensorflow
- CaffeeのModel Zooのようなものがあり公開済みモデル用のエコシステムがある
- 深層学習よりも収束が早く次のトレンドになりそう
Deep Probabilistic Programmingを読んだのでこの内容から抜粋して紹介します。
どんなもの?
従来の深層学習よりも柔軟性があり、かつ計算効率の良い確率的プログラミングが可能なライブラリの紹介。
同じモデルを別の推論機で使用できる。
推論の一部としてモデルの表現の再利用が可能なのでバラエティに富んだネットワーク構成も可能
バックエンドがTensorflowでできておりCaffeeのModel Zoo のようなものがあるProbability Zoo
先行研究と比べてどこがすごい?
・計算効率が深層学習よりも良い
・柔軟性のある推論部分の作成
・Stan,PyMC3に比べてロジスティック回帰で35倍の速度
技術や手法のキモはどこ?
・ランダムな値生成と推論で構成
・オープンな技術で作成(バックエンドがTensorflow)
・推論部分にモデルの構築も含めている部分が従来のものと異なる。
・Bayesian Recurrent Neural Network with Variable Length
具体例
Bayesian Recurrent Neural Network with Variable Length
Normal:正規分布
Weightと正則化の正規分布の平均と分散を学習

GAN
生成用のネットワークと識別用のネットワークを構成し、データのパラメータは分布から生成。予測値も分布から生成
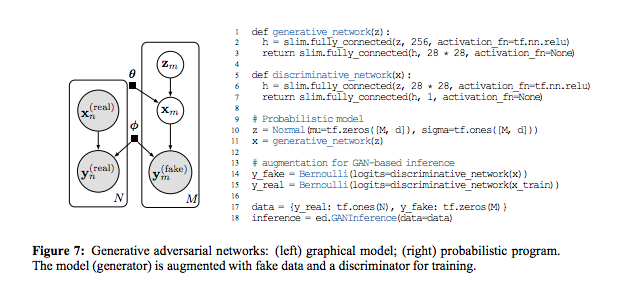
推測器の複合
EM Algorithm

どうやって有効だと検証した?
各手法の比較検討

従来ライブラリとの比較
PyMCとStanで速度検証
Stanの約20倍
PyMCの約40倍
Spec
12-core Intel i7-5930K CPU 3.5GHz NVIDIA Titan X(Maxwell) GPU
Task
generate posterior samples with Hamiltonian Monte Carlo
Data
Covertype dataset (N = 581012, D = 54; responses were binarized)
Other
100 HMC iterations, with 10 leapfrog updates per iteration and a step size of 0.5/N
35x speedup from stan
議論はある?
最新の技術は伝統的なベイズ手法をもっと取り入れていきたい
巨大なデータにおいても適用できるようにしていきたい
次に読むべき論文は?
本格的な使用方法がわかるので下記の論文がオススメ
Tran, Dustin, et al. "Edward: A library for probabilistic modeling, inference, and criticism." arXiv preprint arXiv:1610.09787 (2016).