背景
深層学習のフレームワークには大きく分けて2種類が存在しています。
- 'Define and Run'(Tensorflow, Keras): ネットワークを固定してから学習
- 利点:最適化が容易
- 欠点:データ構造によってモデルを変えるのが難しい
- 'Define by Run'(Chainer, PyTorch, DyNet): ネットワークは順伝搬後に確定し学習
- 利点:データ構造によってモデルを変えるのが簡単、デバッグが容易
- 欠点:最適化が難しい
では自然言語処理だとなぜモデルが複雑になったり、データ構造が変わるか具体例を見て確認していきます。
具体例
データ
下記は某アカウントのつぶやきになります。文の長さが異なることが分かると思います。文の長さが異なると深層学習ではパディングという手法を用いて文長を同一にしてミニバッチ処理ができる用にします。
いい夢見ろよ😴的な? 笑 さっ風呂入ろ ♨ ️
南港に沈めたら解決
チロルチョコ
:
Padding処理後
いい夢見ろよ😴的な? 笑 さっ風呂入ろ♨ ️
南港に沈めたら解決!<unk><unk><unk>
チロルチョコ!!<unk><unk><unk><unk>
:
しかしこの手法では最大文長さに依存してしまいます。
そこでデータ長によって異なるモデルを用意する手法であるバケッティングという処理があります。
下記のように言語ごとにモデルを変えて学習させることです。Define by Run型だとこの記述が簡単にできます。
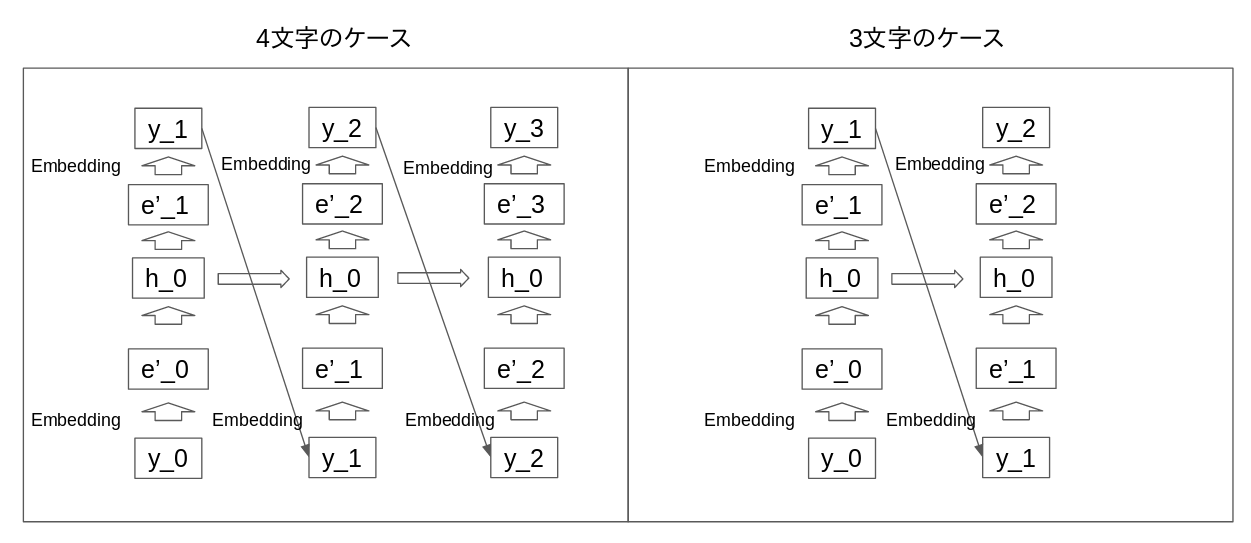
モデル
下記は構文解析のモデルです。これはデータによって解析する構造が変わるためこれもDefine by Run型が向いています。
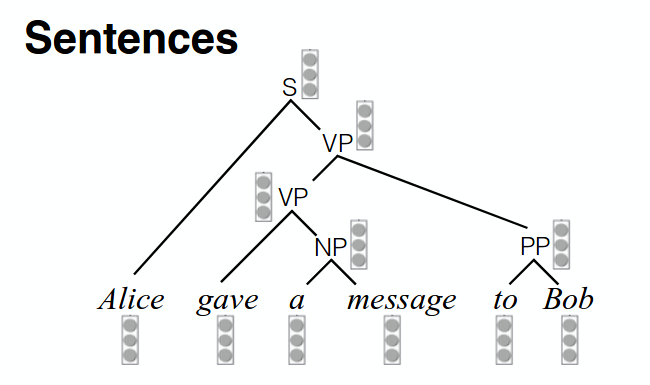
下記のモデルはRecursive Networkと呼ばれます。parsing処理が必要ですが下記のメリットがあります。
- Word2Vecと異なり長文でも空間上の関係性が分かる
- 単語間の関係性が明確になる
下記の具体例がわかりやすいと思います。Recursiveだと長文の関係性を理解しつつ、低次元の空間に写像が可能です。
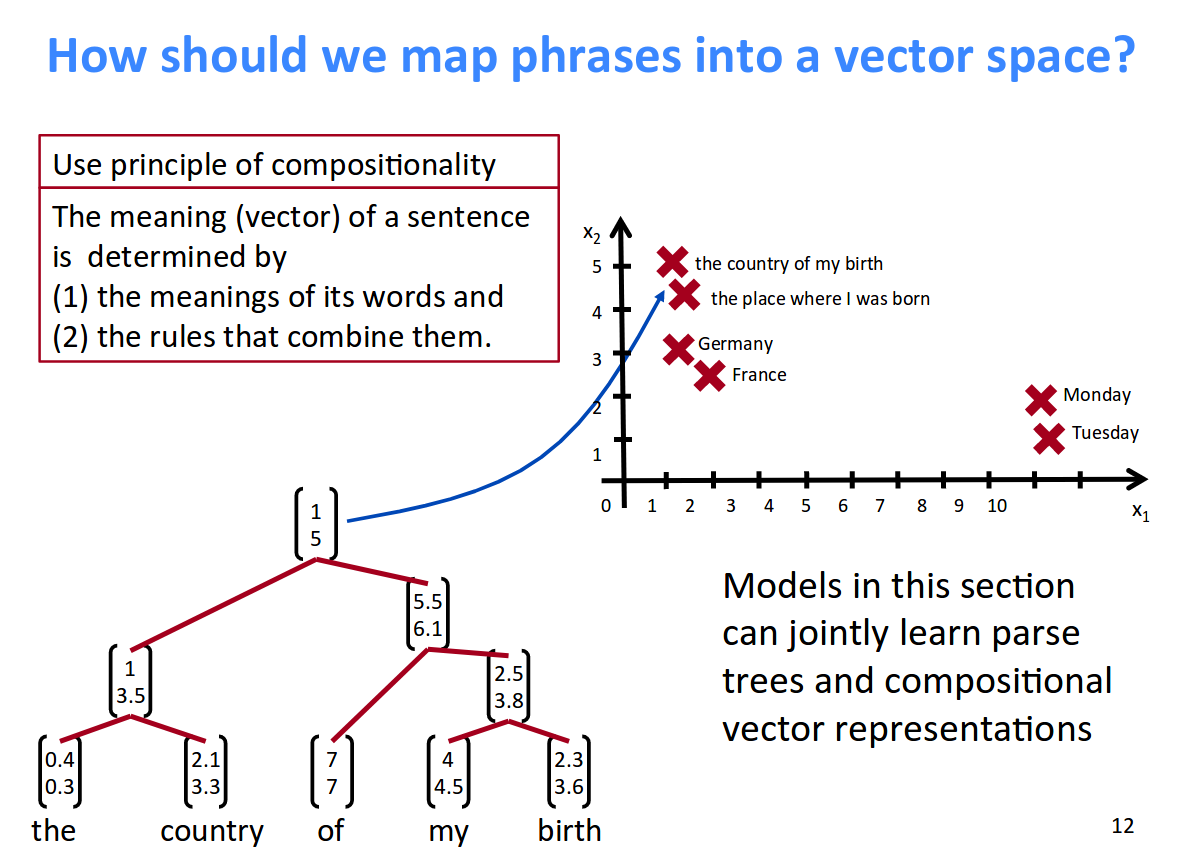
Lecture 14: Tree Recursive Neural Networks
and Constituency Parsing 12p
ソースコード
下記が具体的なコードになります。言語処理ではなくmnistのデータを用いているため画像のサイズによってネットワーク構造を変えています。
forwardの処理部分でデータのサイズに合わせてネットワーク構造を変えています。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.conv1_2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_2 = nn.Conv2d(20, 40, kernel_size=5)
self.fc1_2 = nn.Linear(360, 50)
self.over_size = 28
def forward(self, x):
_, _, h, w = x.size()
if h > self.over_size:
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv1_2(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2_2(x)), 2))
x = x.view(-1, 360)
x = F.relu(self.fc1_2(x))
else:
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
Recursive Neural Networksのコードについて気になる方は下記のnotebookをご参照下さい。
Define by Runフレームワークについて
各フレームワークに対する個人的な見解についてです。
- Chainer
- 日本語の資料が豊富なため日本人で初心者の方は間違いなくお薦め
- PyTorch
- コミュニティが活発で英語で豊富な事例や見解が取得可能なので最新の事例を試したい方はお薦め
- DyNet
- C++も使用可能なため高速な処理をしたい場合はお薦め。玄人向け
Tensorflowに付随しているTensorboardのような可視化機能も各種フレームワークはカバーするために下記のようなものも展開しています。
Chainer
-
https://github.com/neka-nat/tensorboard-chainer
PyTorch -
https://github.com/lanpa/tensorboard-pytorch
DyNet - https://github.com/clab/dynet/tree/master/examples/tensorboard
最後に
画像などのデータは固定されいてるためDefine and Run型のフレームワークが良いですが自然言語処理ではDefine by RUN型のフレームワークがお薦めです。
この機会にDefine by RUN型のフレームワークを触ってみてはいかがでしょうか!!
参考
Simple and Efficient Learning with Automatic Operation Batching
深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ)