前回
1:http://qiita.com/GushiSnow/items/cc1440e0a8ea199e78c5
データ準備編後編
11:OpenFstを用いてsilにおける重み付き状態変換器を作成しておく。
重み付き状態変換器について軽く説明
重み付き状態変換器は音声認識、機械学習、文字認識など幅広く使用されている。Kaldiも使用している。
詳細
http://www.openfst.org/twiki/bin/view/FST/FstQuickTour
下記のように入力と出力のペアがあり、そのペアに対して重みがついており、初期の状態からの変遷を表す。
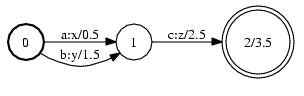
今回の場合は
入力が音素
出力が単語
となり、下記コマンドで作成される
# silのみ出力
utils/make_lexicon_fst_silprob.pl $tmpdir/lexiconp_silprob_disambig.txt $s rcdir/silprob.txt $silphone '#'$ndisambig | \
# 置き換え処理
sed 's=\#[0-9][0-9]*=<eps>=g' | \for indirect one, use twice the learning rate
# 音素を入力、単語を出力として重み付き状態変換器の作成
fstcompile --isymbols=$dir/phones.txt --osymbols=$dir/words.txt \
--keep_isymbols=false --keep_osymbols=false | \
# 14:重み付き状態変換器をソート:下記に例を示す
fstarcsort --sort_type=olabel > $dir/L.fst || exit 1
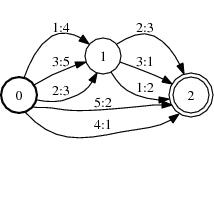
ソートの例
ソート前
ソート後
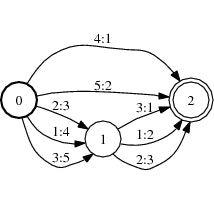
ソート前とソート後で出力ラベルの昇順に並んでいることがわかる。
上図では重みは表示されていない。
上記のコマンドで出力されたfstファイルの中身を確認する方法
fstprint --isymbols=./data/lang/phones.txt(音素ファイル) --osymbols=./data/lang/words.txt(単語ファイル) ../../../test_japanese/data/lang_test_tg/L.fst(fstファイル) test.txt(出力されるファイル)
出力されたファイルの中身
| ラベル | 次に遷移するラベル | 音素 | 単語 | 重み |
|---|---|---|---|---|
| 0 | 1 | 0.693147182 | ||
| 0 | 1 | SIL | 0.693147182 | |
| 1 | 1 | SIL | !SIL | |
| 1 | 1 | SIL_E | 'EM | 0.693147182 |
| 1 | 2 | SIL_E | 'EM | 0.693147182 |
| 1 | 1 | SIL_B | A | 0.693147182 |
| 1 | 2 | SIL_B | A | 0.693147182 |
| 1 | ||||
| 2 | 1 | SIL |
これらを図に直してみたい場合
fstdraw --isymbols=./data/lang/phones.txt(音素ファイル) --osymbols=./data/lang/words.txt(単語ファイル) ../../../test_japanese/data/lang_test_tg/L.fst(fstファイル) test.dot(dot記述式ファイル)
dotファイルを画像ファイルに変換して開く
dot -Tjpg test.dot > test.jpg
xli test.jpg
下記のように出力される
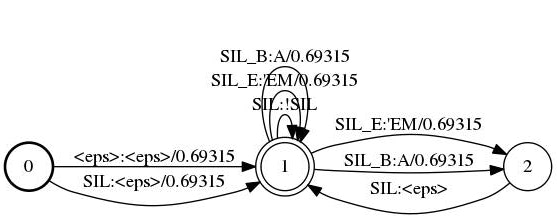
表で示したラベル、次に遷移するラベル、音素、単語、重みと対応することが分かる。
12:utils/sym2int.plを用いて、下記のファイルをint形式に変換する。
oov.txt
phones.txt
roots.txt
word_boundary.txt
13:disambiguation symbolsのfstファイルを作成する。
14:出力されたディレクトリをチェックする。
言語モデルに対して重み付き状態変換器の作成を行う
cat $lmdir/lm.arpa | \
grep -v '<s> <s>' | \
grep -v '</s> <s>' | \
grep -v '</s> </s>' | \
arpa2fst - | fstprint | \
utils/remove_oovs.pl $tmpdir/oovs.txt | \
utils/eps2disambig.pl | utils/s2eps.pl | fstcompile --isymbols=$test/words.txt \
--osymbols=$test/words.txt --keep_isymbols=false --keep_osymbols=false | \
fstrmepsilon | fstarcsort --sort_type=ilabel > $test/G.fst
fstisstochastic $test/G.fst
空文字に対してもfstファイルを作成する
awk '{if(NF==1){ printf("0 0 %s %s\n", $1,$1); }} END{print "0 0 #0 #0"; print "0";}' \
< "$lexicon" >$tmpdir/g/select_empty.fst.txt
fstcompile --isymbols=$test/words.txt --osymbols=$test/words.txt \
$tmpdir/g/select_empty.fst.txt | \
fstarcsort --sort_type=olabel | fstcompose - $test/G.fst > $tmpdir/g/empty_words.fst
fstinfo $tmpdir/g/empty_words.fst | grep cyclic | grep -w 'y' &&
echo "Language model has cycles with empty words" && exit 1
rm -rf $tmpdir
これでデータ準備は終了です。
次からはデータからの特徴量抽出に入ります。