音声や言語処理のコーパスに関しては比較的まとまっている資料がネット上に転がっているが対話に関しては少ないのでまとめてみた。
対話の場合も音声や言語と同じで大量のデータが必要!!!
しかも特定のドメインに特化した方が良いってことになるとなかなか見つけづらい(汗
そこで対話コーパスの集め方をまとめた
模擬対話実験(人手)
音声対話システムを実装するのに理想なデータ=実際にシステムと対話しているデータ
これを作成するには
ユーザー役
オペレーター役
を用意して模擬対話を行ってもらうのが一番早い!!!
条件は細かく設定
ケース1
現状:京都駅周辺
目的:烏丸御池周辺の用事を済ましてから夕食を取る
知りたい情報:車で現在地から烏丸御池周辺でレストランまで行くのに必要な情報
実際のデータ収集方法
Wizard if OZ法を使用
ユーザー役があたかも機械と対話しているように錯覚するような状況を作り出して、データ収集する。
オペレーター(機械)がGUIを用いて応答文を瞬時に作成し、音声合成を用いて応答する。
オペレーターがユーザーの声を聞いて答える場合
音声認識を介してオペレーターが答える場合
上記の2種類がある。
#機械を用いて学習データを集める手法
1:Wizard if OZ法を用いてデータを集める
2:集まったデータのうち、確信度の高いデータの認識データを用いて言語モデルを学習
3:学習語のモデルでデータ収集を繰り返す
(4:確信度の低いデータ、識別器の判別結果が低いデータを選別してラベル付し、それらを学習データとして使用する)
ユーザーの動機付けも大事:理由はユーザーが本当に欲しい答えを求めたり、返答に困ったりすることが少なくなり、質の高い情報を取得できるため。
音声対話コーパスを機械学習に用いるには
収集したコーパスを機械学習のデータに用いるには、音声データに様々な情報付与が必要
1:音声データの書き起こし
自由対話は書き起こし単位を決めるのが難しい
「談話・対話研究におけるコーパス利用研究グループ」(http://www.slp.is.ritsumei.ac.jp/dtag/JP/
)によると明確な話者交代や400ms以上の無音区間で発話を区切り、発話の重なりはその起こった位置を先行発話側の該当文字にマーキングし、次の発話区切りとして記述。
2:音声対話データのタグ付
音声対話のデータは様々な目的で使用されるため、データに情報を付与する必要がある。
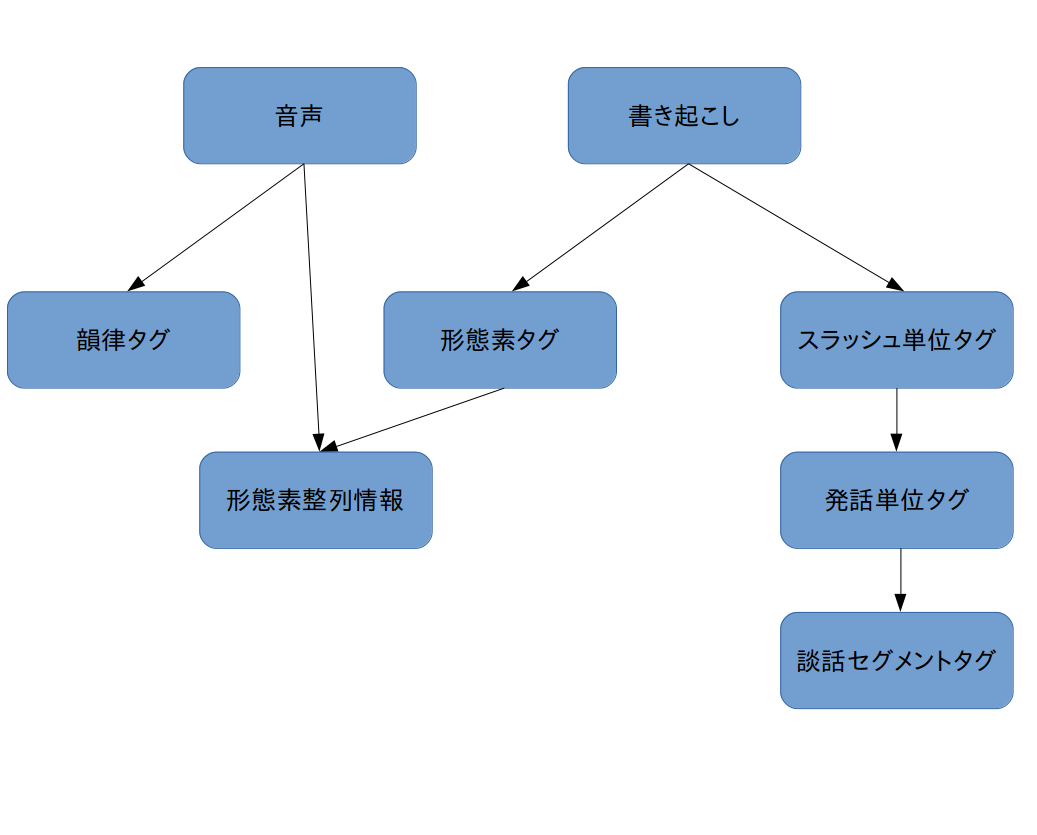
スラッシュ単位:
物理的な区切り(発話の交代や発話の休憩)と論理的な単位は必ずしも一致しない。
そこで文に対するまとまりを示したものを論理的単位として、発話単位タグを付与する。
**同一話者において句点で区切ることが可能と考えられる連続発話
**言いさし、言い間違い、相手の割り込みによって発話が中断し、次の同一話者の発話に継続していない音声的連続
発話中の非文要素についてもタグ付を行う
**あいづち
**接続標識
**フィラー
**言い誤り
**非音声
**ポーズ
形態素タグ
転記テキストに基づいて付与される品詞ラベル、各単語の開始、終了とともにラベリングされる
発話単位の機能タグ
それぞれのスラッシュ単位が対話の中でどのような機能を果たしているかどうか情報を付与するもの
**<対話開始><対話終了>
**<働きかけ>:やりとりを開始する機能
**<応答>:働きかけに対する応答
**<了解>:やりとりを締めくくる
**<応答/働きかけ>:応答と働きかけの両方の機能をもつ
関連性タグ
発話単位タグでは構造を上手く表現できない「やりとり」間の関係などの対話の中位構造を表現するためのタグである。
関連性1:「働きかけー応答」
応答発話に対して、それを引き出した働きかけの発話の単位番号付与
例:「質問―答え」、「 挨拶―返答」、「 依頼―受諾または拒否」
関連性2:「隣合う複数のやりとり」
働きかけ発話に対して、先行のやりとり構造との関連の有無を「関係有り・関係無し」のいずれかで付与
例:
談話セグメントタグ
働きかけタイプの発話の前に付与されるタグ
TBI:前後の内容の関連性が強ければ1、そうでなければ2を付与
話題名:どのような話題が付与されているか
セグメント情報:話題の遷移に関する情報を必要に応じて記述「聞き返し」「割り込み」「復帰」
参考
対話コーパスをクラウドを使って集める場合の事例