この記事のゴール
lstmを高速に学習させたい人向け
おまけ
Kerasに関する書籍を翻訳しました。画像識別、画像生成、自然言語処理、時系列予測、強化学習まで幅広くカバーしています。
直感 Deep Learning ―Python×Kerasでアイデアを形にするレシピ
早く試したい人へ
kerasを2.0.8以上にアップグレードすれば使用できます。
pip install git+https://github.com/fchollet/keras.git
使用方法
model = Sequential()
model.add(CuDNNLSTM(hidden_number))
結果
参考記事によるとベースラインに比べ11倍程度早くなるそうです。
下記の記事はcuDNN5の記事なので注意が必要です。
Optimizing Recurrent Neural Networks in cuDNN 5
下記ではcuDNN6に比べ、cuDNN7の方が3倍ほど早くなっています。
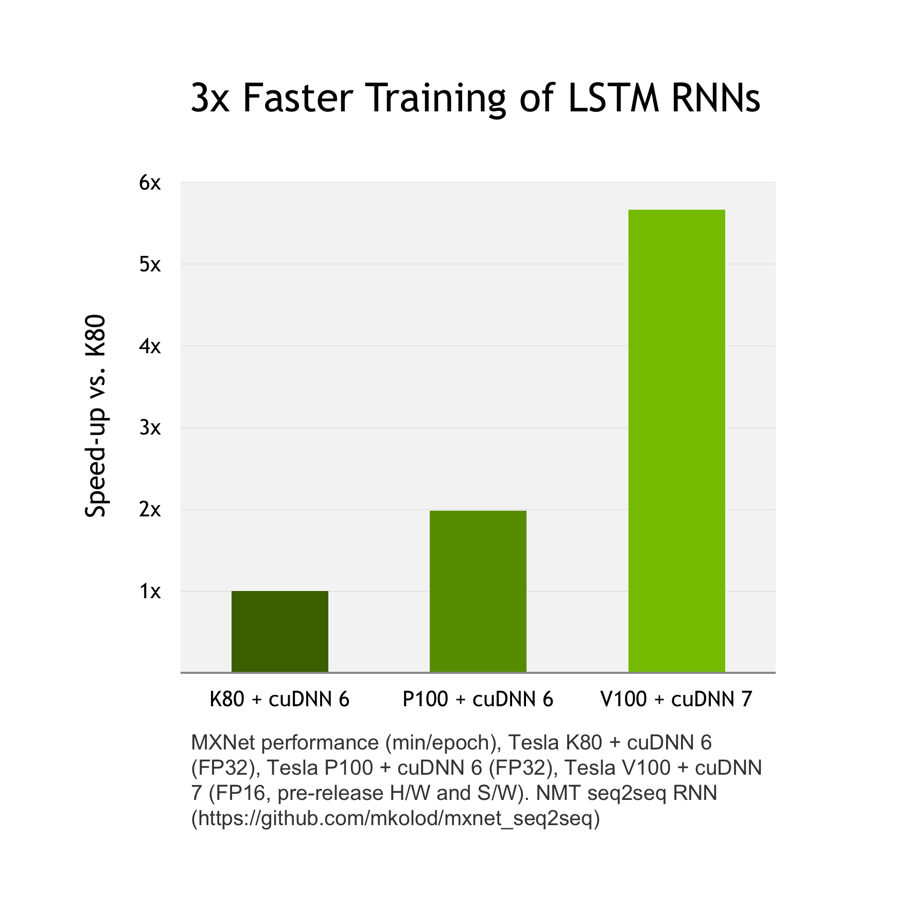
詳細
GPU上でしか動作しませんが使用方法はとても簡単です。
functional api形式で記述すると下記のようになります。
x = CuDNNLSTM(hidden_number)(x)
注意点:
- TensorboardのEmbeddingsによる可視化には対応していません。
- Dropoutにも対応していません。
- Bidirectionalで使用する時はいくつかコメントアウトして使用する必要があります。
通常のLSTMとの違いは下記の処理です。
下記に詳細がありますがcuDNNLSTMは生成と生成の間でバファーのサイズが変更される可能性があります。そのため重みとバイアスを保存して使用する必要があるためです。
params = self._canonical_to_params(
weights=[
self.kernel_r,
self.kernel_z,
self.kernel_h,
self.recurrent_kernel_r,
self.recurrent_kernel_z,
self.recurrent_kernel_h,
],
biases=[
self.bias_r_i,
self.bias_z_i,
self.bias_h_i,
self.bias_r,
self.bias_z,
self.bias_h,
],
)
Tensorflowには下記のようにパラメーターを保存する仕組みがあります。
RNNParamsSaveable
高速化の仕組み
上記の方法で使用可能です。
ここからはcuDNNがどのようにしてLSTMを高速化しているか見ていきます。
Optimizing Recurrent Neural Networks in cuDNN 5
単一のイテレーションの最適化
COMBINING GEMM OPERATIONS
GEMMという行列のオペレーションがあります。GPUの特性上、並列性を上げればあげるほど高速になります。
入力されるのは下記の4つであり、重みも各入力ごとに存在します。
- 入力
- 出力
- 忘却ゲート
- 以前の出力
8つのパラメータに対して、それぞれ行列で値が存在することになります。
通常の入力ステップで4つの重み行列を1つに合わせる
再機処理ステップで4つの重み行列を1つに合わせる
行列一つずつを処理した場合は8つの行列演算が必要ですが、これによって2つの行列で動作可能です。
出力行列は16倍になります。
これによって下記に示されるcudaの並列性を効果的に扱えるようになり、計算速度が2倍程度になるようです。
STREAMING GEMMS
下記のようにスレッド形式で並列に行列演算が可能なのでその機能を使用します。

FUSING POINT-WISE OPERATIONS
下記のようにカーネルが別れるのでこれをまとめて処理することにグローバルメモリーとのオーバーヘッドが減り、5倍程度高速に!!

Optimizing Many Iterations
今まで個別処理の最適化でした。ここからはRNN特有の何度もイテレーション処理をするのでその部分の最適化になります。
PRE-TRANSPOSING THE WEIGHT MATRIX
重み行列を予め転置しておくことで標準のBLAS APIでの各行列演算処理の負荷を若干減らせます。転置のコストの方が各行列演算処理に置いて転置するよりも低コストです。
COMBINING INPUT GEMMS
入力のサイズをRNNのハイパーパラメータによって最適化する。入力全てを使用する方が一見、並列性が高いですが、データによって入力のサイズが異なるため一概に全てを使用することが好ましくないのでこのような処理を行います。
Optimization with Many Layers
RNNは前のレイヤーの値と一つ前の値に依存するため、その処理が終わったものは並列処理可能。下記の図だと赤の部分
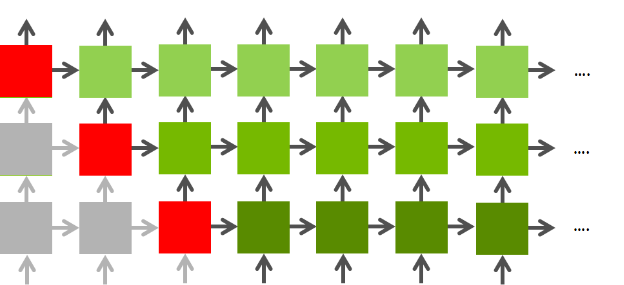
結果
下記のような結果になります。
| Optimization | GFLOPS | Speedup |
|---|---|---|
| Baseline | 349 | (1.0x) |
| Combined GEMMs | 724 | 2.1x |
| GEMM Streaming | 994 | 2.8x |
| Fused point-wise operations | 1942 | 5.5x |
| Matrix pre-transposition | 2199 | 6.3x |
| Combining Inputs | 2290 | 6.5x |
| Four layers | 3898 | 11.1x |
参考
Optimizing Recurrent Neural Networks in cuDNN 5