音声対話システムは個々のシステムの評価とシステム全体の評価があり、的確に評価をするのが難しい。
そこで下記の資料を参考に音声対話システムの評価法をまとめた。
システム個々の評価
音声認識、言語理解は答えを用意して評価
音声認識部:文認識率、単語認識率
言語理解部:意味理解率、意味スロット認識率
システム全体の評価
1:対話ログなどを用いた客観的な評価
メリット:大規模にタスク達成率、平均ターン数によってシステムの状態や効率を評価可能
デメリット:タスクの達成率の定義が難しい。
2:ユーザーアンケートによる主観評価
メリット:ユーザーの満足度を直接図れるので、タスク達成率、平均ターン数では捉えきれない要因を探れる
デメリット:大規模に行うことが難しい。
その他の評価の試み
シミュレーションによる評価方法
ユーザーの振る舞いを模擬するシミュレーションを作成、シミュレーターと対話システムのログを収集して性能を評価
音声対話システムに適用するためにシミュレーターが出力する文に乱数で誤認識と生じさせたり、実際の録音音声を用いる手法
ユーザー満足度の分析的な評価手法
PARADISEというフレームワーク
目的:ユーザー満足度を最大化
タスク達成率を最大化し、対話に伴うコストを最小化
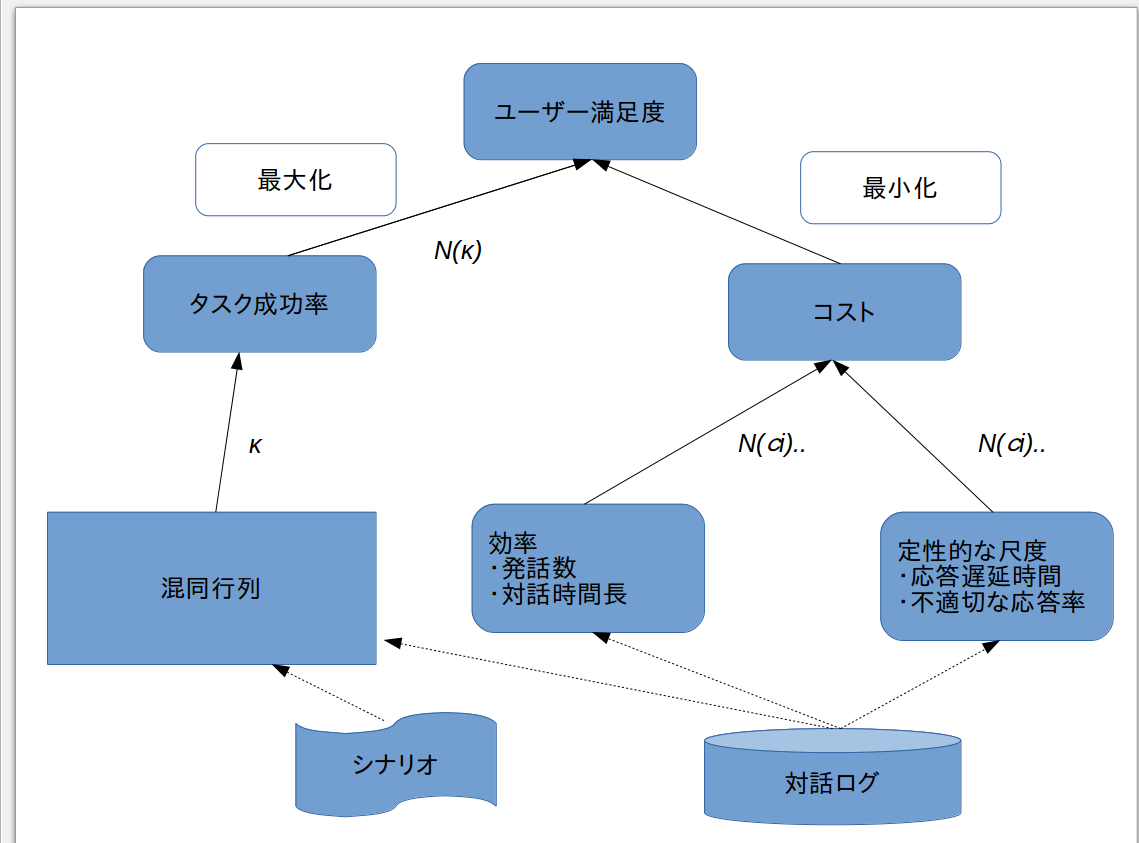
1:タスク達成率をタスクのシナリオと実際に行われた対話ログを比較することによって作成された属性・値の混同行列から得る。
混同行列を算出する手順

上記のようなタイムテーブルドメインにおいて、
下記のようなエージェントの会話を100回行ったとき
エージェントA

エージェントB
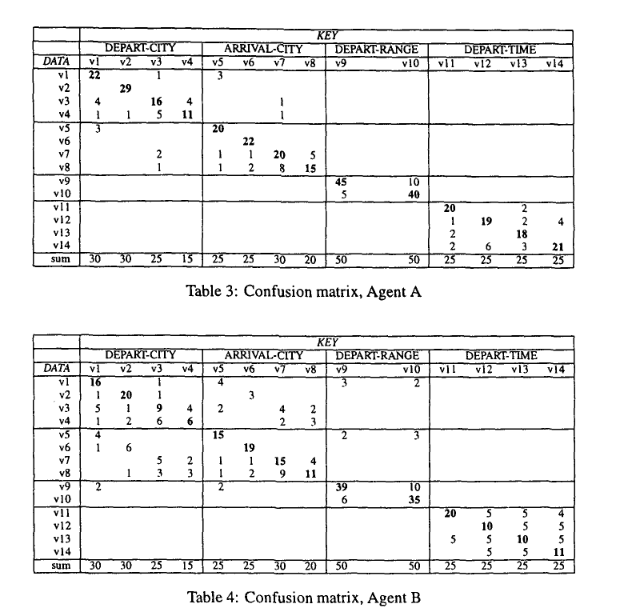
下記の図はKEYの値が
DEPART CITYの”Milano,Roma,Torino,Trento”の4つのラベルが何回観測されたか
同様に
ARRIVAL CITYの”Milano,Roma,Torino,Trento”の4つのラベルが何回観測されたか
DEPART RANGEの”morning,evening”の2つのラベルが何回観測されたか
DEPART TIMEの”6am,8am,6pm,Spm”の4つのラベルが何回観測されたか
を各値において表している。
TはM(t1...tn)の和
tiは各列の総頻度
iは各列を表す
各キーにおいてどれだけ値が一致したかを判断する指標
\begin{aligned}
P(E) & = \sum_i^n (\frac{t_i}{T})^2 \\
\end{aligned}
M(i,i)は対角線上の値
シナリオのキーとの一致率
\begin{aligned}
P(A) & = \frac{\sum_i^nM(i,i)}{T} \\
\end{aligned}
タスクの達成率は混同係数で計測される。
\begin{aligned}
κ & = \frac{P(A) - P(E) }{ 1 - P (E) } \\
\end{aligned}
2:コストを対話ログから
発話数、総対話時間のような効率性を測る要素
応答遅延、不適切応答率のような対話の質
得る
3:上記のタスク達成率とコストに正規化関数をかけ、平均0、標準偏差1に揃える
4:アンケートによって得られたユーザーの満足度と上記のようにして得られた各種の要因に対して重回帰文s系を行い、ユーザー満足度に寄与する重みを求める。
\begin{aligned}
Performance & = (a * N (k))-\sum w_i * N(c_i) \\
\end{aligned}
これによって、どの要因が最もユーザー満足度を高めるのに寄与しているか分かるとともに、対話戦略の変更などによる全体的なシステムの質の工場が客観的な尺度で評価できるようになる。
参考
http://www.aclweb.org/anthology/P97-1035