はじめに
ポケットモンスターウルトラサンウルトラムーン(USUM)ではAボタンを連打するだけで色違いに遭遇することができる方法がある。詳しくは参考動画、参考記事を参照。これらの方法では人間が色違いの出現を確認するまでAボタンを連打する必要がある。今回はこれを自動化したい。
装置概要
大事なのは2点。色違いの出現をいかに認識するかとAボタンを連打する機構。
Aボタン連打機構
方法は大きく分けて2通りあって、モーターを使う方法とソレノイドを使う方法がある。今回はモーターを使う方法を採用。ソレノイドを使う場合、ボタンを押してから戻すまでのdelay時間分だけプログラムが止まる。止まらないような書き方もできるはずだけどモーターを使う方が簡単な気がする。ただ、モーターを使う場合はヘッド部分を工作しないといけないので結局一長一短かな。
ヘッド部分は上記リンクみたいにただの棒でもよいが、写真みたいに樹脂ベアリングをつけた方がボタンに優しい。

| 部品 | 品番 |
|---|---|
| フレーム | タミヤ 楽しい工作シリーズ No.156 |
| ベアリング | TOK DR-19-B0.5 |
| ベアリング取り付け箇所にはタップ加工が必要。側面にイモネジつけないと空回るので注意。 |
色違いの認識
考えられる方法は大きく分けて二つあり、画像認識か音声認識のどちらかになる。画像認識は難しそうなので音声認識を採用した。3DSにはライン出力端子があるのでこれをUSB DACを介してラズパイに取り込む。この時点で音声認識ではなく音声データ認識になってしまうが、今回は良しとしよう。連打機構の動作音があるのでマイクで音拾うのは現実的でない。
色違いポケモンの出現時には"キラーン"って感じの効果音が鳴るのでこれを検知することを目標にする。つまりサンプリングしたデータの中に"キラーン"音があるかないかの二値分類問題に帰着させる。ありとなしのそれぞれの代表データを事前に用意しておいてそれらとサンプリングしたデータとの類似度比を使って分類した。機械学習?そんなもんは知らん。
まず下図のイメージでデータの下処理。
Aボタンを押して技選択してからポケモンが出てくるまでラグがあるのでボタン連打を止めてからもサンプリングを続ける必要がある。EXTEND TIMEはその時間。"キラーン"音が2sぐらいの長さなのでそれを単位時間とし、サンプリングしたデータを分割する。分割の際は"キラーン"音を切ってしまわないようにオーバーラップさせる。

下の式みたいなので状態を判別する。予めサンプリングしておいた"キラーン"音を含むデータ("kira sound")と判別したいデータのFFTスペクトルのコサイン類似度が大きければ色違い出現と判定する。"dummy sound"は色違いでないポケモンが出現したときのデータ。"キラーン"音を含むデータには必ずゲームBGMがコンタミしているので複数データの平均を取り、BGM成分の影響を小さくする(という意図で平均化したが実際にそれが結果に貢献しているかは謎)。ポケモン出現時の鳴き声も必ずコンタミしてくるが、上手い対策が見つからなかったので放置した。
max \left\{ \dfrac {FFT(D) \cdot \overline {FFT("kira" sound)}}{FFT(D) \cdot \overline {FFT(dummy\ sound)}}\right\}
全体像
ここまでの内容をもとに下の図のような装置を製作した。
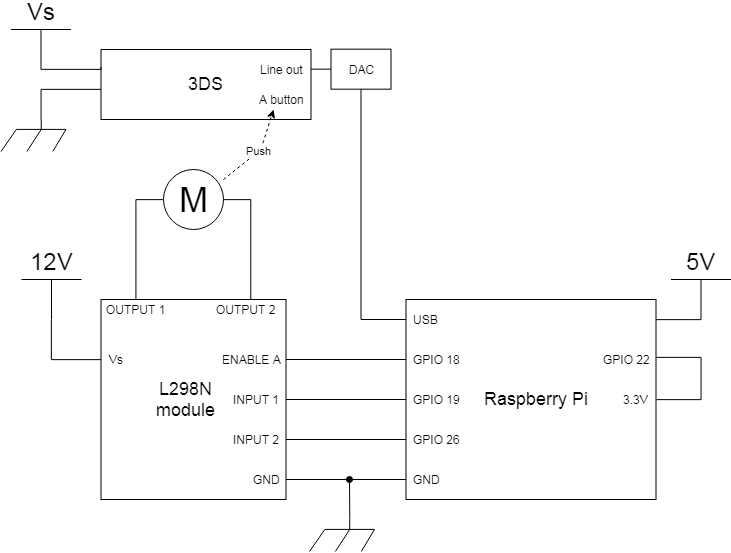
| ラズパイ | Raspberry Pi 3 Model B |
| モータードライバ | 中華のノーブランド(たぶんこの方と同じ) |
| ギアードモーター | 中華のノーブランド 12V 60RPM |
| USB DAC | ugreen usb オーディオ 変換アダプタ |
| モータードライバとラズパイGPIOのGNDを繋がないと動かないので注意。ICのロジック電圧は5VのはずだけどなんかラズパイGPIOの3.3Vでも動いた。 | |
| システムの動作環境は下表。 |
| 環境 | |
|---|---|
| ラズパイ | Raspberry Pi 3 Model B |
| OS | Raspbian GNU/Linux 9.4 (stretch) |
| python | conda 4.5.11 (Python 2.7.13) |
代表データの収集と解析用コード。データ収集のために任意のタイミングで色違いを出現させる必要があるが、バトル中に手持ちの色違いと自分が出してるポケモンとを交換すれば可能である。下のスクリプトはキーボードで何か入力すると録音開始する仕様になっているのでポケモン交換と上手くタイミングを合わせる。今回はデータ数を10とした。また、このデータは厳選したいポケモンと別のポケモン、つまり別の鳴き声を持つポケモンを使ってサンプリングした。
# -*- coding: utf-8 -*-
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16 # int16型
CHANNELS = 1 # モノラル
RATE = 44100 # 441.kHz
RECORD_SECONDS = 2 # 2秒録音
input_device_index = 2
WAVE_OUTPUT_FILENAME = "sound_data" #あるいは "dummy_data"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
input_device_index = input_device_index,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
def rec():
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
return frames
def write(frames, WAVE_OUTPUT_FILENAME):
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
def end():
stream.stop_stream()
stream.close()
p.terminate()
def serial_rec(file, index):
"""ボタン押すたびに録音して保存を繰り返す"""
for i in index:
a = input('waiting input... >>')
write(rec(), file+str(i)+'.wav')
if __name__ == '__main__':
serial_rec(WAVE_OUTPUT_FILENAME,range(0,9))
# -*- coding: utf-8 -*-
"""wave読み込んでFFTして、平均化して保存"""
import wave
import numpy as np
RATE = 44100
def wave_read(file):
wf = wave.open(file, 'rb')
data = np.frombuffer(wf.readframes(wf.getnframes()), dtype='int16')
wf.close()
return data
dummy_data = np.array([wave_read('dummy_data' +str(i) +'.wav') for i in range(0,10)])
sound_data = np.array([wave_read('sound_data' +str(i) +'.wav') for i in range(0,10)])
dummy_fft = np.array([np.abs(np.fft.fft(data)) for data in dummy_data])
sound_fft = np.array([np.abs(np.fft.fft(data)) for data in sound_data])
dummy_mean = np.mean(dummy_fft, axis=0)
sound_mean = np.mean(sound_fft, axis=0)
np.savetxt('dummy_mean.csv', dummy_mean, delimiter=',')
np.savetxt('sound_mean.csv', sound_mean, delimiter=',')
pyaudioの使い方はこちらを参考にさせて頂いた。
下はメインのコード。
# -*- coding: utf-8 -*-
import numpy as np
import pyaudio
import wave
import atexit
import RPi.GPIO as GPIO
import os
import sys
TIME = 4 #録音時間
UNIT_TIME = 2 #分割の単位時間
EXTEND_TIME = 8 #ボタン押さずに録音する時間
SOUND_FILE = 'sound_mean.csv' # "sound data"
DUMMY_FILE = 'dummy_mean.csv' # "dummy data"
THRESHOLD = 0.97 #判定閾値
# Pyaudio設定
CHUNK = 1024
FORMAT = pyaudio.paInt16 # int16型
CHANNELS = 1 # モノラル
RATE = 44100 # 441.kHz
input_device_index = 2
# GPIO設定
PIN = 18
INPUT_PIN1 = 19
INPUT_PIN2 = 26
DUTY = 40
PWM_FREQ = 1000
GPIO.setmode(GPIO.BCM)
class Renda():
"""連打機制御 onで動きoffで止まる"""
def __init__(self, pin, duty):
self.pin = pin
self.duty = duty
self.input1 = INPUT_PIN1
self.input2 = INPUT_PIN2
GPIO.setup(pin, GPIO.OUT)
GPIO.setup(self.input1, GPIO.OUT)
GPIO.setup(self.input2, GPIO.OUT)
self.pwm = GPIO.PWM(pin, PWM_FREQ)
GPIO.output(self.input1, 1)
GPIO.output(self.input2, 0)
def on(self):
self.pwm.start(self.duty)
def off(self):
self.pwm.stop()
def end(self):
self.pwm.stop()
GPIO.cleanup()
def recording(stream, time):
#print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * time)):
data = stream.read(CHUNK, exception_on_overflow = False)
frames.append(data)
#print("* done recording")
return frames
def kira_exists(wav, sound, dummy):
"""判定式"""
data = b''.join(wav)
data = np.fromstring(data, dtype=np.int16)
k = RATE * UNIT_TIME
data_split = np.array( [ data[i:(i+k)] for i in range(0, len(data)-k+2, k/2)])
data_fft = np.array([np.abs(np.fft.fft(d)) for d in data_split])
judg_val = data_fft.dot(sound)/data_fft.dot(dummy)
print(', '.join(['{0:.4f}'.format(i) for i in judg_val]))
sys.stdout.flush()
if np.max(judg_val) > THRESHOLD:
print("発見")
return True
else:
return False
def write_wave(p, wav):
wf = wave.open('log.wav', "wb")
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(wav))
wf.close()
def setup():
GPIO.setup(22, GPIO.IN, pull_up_down=GPIO.PUD_DOWN)
if GPIO.input(22) == 1:
print("GPIO22 is High")
else:
print("GPIO22 is LOW")
exit()
pass
def main_loop():
setup()
renda = Renda(PIN, DUTY)
sound = np.loadtxt(SOUND_FILE, delimiter = ",", dtype = float)
dummy = np.loadtxt(DUMMY_FILE, delimiter = ",", dtype = float)
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
input_device_index = input_device_index,
rate=RATE,
input=True,
#output=True,
frames_per_buffer=CHUNK)
atexit.register(end, renda, p, stream)
#メインループ kiraを検出するまでAボタンを押し続ける
while True:
renda.on()
data = recording(stream, TIME)
renda.off()
data = data + recording(stream, EXTEND_TIME)
if kira_exists(data, sound, dummy):
break
renda.off()
if GPIO.input(22) == 1:
end(renda, p, stream)
os.system('sudo shutdown -h now')
else:
end(renda, p, stream)
def end(renda, p, stream):
stream.stop_stream()
stream.close()
p.terminate()
renda.end()
if __name__ == '__main__':
main_loop()
実行シェル。作るまでもないけど。誤検知で止まったときと、ずっと止まらないときはlogを確認してTHRESHOLDを調整する。
# !/bin/bash
cd ~/python
nohup python irochigai.py 1> 191212.log 2>&1 &
使用した結果
無事色違いと出会うことができた。やったぜ。
ログを見た感じだと色違いに出会うまでに1000〜2000回程度の試行をしたみたい。これは色違いが出る確率が約0.3%であることを考慮するとちょっと多いので恐らく見逃して倒してしまってるのが何回かあると予想される。また、数時間(200〜300試行)おきに誤検知で止まってしまうので、出会うまでに数日かかった。止まるたびにちょびちょびTHRESHOLDを上げていくのがコツ。
仕組みが単純なので固定シンボルのリセット厳選とかにも応用できるはず。新作でも仲間呼び連鎖ができたらよかったのになあ。