はじめに
人間の行動を理解することは、厄介で注意を要する作業です。ある状況下で人がどのように行動するのか、どのような判断を下すのかを説明するのは簡単ではありませんし、単純でもありません。しかし、人を観察し、次に何をするかを予測しようとすることは、真の学習経験を提供します。それは、より良い結果を得るために、十分な情報を得た上で意思決定を行うのに役立ちます。
人間の性質を予測することが有益な場面のひとつに、ギャンブルがあります。例えば、ポーカーゲームでは、様々な状況下でプレイヤーがなぜレイズ、コール、フォールドするのかを理解することで、競争において明確なアドバンテージを得ることができます。このプロジェクトでは、ギャンブラーのためのオンラインプラットフォームである Bustabit のデータを使用します。
ゲームのルールは以下の通りです。
- ビットコインの100万分の1であるBitsで任意の金額を 「ベット」 することができます。
- ゲームが終了する前にキャッシュアウトすれば勝ちとなります。
- キャッシュアウト時に、その時点のマルチプライヤーの値に応じて勝敗が計算されます。
- ゲームごとの 「ボーナス」 の割合がお客様のベットに適用され、最終的な勝ち額または勝ちゲームでの 「利益」 に合計されます。
大量のデータを保存するためにGridDBを使用し、リアルタイムにデータにアクセスし、高速な処理を行う予定です。
GridDBを使ったデータセットのエクスポートとインポート
GridDBは、高いスケーラビリティと最適化を実現したインメモリNoSQLデータベースで、特に時系列データベースにおいて並列処理による高いパフォーマンスと効率性を実現します。今回はGridDBのpythonクライアントを使用します。そうすることでGridDBとpythonを接続し、リアルタイムにデータのインポートやエクスポートを行うことが可能になります。
ライブラリ
いくつかのpythonライブラリを使用して、データの前処理と視覚的な分析を行う予定です。
- Pandas:特にデータフレームを扱う際に多用されるPythonライブラリ
- Matplotlib:基本的なプロットを用いてデータを視覚的に表現するための主要なライブラリ
- Numpy:高度な数学的計算を行うためのライブラリ
- Sklearn:プロジェクトで使用するクラスタリングアルゴリズムが含まれるライブラリ
前処理
data = pd.read_csv("bustabit.csv")
データセットがデータフレームの形で変数 "data" に保存されました。
今回の分析をより分かりやすくするために、データセットのいくつかのカラムを調整します。'ID' カラムは、データベースの主キーとして機能する新しいカラムに置き換える予定です。また、'PlayDate' を 'Year' に置き換えます。このプロジェクトでは、時間に関する更なる情報を必要としない為です。
data = data.drop(["Id"], axis = 1)
data.reset_index(drop=True, inplace=True)
data.index.name = 'ID'
data['Year'] = pd.DatetimeIndex(data['PlayDate']).year
data = data.drop('PlayDate', axis = 1)
これらは、分析に使用するデータフレームに残っている列です。
- ID:当データベースの主キー
- GameID:バスタビットのゲームに関連する一意のID
- Username:プレイヤーがバスタビットのプラットフォームで使用する固有の名前
- Bet:このゲームでプレイヤーがベットしたビット数
- CashedOut - このプレーヤーがキャッシュアウトしたときの倍率
- Bonus - このプレイヤーがゲーム中に獲得したボーナス報酬(単位:%)
- Profit - このプレイヤーがゲームで獲得した金額(ボーナスを含む)
- BustedAt - このゲームが破綻したときのマルチプライヤーの値
- Year - ゲームが行われた年
GridDB にデータベースをエクスポートする前に、データセットに存在する NULL 値を処理する必要があります。以下のルールで NULL 値を置き換えます。
- CashedOut - 'CashedOut'の値がNAの場合、ユーザーがバストの前にキャッシュアウトできなかったことを示すために、'BustedAt'の値より0.01大きくなるように設定します。
- Profit - Profitの値がNAの場合、そのゲームでのプレイヤーの利益がないことを示すために0に設定されます。
- Bonus - Bonusの値がNAの場合、そのゲームではプレイヤーにボーナスがなかったことを示すため、0に設定します。
data = data.assign(CashedOut = np.where((data['CashedOut'].isnull()),data['BustedAt'] + .01, data['CashedOut']))
data = data.assign(Profit = np.where((data['Profit'].isnull()), 0 , data['Profit']))
data = data.assign(Profit = np.where((data['Bonus'].isnull()), 0 , data['Bonus']))
データの前処理が完了したので、今度はデータをローカルドライブに保存します。
data.to_csv("preprocessed.csv")
データセットをGridDBに書き出す
GridDBにデータセットをアップロードするために、前処理されたデータを含むCSVファイルを読み込むことになります。
data_processed = pd.read_csv("preprocessed.csv")
ここで、GridDBコンテナを作成して、データベーススキーマをGridDBに渡し、行情報を挿入する前に、データベースのデザインを生成できるようにします。次に、GridDBにデータを挿入します。
#Create container
data_container = "data_container"
# Create containerInfo
data_containerInfo = griddb.ContainerInfo(data_container,
[["ID", griddb.Type.FLOAT],
["GameID", griddb.Type.FLOAT],
["Username", griddb.Type.STRING],
["Bet", griddb.Type.FLOAT],
["CashedOut", griddb.Type.FLOAT],
["Bonus", griddb.Type.FLOAT],
["Profit", griddb.Type.FLOAT],
["BustedAt", griddb.Type.FLOAT],
["Year", griddb.Type.INTEGER]],
griddb.ContainerType.COLLECTION, True)
data_columns = gridstore.put_container(data_containerInfo)
print("container created and columns added")
# Put rows
data_columns.put_rows(data_processed)
print("Data Inserted using the DataFrame")
これで、GridDBプラットフォームへのデータセットのエクスポートに成功しました。
GridDBからデータセットを読み込む
GridDBプラットフォームからデータセットを取り込むために、SQLに似たGridDBのクエリ言語であるTQLを使用することにします。コンテナを作成し、その中に取り込んだデータを格納します。
# Define the container names
data_container = "data_container"
# Get the containers
obtained_data = gridstore.get_container(data_container)
# Fetch all rows - language_tag_container
query = obtained_data.query("select *")
次のステップは、列情報の順に行を抽出してデータフレームに保存し、データの可視化と分析に使用することです。
# Convert the list to a pandas data frame
data = pd.DataFrame(retrieved_data, columns=['ID', 'GameID',"Username",
"Bet","CashedOut" ,"Bonus", "Profit","BustedAt","Year"])
これでデータがpandasのデータフレーム "data" に保存され、引き続きプロジェクトに使用できるようになりました。
データ分析
我々は、Kmeansクラスタリングアルゴリズムを使用して、プレーヤーを5つの異なるセットにクラスタリングする予定です。我々は、データセットをよりよく理解するために、3つの新しいカラムを導入することから始めます。新しいカラムは以下のルールに基づくものです。
- Losses - 利益の新しい値がゼロの場合、そのゲームでプレイヤーが失った金額を設定します。そうでない場合は、ゼロに設定します。この値は常にゼロかマイナスであるべきです。
- GameWon - このゲームでユーザーが利益を得た場合、値は1であり、そうでない場合は0である必要があります。
- GameLost - ユーザがこのゲームで負けた場合は 1、そうでない場合は 0 とする。
data = data.assign(Losses = np.where((data['Profit'] == 0 ), - data['Bet'], 0))
data = data.assign(GameWon = np.where((data['Profit'] == 0 ), 0 , 1))
data = data.assign(GameLost = np.where((data['Profit'] == 0 ), 1, 0))
条件を使ってデータをフィルタリングし、特定の行を見てみましょう。
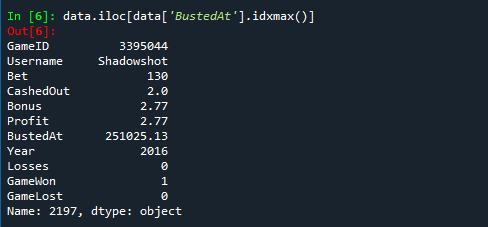
1. 最も高い倍率: 'BustedAt' の値が最も高いゲームとユーザーの詳細
data.iloc[data['BustedAt'].idxmax()]
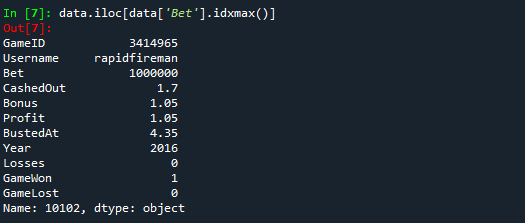
2. 最高ベット額: 最も高額なベット額のゲームとユーザーの詳細
data.iloc[data['Bet'].idxmax()]
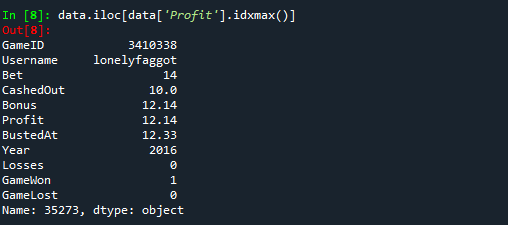
3. 最も高い利益: 最も高い利益を得たゲームとユーザーの詳細
data.iloc[data['Profit'].idxmax()]
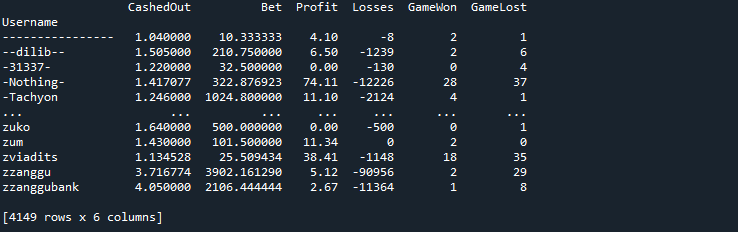
次に、「ユーザー名」を使ってデータをグループ化し、Bustabitでのギャンブル履歴を通じて、各ユーザーの収益、勝ち、負けを特定します。これにより、各ユーザーのギャンブル習慣を特定し、プレイヤーグループ間の関係や類似性をより理解することができます。
data_groupby = data.groupby('Username').agg({'CashedOut': 'mean',
'Bet': 'mean',
'Profit': 'sum',
'Losses': 'sum',
'GameWon': 'sum',
'GameLost': 'sum'})
今、データはこのようになっています。
クラスタ形成に移る前に、まず、データセット全体のデータを標準化しようと思います。これはデータセットを標準的な測定単位に変換し、我々のアルゴリズムをより効率的にするものです。標準化関数を作成し、データセットの各数値列に適用します。
def standardization_function(x):
return (x-np.mean(x)/np.std(x))
bustabit_standardized = data_groupby.apply(lambda x: standardization_function(x)
if ((x.dtype == float) or (type(x) == int))
最後のステップは、sklearnライブラリを使って、選手のクラスターを5つのセットに分けることです。
kmeans = KMeans(n_clusters=5, random_state=0).fit(bustabit_standardized)
clustering_data = pd.DataFrame()
clustering_data['cluster'] = kmeans.predict(bustabit_standardized)
ここで、私たちのデータを5つのクラスターに分けたものを垣間見ることができます。
summary = clustering_data.groupby("cluster").mean()
summary['count'] = clustering_data['cluster'].value_counts()
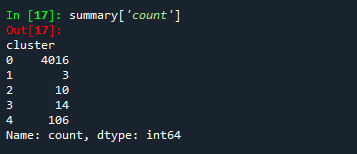
結論
プロジェクトの最終結果を見ると、ほとんどのプレイヤーが同じような属性を持ち、同じクラスタリンググループに属する一方で、標準的な行動とは異なるプレイヤーの例外はごくわずかであると結論付けることができます。すべての分析は、バックエンドでGridDBデータベースを使用して行われたため、統合はシームレスかつ効率的に行われました。