今回は、小惑星が地球にとって危険かどうか、つまり、軌道を外れて地球に降り、住民に危害を加えるかどうかを科学者がどのように判断しているかをGridDBを使って解析してみます。
ソースコードの全文はこちらでご覧いただけます。
https://github.com/griddbnet/Blogs/tree/asteroids_distance
GridDBを使ったデータセットのエクスポートとインポート
GridDBは、高いスケーラビリティと最適化を実現したインメモリNo SQLデータベースで、特に時系列データベースにおいて、より高いパフォーマンスと効率性を実現するための並列処理を可能にします。今回はGridDBのnode jsクライアントを使用し、GridDBとnode jsを接続し、リアルタイムにデータをインポートまたはエクスポートすることができます。
これらは、我々のデータセットに存在する列です。
- id : NASAの科学者がつけた小惑星のID。
- new_name : NASAの科学者がつけた小惑星の名前。
- est_diameter_min : 小惑星の最小推定直径。
- est_diameter_max : 小惑星の推定最大直径。
- relative_velocity : 小惑星の地球に対する相対的な速度のこと。
- miss_distance : 小惑星の地球からの距離。
- orbiting_body: 小惑星が特定の天体の周りを公転すること。
- sentry_object: 小惑星が宇宙空間で他の天体(人工衛星など)に衝突したかどうか。
- absolute_magnitude: 質量比によって地球に衝突する力の大きさ。
- hazardous : 小惑星は危険な範囲にあるのか?(成果変数)
GridDBにデータセットをアップロードするために、Kaggle で公開されているデータセット から取得したデータを含むCSVファイルを読み込みます。
ここで、GridDBコンテナを作成して、データベーススキーマをGridDBに渡し、行情報を挿入する前に、データベースのデザインを生成できるようにします。次に、GridDBにデータを挿入します。これで、データセットを GridDB プラットフォームにエクスポートすることに成功しました。
一方、GridDBプラットフォームからデータセットを取り込むには、SQLに似たGridDBの問い合わせ言語であるTQLを使用します。コンテナを作成し、その中に取り込んだデータを格納することになります。次に、カラム情報の順に行を抽出し、データフレームに保存して、データの可視化や分析に利用することになります。
データの可視化・解析には、以下のNodeJS用ライブラリを使用する予定です。
- DanfoJS - DataFrameを扱うためのものです。
var griddb = require('griddb_node');
const dfd = require("danfojs-node")
var fs = require('fs');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
const csvWriter = createCsvWriter({
path: 'out.csv',
header: [
{id: "id", title:"id"},
{id: "new_name", title:"new_name"},
{id: "est_diameter_min", title:"est_diameter_min"},
{id: "est_diameter_max", title:"est_diameter_max"},
{id: "relative_velocity", title:"relative_velocity"},
{id: "miss_distance", title:"miss_distance"},
{id: "orbiting_body" , title:"orbiting_body"},
{id: "sentry_object", title:"sentry_object"},
{id: "absolute_magnitude", title:"absolute_magnitude"}
]
});
const factory = griddb.StoreFactory.getInstance();
const store = factory.getStore({
"host": '239.0.0.1',
"port": 31999,
"clusterName": "defaultCluster",
"username": "admin",
"password": "admin"
});
// For connecting to the GridDB Server we have to make containers and specify the schema.
const conInfo = new griddb.ContainerInfo({
'name': "neoanalysis",
'columnInfoList': [
["name", griddb.Type.STRING],
["id", griddb.Type.INTEGER],
["new_name", griddb.Type.STRING],
["est_diameter_min", griddb.Type.DOUBLE],
["est_diameter_max", griddb.Type.DOUBLE],
["relative_velocity", griddb.Type.DOUBLE],
["miss_distance", griddb.Type.DOUBLE],
["absolute_magnitude", griddb.Type.DOUBLE]
],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
// ////////////////////////////////////////////
const csv = require('csv-parser');
const fs = require('fs');
var lst = []
var lst2 = []
var i =0;
fs.createReadStream('./Dataset/neo.csv')
.pipe(csv())
.on('data', (row) => {
lst.push(row);
console.log(lst);
})
.on('end', () => {
var container;
var idx = 0;
for(let i=0;i<lst.length;i++){
store.putContainer(conInfo, false)
.then(cont => {
container = cont;
return container.createIndex({ 'columnName': 'name', 'indexType': griddb.IndexType.DEFAULT });
})
.then(() => {
idx++;
container.setAutoCommit(false);
return container.put([String(idx), lst[i]['id'],lst[i]["new_name"],lst[i]["est_diameter_min"],lst[i]["est_diameter_max"],lst[i]["relative_velocity"],lst[i]["miss_distance"],lst[i]["absolute_magnitude"]]);
})
.then(() => {
return container.commit();
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
}
store.getContainer("neoanalysis")
.then(ts => {
container = ts;
query = container.query("select *")
return query.fetch();
})
.then(rs => {
while (rs.hasNext()) {
let rsNext = rs.next()
lst2.push(
{
'id': rsNext[1],
"new_name": rsNext[2],
"est_diameter_min": rsNext[3],
"est_diameter_max": rsNext[4],
"relative_velocity": rsNext[5],
"miss_distance": rsNext[6],
"absolute_magnitude": rsNext[7],
}
);
}
csvWriter
.writeRecords(lst2)
.then(()=> console.log('The CSV file was written successfully'));
return
}).catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
});
データ分析
ここでデータセットのチェックと読み込みを行い、データ解析を行います。
orbiting_bodyとsentry_objectは列全体で冗長な値を持ち、解析に役立つ固有の値がないため、以下のようにこの2列を解析から省くことにします。

以下のように、csvファイルをDataFrame変数(df)にロードすることになります。
let df = await dfd.readCSV("./out.csv")データ分析では、まず、データセットの行と列の数を確認します。
行数は90836、列数は8です。
console.log(df.shape)
// Output
// [ 90836, 8 ]
では、上記のように2つの列を省略した後の列の名前と、データが何を表しているかを知るための列のデータ型を見てみましょう。
console.log(df.columns)
// Output
// ['id','new_name', 'est_diameter_min', 'est_diameter_max', 'relative_velocity', 'miss_distance', 'absolute_magnitude', 'hazardous']
df.loc({columns:['id',
'new_name',
'est_diameter_min',
'est_diameter_max',
'relative_velocity',
'miss_distance','absolute_magnitude',
'hazardous']}).ctypes.print()
// Output
// ╔══════════════════════╤═════════╗
// ║ id │ int64 ║
// ╟──────────────────────┼─────────╢
// ║ new_name │ object ║
// ╟──────────────────────┼─────────╢
// ║ est_diameter_min │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ est_diameter_max │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ relative_velocity │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ miss_distance │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ absolute_magnitude │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ hazardous │ bool ║
// ╚══════════════════════╧═════════╝
GridDB コンテナからデータへのアクセスは以下のように行います。
# Get the containers
obtained_data = gridstore.get_container("redwinequality")
# Fetch all rows - language_tag_container
query = obtained_data.query("select *")
ここで、後述する列の統計の概要を見て、その最小値、最大値、平均値、標準偏差などを確認します。
df.loc({columns:['est_diameter_min','est_diameter_max','relative_velocity','miss_distance']}).describe().round(2).print()
// Output
// ╔════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╗
// ║ │ est_diameter_min │ est_diameter_max │ relative_velocity │ miss_distance ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ count │ 90836 │ 90836 │ 90836 │ 9.1e+04 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ mean │ 0.13 │ 0.28 │ 48066 │ 3.71e+07 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ std │ 0.29 │ 0.67 │ 25293 │ 2.24e+07 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ min │ 0.00061 │ 0.0014 │ 203 │ 6.74e+03 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ median │ 0.05 │ 0.11 │ 44190 │ 3.78e+07 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ max │ 38 │ 85 │ 236990 │ 7.50e+07 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ variance │ 8.91e-02 │ 4.45e-01 │ 6.40e+08 │ 4.99e+14 ║
// ╚════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╝
品質と他のカラムの散布図をプロットします。
## Scatter Plot between miss_distance and relative_velocity
let cols = [...cols]
cols.pop('miss_distance')
for(let i = 0; i < cols.length; i++)
{
let data = [{
x: df[cols[i]].values,
y: df['miss_distance'].values,
type: 'scatter',
mode: 'markers'}];
let layout = {
height: 400,
width: 700,
title: 'Missing Distance from Earth vs '+cols[i],
xaxis: {title: cols[i]},
yaxis: {title: 'Miss Distance'}};
// There is no HTML element named `myDiv`, hence the plot is displayed below.
Plotly.newPlot('myDiv', data, layout);
}
2つの列の例に対するプロットは以下の通りです。

上のプロットは、2つの変数が正の線形関係を持つことを示しており、地球からの距離が離れるほど、小惑星は地球の重力の影響を受けないので、相対速度が大きくなることを意味します。
## Correlation plot of the columns to see how these variables or factors related to each other
correlogram(data)
相関図は以下の通りです。
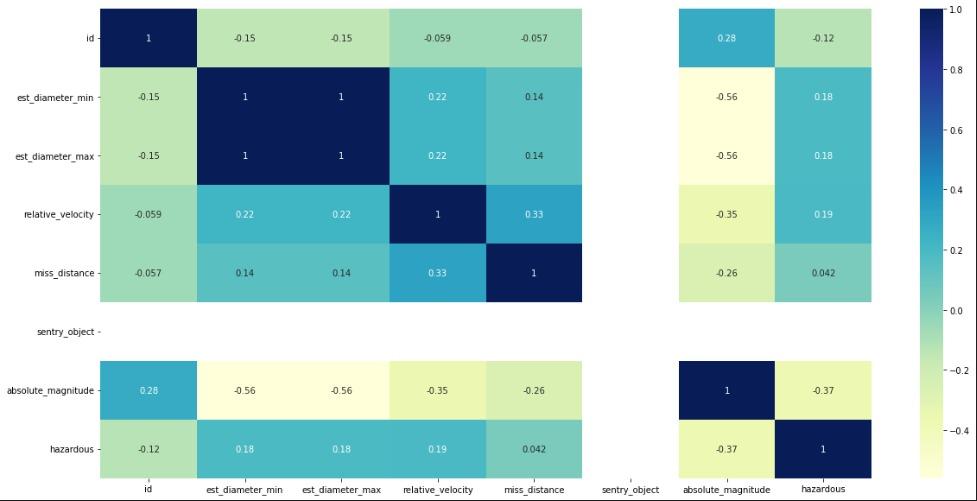
上の相関図は、各変数の値を示しており、値が高いほど両者の関係は密接です。したがって、小惑星の距離と相対速度が最も高い値(0.33)を示し、この2つが小惑星の地球への衝突点を決定する上で最も重要な変数であることが分かります。ただし、同じ変数同士は当然ながら最も強い相関を持つので、相関図では上の対角線は無視しています。
結論
NASAの科学者は、小惑星が地球に衝突するかどうかを判断する際に、さまざまな変数を考慮します。そして、もし衝突した場合には、できるだけ多くの貴重な人命を救うために、正確な座標を知る必要があります。
最後に、今回のデータ分析には、データの読み出し、書き込み、保存が容易に行えるGridDBを使用しました。