導入と目的
新連載:Pythonで作るIoTデータのダッシュボード
IoT(モノのインターネット)ビジネスの多くはスタートアップであり、リソースが限られています。しかし、大企業であっても慎重な支出戦略は決して損ではありません。
データの可視化やリアルタイムストリーミングのツールは、世の中にたくさんあります。しかし、実際には、2分ごとに更新されるべきいくつかのチャートが必要なだけであれば、そのようなものにお金を使う必要はありません。
この記事は、私たちが用意した3つのシリーズのうち、オープニングの1つです。このシリーズでは、GridDBからIoTデータを取り出し、3つの重要なIoTメトリクスを表示するシンプルなPythonアプリの作り方を紹介します。
提供するコードをもとに、好きなだけチャートを作成したり、カスタマイズしたりすることができます。
このシリーズは、以下のチュートリアルで構成されています。
- ダッシュボード・リフレッシュのスケジューリング
- Python kivyを使ったシンプルなアプリの構築
- アプリの完成とデスクトップアイコンの追加
最終的には、小さくても独立したデスクトップ・アプリケーションができあがり、毎朝起動して日中はそれを使い続けることができます。
このアプリはタイムラグを最小限に抑え、ほぼリアルタイムでデータを表示します。しかもあなたは何もしなくてもいいのです。
ユースケースについて
この記事では、ランダムなデータを生成するPythonパッケージで作成されたテストデータセットを使用しています。このデータセットは、あらゆるIoTデバイスから送られてくる標準的な接続データを模倣しています。正確に言うと、そのようなデバイスの内部にインストールされたSIMカードがバックグラウンドで送信するデータです。
接続データは通常、サービスエンジニアやサポートマネージャがトラブルシューティングや異常検知に使用します。
目標について
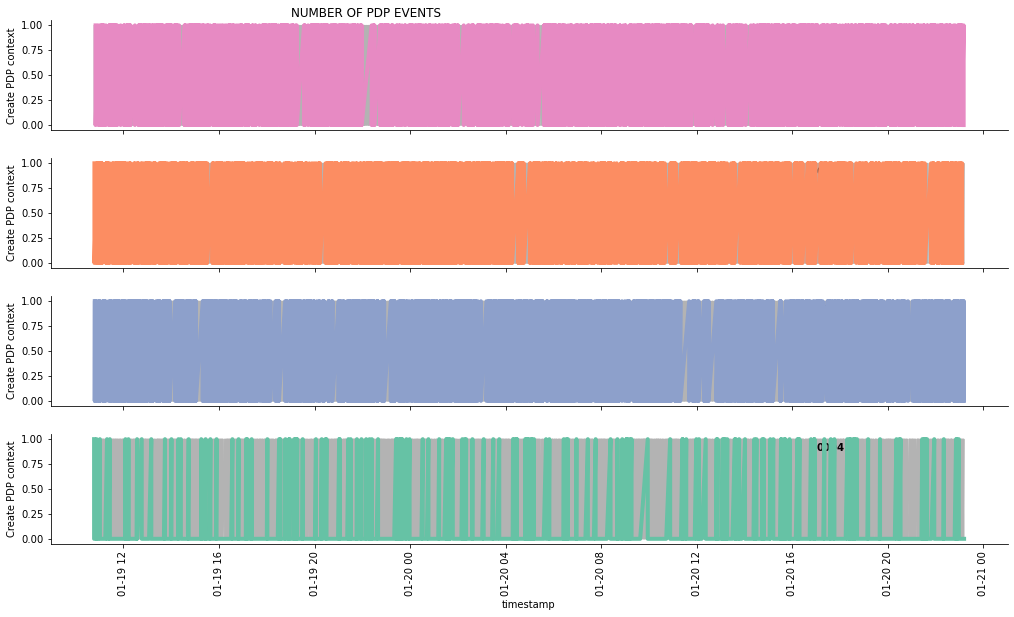
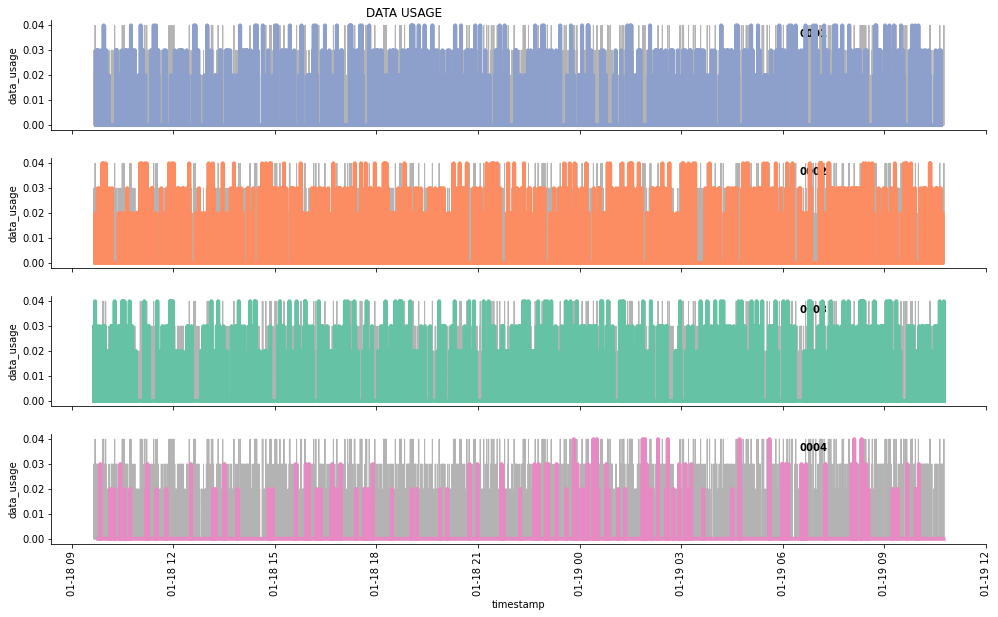
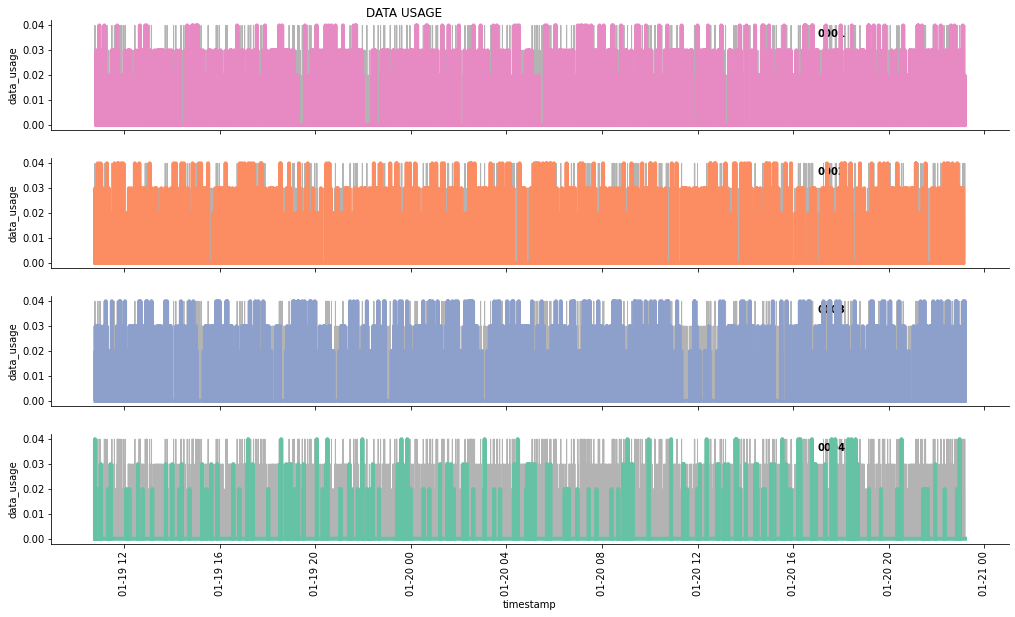
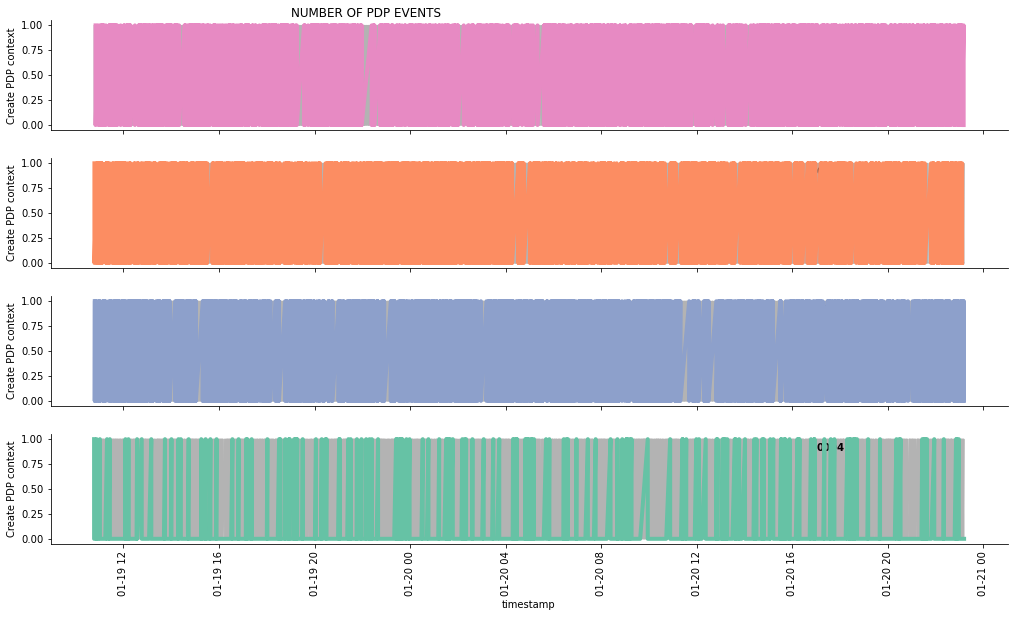
この記事では、データを照会して、以下の3つのグラフを作成します。
- データ使用量
- イベントの数
- アラートの数
ここでは、「PDPコンテキストの作成」イベントを例に挙げて説明します。PDPコンテキストの詳細については、こちらをご覧ください。
また、このクエリを10分ごとに実行し、それに応じてデータを更新します。
手法について
ここでは、Jupyter Notebookを使用します。最終的なコードをPythonのIDEで実行してもよいでしょう。
前提知識
こちらの記事では、Jupyter NotebookからGridDBを照会する方法を詳しく説明しているのでJupyter Notebookの使い方に詳しくない方はぜひご覧になってください。このチュートリアルでは、Dockerをインストールしてコンテナを作成し、その中でJupyterを実行することで、チュートリアルを進めることができます。
本編
事前準備
データベースからのデータ取得
データベースからデータを取得するために、Pythonパッケージ jaydebeapi を用いてデータベースとの接続を確立し、WHERE 句を用いたSQLベースのクエリを使用します。
ここでは、直近1時間のデータのみを取得するために、GridDBネイティブの関数 TIMESTAMP_ADD() を使用しています。GridDB SQLリファレンスに記載されているように、カスタマイズすることができます。
import pandas as pd
import jaydebeapi
conn = jaydebeapi.connect("com.toshiba.mwcloud.gs.sql.Driver",
"jdbc:gs://griddb:20001/defaultCluster/public?notificationMember:127.0.0.1:20001",
["admin", "admin"],
"/usr/share/java/gridstore-jdbc-4.5.0.jar",)
iot = ('''SELECT TIMESTAMP(timestamp) as timestamp, event, simid, data_usage
FROM IoT
WHERE TIMESTAMP(timestamp) < TIMESTAMP_ADD(HOUR, NOW(), -1)''')
iotdf = pd.read_sql_query(iot, conn)
iotdf.head(
| No. | timestamp | event | simid | data_usage |
|---|---|---|---|---|
| 0 | 2021-01-18 09:39:27.200000 | Create PDP context | 0003 | 0.00 |
| 1 | 2021-01-18 09:39:28.200000 | data | 0003 | 0.03 |
| 2 | 2021-01-18 09:39:29.200000 | Delete PDP context | 0003 | 0.00 |
| 3 | 2021-01-18 09:40:05.200000 | Create PDP context | 0003 | 0.00 |
| 4 | 2021-01-18 09:40:06.200000 | data | 0003 | 0.03 |
これは時系列データセットです。タイムスタンプ、このタイムスタンプに割り当てられたイベント、タイムスタンプを送信したSIMカードのID、そして必要に応じて、インターネット転送量(単位はkB)が含まれています。
データのピボット処理
Jupyterでは、データベースでは正しいタイムスタンプ形式であっても、データフレームではtimestampカラムが文字列カラムとして表示されることがあります。
タイムスタンプに変換します。
iotdf['timestamp']= iotdf['timestamp'].apply(pd.to_datetime)
カラム数の少ない、いわゆる「スリム」なデータベースがあります。まず、それを広げていく必要があります。イベントの列をいくつかの列に分割し、イベントの種類ごとに1つの列を作ります。イベントが発生した場合、それぞれの列には値1が入ります。
そして pivot_table() 関数を使って、iotデータフレームをpandasのピボットテーブルに変換します。
pivotdf = iotdf.pivot_table(index=['timestamp', 'simid', 'data_usage'],
columns='event',
values= 'event',
aggfunc=lambda x: 1)
pivotdf.head()
| event | Create PDP context | Delete PDP context | alert | data | ||
|---|---|---|---|---|---|---|
| timestamp | simid | data usage | ||||
| 2021-01-18 09:39:27.200000 | 0003 | 0.00 | 1.0 | NaN | NaN | NaN |
| 2021-01-18 09:39:28.200000 | 0003 | 0.03 | NaN | NaN | NaN | 1.0 |
| 2021-01-18 09:39:29.200000 | 0003 | 0.00 | NaN | 1.0 | NaN | NaN |
| 2021-01-18 09:40:05.200000 | 0003 | 0.00 | 1.0 | NaN | NaN | NaN |
| 2021-01-18 09:40:06.200000 | 0003 | 0.03 | NaN | NaN | NaN | 1.0 |
データフレームには複雑な列名があり、3つの列がインデックスになっているので、これを磨いて通常のデータフレームのように戻します。reset_index() 関数でインデックスを削除します。
また、計算をしたり、実際に時系列データをプロットしたりするためには、NaNをゼロに置き換える必要があります。そこで、fillna() 関数を使います。
pivotdf = pivotdf.reset_index()
pivotdf = pivotdf.fillna(0)
pivotdf.head()
| event | timestamp | simid | data usage | Create PDP context | Delete PDP context | alert | data |
|---|---|---|---|---|---|---|---|
| 0 | 2021-01-18 09:39:27.200000 | 0003 | 0.00 | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | 2021-01-18 09:39:28.200000 | 0003 | 0.03 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | 2021-01-18 09:39:29.200000 | 0003 | 0.00 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 2021-01-18 09:40:05.200000 | 0003 | 0.00 | 1.0 | 0.0 | 0.0 | 0.0 |
| 4 | 2021-01-18 09:40:06.200000 | 0003 | 0.03 | 0.0 | 0.0 | 0.0 | 1.0 |
これで、データを可視化する準備が整いました。
グラフ化
デバイスやSIM IDごとに各指標を分割しています。それによって、行動の異常をキャッチすることができるのです。
グループ化されたチャートの作成に関しては、seaborn パッケージが最も高速であることが証明されています。数秒の差で勝負がつきます。これは他の状況ではそれほど重要ではなかったでしょう。しかし、リアルタイムのダッシュボードが必要な場合は、チャートを非常に速く生成する必要があります。
seabornパッケージは、グループ化されたチャートを作成するための複数の機会を提供しています。2つ目のオプションであるフェイスグリッドの代わりに リレーショナルプロット を使用していますが、これはラインチャートとの相性が良いからです。タイムスタンプごとに1つのイベントがあるにもかかわらず、データの連続性を示すには折れ線グラフが適しています。また、X軸の目盛りの回転など、チャートのパラメータをカスタマイズする必要がある場合にも適しています。
以下は、データの使用例です
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.relplot(
data=pivotdf, x="timestamp", y="data_usage", col="simid", hue="simid",col_order = ['0001', '0002', '0003', '0004'],
kind="line", palette="Set2", linewidth=4, zorder=5,
col_wrap=1, height=2, aspect=7, legend=False,
)
for simid, ax in g.axes_dict.items():
ax.text(.8, .85, simid, transform=ax.transAxes, fontweight="bold")
sns.lineplot(data=pivotdf, x="timestamp", y="data_usage", units="simid",
estimator=None, color=".7", linewidth=1, ax=ax,
)
ax.set_xticks(ax.get_xticks()[::1])
g.set_xticklabels(rotation=90)
g.set_titles("")
g.fig.suptitle('DATA USAGE', horizontalalignment = 'right')
Text(0.5, 0.98, 'DATA USAGE')
自動更新機能の作成
whileループの紹介
そして、最もエキサイティングな部分に到達しました。
必要なのは、私たちの手を煩わせることなく、コードを何度も実行させることです。
この目的のために、whileループを使います。このループの中に、上で述べたことをすべて(さらに2つのグラフを)入れるだけです。そして、それを一度開始します。ほら! Jupyter NotebookまたはPython IDEが開いていて、スクリプトが一度実行されている間は、データを取得し続け、リフレッシュされたチャートを表示します。
最適化のための注意事項
完全なコードを公開する前に、知っておくべきいくつかのベストプラクティスを紹介します。
- 同じチャートを何度もスクロールするのは絶対に避けたいですよね。この手間を省くために、 clear_output() をループの中で、何よりも先に追加します。
- 存在しない出力をクリアすることはできませんので、 try/except/pass を使用して、スクリプトの初回実行時に失敗しないようにしてください。
- オプション:データが少なすぎて適切にレンダリングできないチャートに try/except/pass を使用します。これにより、スクリプトが壊れてエラーメッセージを投げることなく、次のセクションにジャンプすることができます。
- matplotlib パッケージの各プロットの後に plt.show() 関数を使用してください。そうしないと、コードの最後のプロットだけが表示されます。
- sleep() 関数を各ループ実行の最後に使用して、「実際の」リアルタイムでのデータベースへの問い合わせが意味をなさない場合、隙間時間を作ります。データベースとCPUの両方を休ませてあげましょう。
- 最後になりましたが、進行状況を確認したり、トラブルシューティングを行うために、コード全体にカスタムステータスメッセージを追加してください。例えば、print(“got new data”, datetime.now()) を追加して、新しいデータが正常に取得されたことを示すようにします。独自のタイムスタンプを作成するには、datetime パッケージを使用します。
さあ、ソースコードを見てみましょう!
最終版のソースコード
from datetime import datetime
from IPython.display import clear_output
import time
import seaborn as sns
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
import pandas as pd
import jaydebeapi
conn = jaydebeapi.connect("com.toshiba.mwcloud.gs.sql.Driver",
"jdbc:gs://griddb:20001/defaultCluster/public?notificationMember:127.0.0.1:20001",
["admin", "admin"],
"/usr/share/java/gridstore-jdbc-4.5.0.jar",)
curs = conn.cursor()
stop = 1
while stop > 0:
#delete the previous charts if any
try:
clear_output(wait=True)
except:
pass
#querying the data for the last hour
iot = ('''SELECT TIMESTAMP(timestamp) as timestamp, event, simid, data_usage
FROM IoT
WHERE TIMESTAMP(timestamp) > TIMESTAMP_ADD(HOUR, NOW(), -1)''')
iotdf = pd.read_sql_query(iot, conn)
print('got new data')
print(datetime.now())
#data preparation
iotdf['timestamp']= iotdf['timestamp'].apply(pd.to_datetime)
pivotdf = iotdf.pivot_table(index=['timestamp', 'simid', 'data_usage'],
columns='event',
values= 'event',
aggfunc=lambda x: 1)
pivotdf = pivotdf.reset_index()
pivotdf = pivotdf.fillna(0)
#data visualization
order = ['0001', '0002', '0003', '0004']
#data usage
g = sns.relplot(
data=pivotdf,
x="timestamp", y="data_usage", col="simid", hue="simid",col_order = ['0001', '0002', '0003', '0004'],
kind="line", palette="Set2", linewidth=4, zorder=5,
col_wrap=1, height=2, aspect=7, legend=False,
)
for simid, ax in g.axes_dict.items():
ax.text(.8, .85, simid, transform=ax.transAxes, fontweight="bold")
sns.lineplot(
data=pivotdf, x="timestamp", y="data_usage", units="simid",
estimator=None, color=".7", linewidth=1, ax=ax,
)
ax.set_xticks(ax.get_xticks()[::1])
g.set_xticklabels(rotation=90)
g.set_titles("")
g.fig.suptitle('DATA USAGE', horizontalalignment = 'right')
plt.show()
#number of pdp events
g = sns.relplot(
data=pivotdf,
x="timestamp", y="Create PDP context", col="simid", hue="simid",col_order = ['0001', '0002', '0003', '0004'],
kind="line", palette="Set2", linewidth=4, zorder=5,
col_wrap=1, height=2, aspect=7, legend=False,
)
for simid, ax in g.axes_dict.items():
ax.text(.8, .85, simid, transform=ax.transAxes, fontweight="bold")
sns.lineplot(
data=pivotdf, x="timestamp", y="Create PDP context", units="simid",
estimator=None, color=".7", linewidth=1, ax=ax,
)
ax.set_xticks(ax.get_xticks()[::1])
g.set_xticklabels(rotation=90)
g.set_titles("")
g.fig.suptitle('NUMBER OF PDP EVENTS', horizontalalignment = 'right')
plt.show()
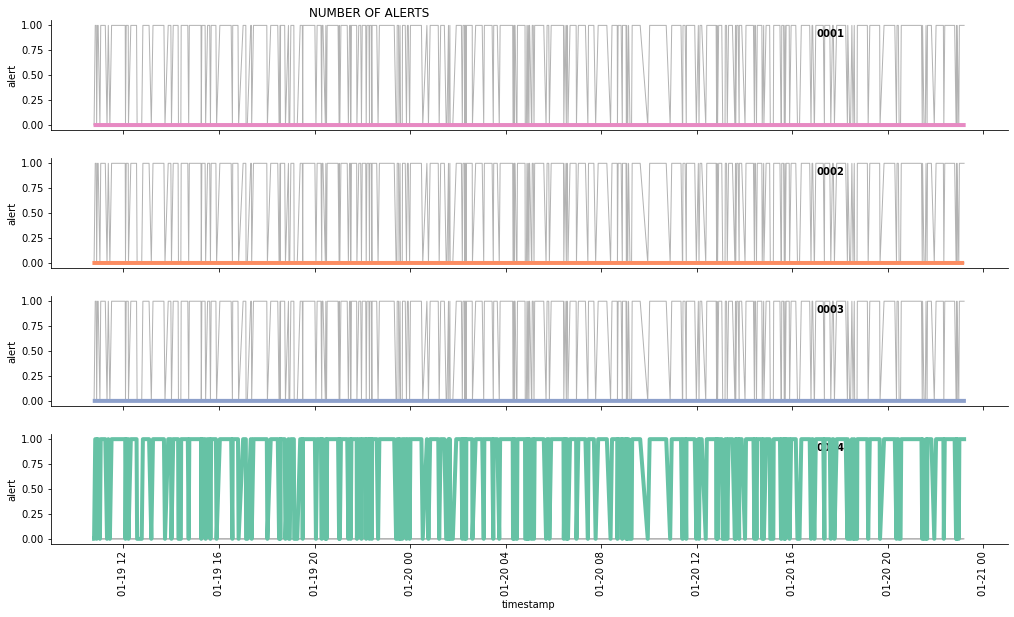
#alerts
g = sns.relplot(
data=pivotdf,
x="timestamp", y="alert", col="simid", hue="simid",col_order = ['0001', '0002', '0003', '0004'],
kind="line", palette="Set2", linewidth=4, zorder=5,
col_wrap=1, height=2, aspect=7, legend=False,
)
for simid, ax in g.axes_dict.items():
ax.text(.8, .85, simid, transform=ax.transAxes, fontweight="bold")
sns.lineplot(
data=pivotdf, x="timestamp", y="alert", units="simid",
estimator=None, color=".7", linewidth=1, ax=ax,
)
ax.set_xticks(ax.get_xticks()[::1])
g.set_xticklabels(rotation=90)
g.set_titles("")
g.fig.suptitle('NUMBER OF ALERTS', horizontalalignment = 'right')
plt.show()
#putting it into sleep for 10 seconds
print('falling asleep')
print(datetime.now())
time.sleep(60)
備考
Jupyterを使いたい場合は、出力部分をマウスでクリックした後、CMD + O(アルファベットのo)で展開することができます。
ちょっと待って!
whileループの終了条件はどうするの? stop の値を減らさなくて良いのでしょうか?ところで、stopはどこから来たのでしょうか?
いいえ、stopの値は減らしません。ループを停止させたいわけではないからですJupyter Notebookを閉じればアプリケーションは停止します。
この条件は任意に決めたものです。ランダムな変数が必要だっただけです。
次回に向けて
IoT接続データを表示するダッシュボードを構築し、10秒ごとに更新するようにしました。次回は、これを小さな独立したアプリケーションに統合してみます