メタンは無色・無臭の気体で、自然界に多く存在し、人間の特定の活動によって生成されることもあります。メタンはパラフィン系炭化水素の中で最も単純な物質であり、温室効果ガスの中で最も強力なガスの一つで、化学式はCH4です。
メタンは温室効果ガスであるため、地球の気温や気候に影響を与えます。メタンの排出源は、自然起源と人為起源の2種類に分類されます。人為的な排出源としては、埋立地、石油・天然ガスシステム、工業プロセス、石炭採掘、定置・移動燃焼、廃水処理、農業活動などが挙げられます。自然発生源としては、湿地における植物体の分解、地下埋蔵物からのガスの浸透、家畜による食物の消化など、有機物の分解や腐敗が挙げられます。
以上、メタンガスとその原因について理解したところで、今度は解析のために、GridDBを使って大量のデータセットを読み込み、保存し、アクセスすることにしましょう。
GridDBを使ったデータセットのエクスポートとインポート
GridDBは、高いスケーラビリティと最適化を実現したインメモリNoSQLデータベースで、特に時系列データベースにおいて、より高いパフォーマンスと効率性を実現するための並列処理を可能にします。今回はGridDBのNode.jsクライアントを使用します。Node.jsクライアントを使うことでGridDBとNode.jsを接続し、リアルタイムにデータをインポートまたはエクスポートすることができます。
今回のデータセットには、以下のカラムが存在します。
- Country : 排出責任を負うべき国の名称。
- Sector : 排出を担当したエネルギー部門の名称。
- Gas : ガスの名称。
- Unit : 排出量を測定する単位。
- 2018 : 2018年のガス排出量。
- 2017 : 2017年のガス排出量。
- 2016 : 2016年のガス排出量。
.
.
. - 1990 : 1990年のガス排出量。
GridDBへのデータセットの書き出し
GridDBにデータセットをアップロードするには、このKaggle Datasetから取得したデータを含むCSVファイルを読み込む必要があります。
データの可視化と分析には、DataFrameを扱うためのライブラリDanfo.jsを使用します。
var griddb = require('griddb_node');
const dfd = require("danfojs-node")
const csv = require('csv-parser');
const fs = require('fs');
var lst = []
var lst2 = []
var i =0;
fs.createReadStream('./Dataset/methane_hist_emissions.csv')
.pipe(csv())
.on('data', (row) => {
lst.push(row);
console.log(lst);
})
GridDBコンテナを生成し、データを挿入するためのデータベーススキーマを渡します。
const conInfo = new griddb.ContainerInfo({
'name': "methaneanalysis",
'columnInfoList': [
["name", griddb.Type.STRING],
["Country", griddb.Type.STRING],
["Sector", griddb.Type.STRING],
["Gas", griddb.Type.STRING],
["Unit", griddb.Type.STRING],
["2018", griddb.Type.DOUBLE],
["2017", griddb.Type.DOUBLE],
["2016", griddb.Type.DOUBLE],
["2015", griddb.Type.DOUBLE],
["2014", griddb.Type.DOUBLE],
["2013", griddb.Type.DOUBLE],
["2012", griddb.Type.DOUBLE],
["2011", griddb.Type.DOUBLE],
["2010", griddb.Type.DOUBLE],
["2009", griddb.Type.DOUBLE],
["2008", griddb.Type.DOUBLE],
["2007", griddb.Type.DOUBLE],
["2006", griddb.Type.DOUBLE],
["2005", griddb.Type.DOUBLE],
["2004", griddb.Type.DOUBLE],
["2003", griddb.Type.DOUBLE],
["2002", griddb.Type.DOUBLE],
["2001", griddb.Type.DOUBLE],
["2000", griddb.Type.DOUBLE],
["1999", griddb.Type.DOUBLE],
["1998", griddb.Type.DOUBLE],
["1997", griddb.Type.DOUBLE],
["1996", griddb.Type.DOUBLE],
["1995", griddb.Type.DOUBLE],
["1994", griddb.Type.DOUBLE],
["1993", griddb.Type.DOUBLE],
["1992", griddb.Type.DOUBLE],
["1991", griddb.Type.DOUBLE],
["1990", griddb.Type.DOUBLE]
],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
// Inserting data into the GridDB
var container;
var idx = 0;
for(let i=0;i<lst.length;i++){
store.putContainer(conInfo, false)
.then(cont => {
container = cont;
return container.createIndex({ 'columnName': 'name', 'indexType': griddb.IndexType.DEFAULT });
})
.then(() => {
idx++;
container.setAutoCommit(false);
return container.put([String(idx), lst[i]['Country'],lst[i]["Sector"],lst[i]["Gas"],lst[i]["Unit"],lst[i]["2018"],lst[i]["2017"],lst[i]["2016"],lst[i]["2015"],lst[i]["2014"],lst[i]["2013"],lst[i]["2012"],lst[i]["2011"],lst[i]["2010"],lst[i]["2009"],lst[i]["2008"],lst[i]["2007"],lst[i]["2006"],lst[i]["2005"],lst[i]["2004"],lst[i]["2003"],lst[i]["2002"],lst[i]["2001"],lst[i]["2000"],lst[i]["1999"],lst[i]["1998"],lst[i]["1997"],lst[i]["1996"],lst[i]["1995"],lst[i]["1994"],lst[i]["1993"],lst[i]["1992"],lst[i]["1991"],lst[i]["1990"]]);
})
.then(() => {
return container.commit();
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
}
GridDBからデータセットをインポートする
GridDBプラットフォームからデータセットを取り込むために、SQLに似たGridDBのクエリ言語であるTQLを使用します。まず、コンテナを作成し、取り込んだデータを保存します。次に、カラム情報の順に行を抽出し、データの可視化と分析のためにデータフレームに保存します。
# Get the containers
obtained_data = gridstore.get_container("methaneanalysis")
# Fetch all rows - language_tag_container
query = obtained_data.query("select *")
# Creating Data Frame variable
let df = await dfd.readCSV("./out.csv")
GridDBからのデータセットのインポートに成功しました。
データ分析
データ分析を進めるにあたり、まずはデータセットについて確認します。
データセットの行と列の数をチェックすると、1738行と33列のデータセットであることが分かります。
console.log(df.shape)
// Output
// [ 1738, 33 ]
ガス欄にはCH4が、単位欄にはMTCO2eが冗長な値として含まれています。その結果、この2つの列は分析から除外されています。データが何を表しているかを知るために、列名とデータ型を見てみましょう。
console.log(df.columns)
// Output
// ['Country','Sector', '2018', '2017', '2016', '2015', '2014', '2013', '2012', '2011', '2010', '2009', '2008', '2007', '2006', '2005', '2004', '2003', '2002', '2001', '2000', '1999', '1998','1997', '1996', '1995', '1994', '1993', '1992', '1991', '1990' ]
df.loc({columns:['Country',
'Sector',
'2018','2017', '2016', '2015', '2014', '2013', '2012', '2011', '2010', '2009', '2008', '2007', '2006', '2005', '2004',
'2003', '2002', '2001', '2000', '1999', '1998','1997', '1996', '1995', '1994', '1993', '1992', '1991', '1990' ]}).ctypes.print()
// Output
// ╔══════════════════════╤═════════╗
// ║ Country │ object ║
// ╟──────────────────────┼─────────╢
// ║ Sector │ object ║
// ╟──────────────────────┼─────────╢
// ║ 2018 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2017 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2016 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2015 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2014 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2013 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2012 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2011 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2010 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2009 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2008 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2007 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2006 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2005 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2004 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2003 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2002 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2001 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 2000 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1999 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1998 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1997 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1996 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1995 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1994 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1993 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1992 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1991 │ float64 ║
// ╟──────────────────────┼─────────╢
// ║ 1990 │ float64 ║
// ╚══════════════════════╧═════════╝
ここで、後述する列の統計の概要を見て、その最小値、最大値、平均値、標準偏差などを確認します。
df.loc({columns:['2018', '2017', '2016', '2015', '2014', '2013']}).describe().round(2).print()
// Output
// ╔════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╤═══════════════════╗
// ║ │ 2018 │ 2017 │ 2016 │ 2015 │ 2014 │ 2013 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ count │ 1738 │ 1738 │ 1738 │ 1738 │ 1738 │ 1738 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ mean │ 17.20 │ 17.07 │ 16.98 │ 17.10 │ 16.94 │ 16.65 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ std │ 77.35 │ 77.15 │ 77.08 │ 77.09 │ 75.98 │ 74.64 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ min │ 0.00 │ 0.00 │ 0.00 │ 0.00 │ 0.00 │ 0.00 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ median │ 0.82 │ 0.82 │ 0.83 │ 0.83 │ 0.84 │ 0.83 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ max │ 1238.95 │ 1239.28 │ 1242.43 │ 1237.80 │ 1206.51 │ 1178.21 ║
// ╟────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────┼───────────────────╢
// ║ variance │ 5983.40 │ 5951.64 │ 5942.20 │ 5942.84 │ 5773.28 │ 5571.78 ║
// ╚════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╧═══════════════════╝
次に、棒グラフと円グラフを使って分布を可視化します。
棒グラフ
## Distribution of Column Values
const { Plotly } = require('node-kernel');
let cols = df.columns
for(let i = 0; i < cols.length; i++)
{
let data = [{
x: cols[i],
y: df[cols[i]].values,
type: 'bar'}];
let layout = {
height: 400,
width: 700,
title: 'Global Methane Gas Emissions for the years (2018 - 1990)' +cols[i],
xaxis: {title: cols[i]}};
// There is no HTML element named `myDiv`, hence the plot is displayed below.
Plotly.newPlot('myDiv', data, layout);
}
df.plot("plot_div").bar()
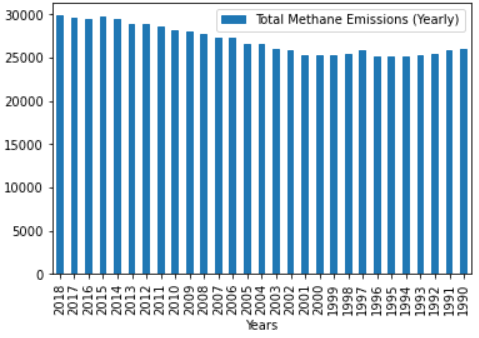
上の棒グラフは、メタンガスの排出量が経年的に増加し、2018年に最も高いピークを迎えていることを示しています。
円グラフ
どの国が世界最大のメタン排出国なのか、円グラフをプロットして3カ国の2018年のメタン排出量を検証してみます。中国、米国、ロシアの3カ国です。
const { Plotly } = require('node-kernel');
Values: [sum_2018_US, sum_2018_China, sum_2018_Russia],
Name: ["United States", "China", "Russia"]
df.plot("plot_div").pie({ config: { values: "Values", labels: "Name" } });
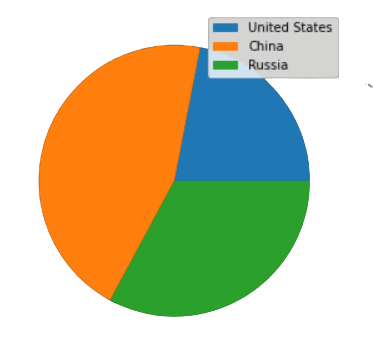
円グラフによると、2018年のメタン排出量は、上記3カ国の中で中国が最も多いです。
結論
メタン排出量の増加の主な原因は、人為的な活動の増加です。その結果、地球温暖化が進み、地球規模で気候変動が起きているのはご存じのとおりです。ですから、このままでは、私たちは住みにくい環境になってしまうのです。
最後に、今回のデータ分析には、データへのアクセスが早く、データの読み書きや保存が効率的に行えるGridDBを使用しました。