顧客解約率とは、特定の企業との取引を停止する顧客の数を決定する重要なビジネス概念です。解約率は、企業が一定の期間に顧客を失う割合と定義されます。例えば、解約率が年15%であれば、その企業は毎年総顧客数の15%を失っていることになります。通信業界では、競争の激化や新規通信事業者の出現により、顧客離れが特に重要視されています。このため、通信業界では毎年高い解約率が予想されます。
通信業界の解約率は毎月約1.9%であり、毎年67%まで上昇する可能性があります。(出典)
これは顧客維持率に直接影響するため、企業にとって非常に慎重に検討すべきリスクです。
同記事によると、通信業界では新規顧客獲得コストは顧客維持コストの25倍であり、このことも解約率を決定的にする要因の一つです。
高度な機械学習アルゴリズムは、継続率のようなビジネスコンセプトと連携し、ビジネスインテリジェンスソリューションを提供します。この記事では、広範かつ詳細なデータセットを用いて、通信業界における解約率を予測するモデルについて説明します。この目的のために、Python、GridDB、機械学習アルゴリズムなどの一連の技術を組み合わせ、実際の生産環境にこのソリューションを展開します。この記事では、まず実行環境のセットアップを行います。次に、本研究で使用するデータセットを紹介します。また、データセットを読み込むために必要なPythonライブラリをインポートします。データセットを探索するために、様々なPythonライブラリを利用します。その後、予測結果を得るために評価する機械学習アルゴリズムのモデルについて説明します。
環境の設定
この記事で行った操作を成功させるために、私たちの実行のコンテキストを再現するためのリストを以下に示します。
- Windows 10, Anaconda, Jupiter Notebook
- Python 3.8 - MSI for GridDB Python Client 0.8.3
- MSI for GridDB C Client
- Swig 4.0.2
pipを用いたGridDB Pythonクライアントのインストールについては、以下をご参照ください。
pip install griddb-python-client
pip install griddb-python
データセットの紹介
今回使用するデータセットは、7043行で構成される代表的なもので、それぞれが顧客を表しています。このデータセットには27の属性があります。このデータセットはオープンソースであり、以下のKaggle notebookで公開されています。ここでは、記事の後半で言及される重要な属性を紹介します。
-
gender: お客様が男性か女性か -
SeniorCitizen: お客様が高齢者かどうか -
tenure: お客様との取引月数 -
OnlineSecurity: お客様がオンラインセキュリティをお持ちかどうか - その他
PhoneService,MultipleLines,InternetServiceなどの属性があります
属性やその種類については、以降のセクションでさらに検討します。
必要なライブラリのインポート
本記事で説明する処理を実現するために、いくつかのPythonライブラリをインポートする必要があります。Jupyterノートブックに、以下の行を挿入します。
import numpy as nump # linear algebra
import pandas as pand # data processing, read CSV file
import seaborn as seab# data visualization
import matplotlib.pyplot as plot #calculate plots
import griddb_python as griddb #application database
データセットの読み込み
データセットを読み込むために、前のセクションでインポートしたpandasライブラリを使用します。
telecom_customers = pand.read_csv('Churn.csv')
pandasライブラリを使ってデータセットを抽出します。head関数のおかげで、以下のような結果を得ることができます。
telecom_customers.head()
customerID gender SeniorCitizen Partner Dependents tenure PhoneService MultipleLines InternetService OnlineSecurity ... DeviceProtection TechSupport StreamingTV StreamingMovies Contract PaperlessBilling PaymentMethod MonthlyCharges TotalCharges Churn
0 7590-VHVEG Female 0 Yes No 1 No No phone service DSL No ... No No No No Month-to-month Yes Electronic check 29.85 29.85 No
1 5575-GNVDE Male 0 No No 34 Yes No DSL Yes ... Yes No No No One year No Mailed check 56.95 1889.5 No
2 3668-QPYBK Male 0 No No 2 Yes No DSL Yes
GridDB データベースモデルを構築するために、データベースの全属性を取得する必要があります。そのために、以下の行を使用します。
telecom_customers.columns.values
このコマンドは、すべての属性名を含む配列を出力します。
array(['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection',
'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract',
'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges',
'TotalCharges', 'Churn'], dtype=object)
ただし、GridDB のデータベースモデルとマッピングするためには、これらの属性の データ型を知る必要があります。このために、以下の行を使用します。
Telecom_customers.dtypes
そして、すべての属性の型を取得します。
customerID object
gender object
SeniorCitizen int64
Partner object
Dependents object
tenure int64
PhoneService object
MultipleLines object
InternetService object
OnlineSecurity object
OnlineBackup object
DeviceProtection object
TechSupport object
StreamingTV object
StreamingMovies object
Contract object
PaperlessBilling object
PaymentMethod object
MonthlyCharges float64
TotalCharges object
Churn object
dtype: objec
まず、データセット内の NULL 値を検出して、任意の値に置き換えることから始めます。また、customerID カラムは、今回のデータモデルには関係ないので削除します。さらに、GridDB のデータアーキテクチャに合わせて、churn 属性の値を Yes/No から True/False の真偽値に置き換えます。実際、ほとんどの属性を真偽値で定義するので、データセットのすべてのカテゴリ属性でこの処理を行います。これは、以下のコードで実現できます。
telecom_customers.dropna(inplace = True)
dataframe = telecom_customers.iloc[:,1:]
dataframe['Churn'].replace(to_replace='Yes', value=True, inplace=True)
dataframe['Churn'].replace(to_replace='No', value=False, inplace=True)
また、カテゴリ属性はすべてダミー変数に置き換えます。このダミー変数が機械学習アルゴリズムの構築に使用されることは、後のセクションで説明します。
dataframeDummies = pand.get_dummies(dataframe)
dataframeDummies.head()
性別のような属性は、オブジェクトとしてではなく、真偽値として扱われることが分かります。これを踏まえて、データセットの各属性をGridDBにマッピングすることで、GridDBデータベースモードの構築を開始します。
conInfo = griddb.ContainerInfo("column1",
[["customerID", griddb.Type.STRING],
["gender", griddb.Type.STRING],
["SeniorCitizen", griddb.Type.BOOL],
["Partner", griddb.Type.BOOL],
["Dependents", griddb.Type.BOOL],
["tenure", griddb.Type.LONG],
["PhoneService", griddb.Type.BOOL],
["MultipleLines", griddb.Type.BOOL],
["InternetService", griddb.Type.STRING],
["OnlineSecurity", griddb.Type.BOOL],
["OnlineBackup", griddb.Type.BOOL],
["DeviceProtection", griddb.Type.BOOL],
["TechSupport", griddb.Type.BOOL],
["StreamingTV", griddb.Type.BOOL],
["StreamingMovies", griddb.Type.BOOL],
["Contract", griddb.Type.String],
["PaperlessBilling", griddb.Type.BOOL],
["PaymentMethod", griddb.Type.STRING],
["MonthlyCharges", griddb.Type.FLOAT],
["TotalCharges", griddb.Type.FLOAT],
["Churn", griddb.Type.BLOB]],
griddb.ContainerType.COLLECTION, True)
col = gridstore.put_container(conInfo)
GridDBのインスタンスやストアの取得、コレクションの作成方法については、GitHubの公式リポジトリに複数の PythonでのGridDB用サンプルが掲載されていますので、そちらをご覧下さい。
モデルの主キーであるcustomerIDにインデックスを追加することを忘れないでください。
col.create_index("customerID", griddb.IndexType.DEFAULT)
次に、データセットのデータを取得し、GridDBに格納する必要があります。これは以下のコードで実現します。
filename = 'churn.csv'
with open(filename, 'r') as csvfile:
datareader = csv.reader(csvfile)
for row in datareader:
toGriddb = col.put(row)
col.commit();
データが正しくアップロードされたことを確認するために、クエリーを実行します。
query=col.query("select * where gender = 'Female'")
GridDBが正常にデータを保持することを確認した後、探索的なデータ分析を続けましょう。
探索的データ解析
この時点で、探索的なデータ分析を行う準備が整いました。まず、データセット内の属性と、今回の研究の主眼である解約属性との相関を確立することから始める必要があります。この相関関係を得るには、次のようなコードを使用します。
plot.figure(figsize=(15,8))
dataframe_dummies.corr()['Churn'].sort_values(ascending = False).plot(kind='bar')
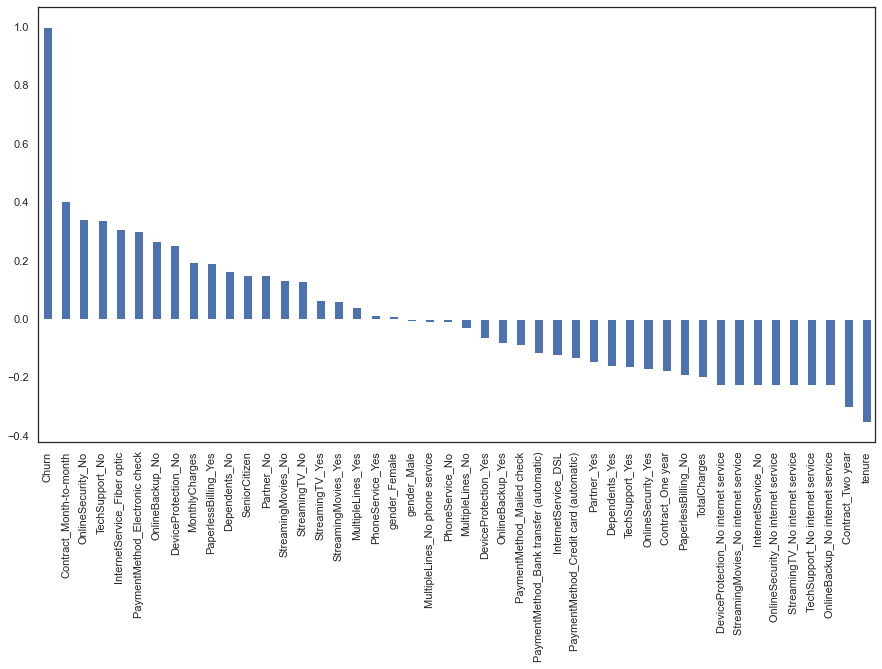
この相関グラフの結果を分析してみましょう。右から順に、解約の属性を観察すると、予想通り、それ自体との相関は1です。また、解約と相関が高い属性は、契約 (contracts)、オンライン・セキュリティ (online security)、テクニカル・サポート (technical support) です。一方、グラフの右側を見てみると、2年契約 (two-year contracts)、顧客との取引月数 (tenure) は、解約と負の相関があることが分かります。
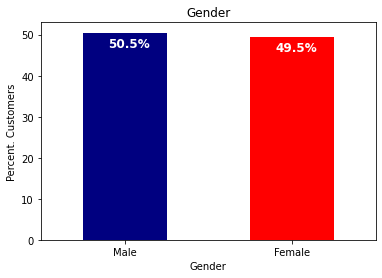
さて、研究の興味に応じて、matplotlib.ticker ライブラリを用いて、データセットの様々な変数をプロットすることができます。デモの目的のために、データセットのgender変数をプロットして、男性と女性の顧客のパーセンテージを見たいと思います。これは次のコードで実現できます。
colors = ['#000080','#FF0000']
ax = (telecom_customers['gender'].value_counts()*100.0 /len(telecom_customers)).plot(kind='bar',stacked = True,rot = 0,color = colors)
ax.set_ylabel('Percent. Customers')
ax.set_xlabel('Gender')
ax.set_ylabel('Percent. Customers')
ax.set_title('Gender')
totals = []
for i in ax.patches:
totals.append(i.get_width())
total = sum(totals)
for i in ax.patches:
ax.text(i.get_x()+.15, i.get_height()-3.5, \
str(round((i.get_height()/total), 1))+'%',
fontsize=12,
color='white',
weight = 'bold')
そして、以下のようなグラフを出力します。
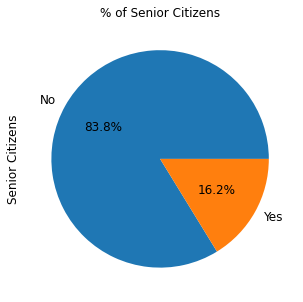
別の例として、同じようなコードを使って、顧客をシニア層別にプロットしてみましょう。
ax = (telecom_customers['SeniorCitizen'].value_counts()*100.0 /len(telecom_customers))\
.plot.pie(autopct='%.1f%%', labels = ['No', 'Yes'],figsize =(5,5), fontsize = 12 )
ax.set_ylabel('Senior Citizens',fontsize = 12)
ax.set_title('% of Senior Citizens', fontsize = 12)
以下の円グラフが得られます。
さて、データの準備ができたので、いよいよ顧客の解約率を予測することにします。次の章では、今回使用した機械学習モデルで解約率を予測する方法を説明します。
機械学習モデル
モデルを構築する前に、我々はすでにすべてのカテゴリー変数をダミー属性に変換したことを思い起こす必要があります。この処理により、データセットの全ての属性に対して機械学習の実装が容易になり、複数の関数を使用する必要がなくなります。実際、我々は以前のセクションで作成したこのダミーデータフレームを使用し、また、アルゴリズムに適したように、変数を0と1の間の値にスケーリングする予定です。この2つの操作は以下のコードで実現されます。
y = dataframe_dummies['Churn'].values
X = dataframe_dummies.drop(columns = ['Churn'])
from sklearn.preprocessing import MinMaxScaler
features = X.columns.values
scaler = MinMaxScaler(feature_range = (0,1))
scaler.fit(X)
X = pand.DataFrame(scaler.transform(X))
X.columns = features
機械学習アルゴリズムを使用するためには、学習データとテストデータの両方を提供するために、データセットをランダムに分割する必要があります。これは以下のコードで実現されます。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
今回の研究では、ロジスティック回帰モデルを用いて解約率を予測することにします。まず、学習データに回帰モデルを当てはめることから始めましょう。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
result = model.fit(X_train, y_train)
モデル評価
この時点で、モデルを実行する準備が整いました。そのために、LogisticRegressionライブラリのpredict()関数を用いて、実際のテストデータに対して予測を行います。得られた精度は、正しく分類されたインスタンスの80%であることが分かります。
from sklearn import metrics
from sklearn.metrics import classification_report, confusion_matrix
prediction_test = model.predict(X_test)
# Print results & confusion matrix
print (metrics.accuracy_score(y_test, prediction_test))
print(confusion_matrix(y_test,prediction_test))
0.8075829383886256
では、混同行列の解釈の仕方を見ていきましょう。
[1418 162]
[ 244 286]
この結果から、1418と286がそれぞれ真陽性と偽陽性、つまり正しく分類されたインスタンス(この場合、顧客が解約する可能性)であることが観察されます。これらのインスタンスの合計は1704であり、全2110インスタンスの80%に相当します。
結論
今回はPythonの機械学習アルゴリズムを用いて、通信業界の解約率を予測してみました。また、データを格納するデータベースとしてGridDBを使用しました。
この記事をさらに一歩進めたい場合は、この記事で提供される例と同様の方法で実行できる他の分類アルゴリズムで試すことができます。詳しくは、オープンソースのノートブックをご覧ください。