今回は、GridDBを使って気象データを可視化・分析する方法を紹介します。CSVファイルで提供されているデータセットをGridDBにロードし、GridDBからデータを取得してデータ分析を行います。気象データセットを使用します。
この記事の全ソースコードはこちら をご覧ください。
GridDBにデータをロードし、GridDBからデータを取得する
var griddb = require('griddb_node');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
const csvWriter = createCsvWriter({
path: 'out.csv',
header: [
{id: "DATE", title:"DATE"},
{id: "WIND", title:"WIND"},
{id: "IND", title:"IND"},
{id: "RAIN", title:"RAIN"},
{id: "IND.1", title:"IND.1"},
{id: "T.MAX", title:"T.MAX"},
{id: "IND.2" , title:"IND.2"},
{id: "T.MIN", title:"T.MIN"},
{id: "T.MIN.G", title:"T.MIN.G"},
]
});
const factory = griddb.StoreFactory.getInstance();
const store = factory.getStore({
"host": '239.0.0.1',
"port": 31999,
"clusterName": "defaultCluster",
"username": "admin",
"password": "admin"
});
// For connecting to the GridDB Server we have to make containers and specify the schema.
const conInfo = new griddb.ContainerInfo({
'name': "windspeedanalysis",
'columnInfoList': [
["name", griddb.Type.STRING],
["DATE", griddb.Type.STRING],
["WIND", griddb.Type.STRING],
["IND", griddb.Type.STRING],
["RAIN", griddb.Type.STRING],
["IND.1", griddb.Type.STRING],
["T.MAX", griddb.Type.STRING],
["IND.2", griddb.Type.STRING],
["T.MIN", griddb.Type.STRING],
["T.MIN.G", griddb.Type.STRING]
],
'type': griddb.ContainerType.COLLECTION, 'rowKey': true
});
const csv = require('csv-parser');
const fs = require('fs');
var lst = []
var lst2 = []
var i =0;
fs.createReadStream('./dataset/windspeed.csv')
.pipe(csv())
.on('data', (row) => {
lst.push(row);
console.log(lst);
})
.on('end', () => {
var container;
var idx = 0;
for(let i=0;i<lst.length;i++){
// lst[i]['DATE'] = String(lst[i]["DATE"])
// lst[i]['WIND'] = parseFloat(lst[i]["WIND"])
// lst[i]['IND'] = parseInt(lst[i]["IND"])
// lst[i]['RAIN'] = parseFloat(lst[i]["RAIN"])
// lst[i]['IND.1'] = parseInt(lst[i]["IND.1"])
// lst[i]['T.MAX'] = parseFloat(lst[i]["T.MAX"])
// lst[i]['IND.2'] = parseInt(lst[i]["IND.2"])
// lst[i]['T.MIN'] = parseFloat(lst[i]["T.MIN"])
// lst[i]['T.MIN.G'] = parseFloat(lst[i]["T.MIN.G"])
store.putContainer(conInfo, false)
.then(cont => {
container = cont;
return container.createIndex({ 'columnName': 'name', 'indexType': griddb.IndexType.DEFAULT });
})
.then(() => {
idx++;
container.setAutoCommit(false);
return container.put([String(idx), lst[i]['DATE'],lst[i]["WIND"],lst[i]["IND"],lst[i]["RAIN"],lst[i]["IND.1"],lst[i]["T.MAX"],lst[i]["IND.2"],lst[i]["T.MIN"],lst[i]["T.MIN.G"]]);
})
.then(() => {
return container.commit();
})
.catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
}
store.getContainer("windspeedanalysis")
.then(ts => {
container = ts;
query = container.query("select *")
return query.fetch();
})
.then(rs => {
while (rs.hasNext()) {
let rsNext = rs.next()
lst2.push(
{
'DATE': rsNext[1],
"WIND": rsNext[2],
"IND": rsNext[3],
"RAIN": rsNext[4],
"IND.1": rsNext[5],
"T.MAX": rsNext[6],
"IND.2": rsNext[7],
"T.MIN": rsNext[8],
"T.MIN.G": rsNext[9],
}
);
}
csvWriter
.writeRecords(lst2)
.then(()=> console.log('The CSV file was written successfully'));
return
}).catch(err => {
if (err.constructor.name == "GSException") {
for (var i = 0; i < err.getErrorStackSize(); i++) {
console.log("[", i, "]");
console.log(err.getErrorCode(i));
console.log(err.getMessage(i));
}
} else {
console.log(err);
}
});
});
注意:htmlファイルでd3.jsを実行するには、GridDBから取得したデータを含む出力csvファイルを読み込むために、まずhttpsサーバーを実行する必要があります。
データの可視化
表のプロットや描画を行うために、データを元に文書を操作することができるライブラリ「D3.js」を使用します。このライブラリにより、HTMLのDOM操作や視覚化が可能です。
まず、データセットの最初の数行を印刷して、データの感触をつかむことから始めましょう。この目的のために、データを作成して html テーブルに挿入するコードを書かなければなりません。これはヘルパーコードとなり、ソースファイルに含まれることになりますが、この記事の範囲外です。
これができたら、表を印刷するためのコードを書きます。
let result = data.flatMap(Object.keys);
result = [...new Set(result)];
tables("data_table",data,result,true)
上のコードで、resultはデータの列の配列、data_tableはデータを挿入するテーブルのHTML要素IDです。最後の引数は、上位5行を表示するためのフラグで、ここではtrueに設定しています。
ここで、私たちのコードの結果をご覧ください。
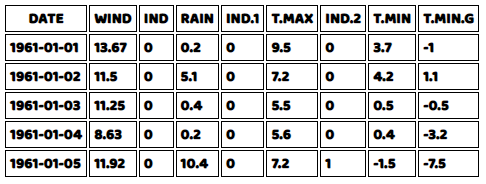
さて、データの種類を確認したところで、今度はデータのすべての数値列に関連するさまざまな統計のサマリーを見たいと思います。 HTML文書への表の描画には同じヘルパー関数が使えますが、要約されたすべての数量を取得するコードを書く必要があります。 最小値、最大値、偏差値、平均値、中央値、そしてデータ内でNULLでない行のカウントを取得することになります。幸いなことに、D3.jsはこれらのほとんどについて関数を提供していますが、NULLでない行のカウントについてはヘルパー関数を作成する必要があります。単純にforループを書いて、その列の行がNULLでなければ値をインクリメントし、最後にその値を返せばいいのです。
const countNotNull = (array) => {
let count = 0
for(let i = 0; i < array.length; i++){
if(isNaN(parseInt(array[i]))==false && array[i]!==null){ count++ }}
return count
};
これで、データセットの要約データを取得するためのforループが書けるようになりました。この表を描くために、IDが "data_table2 "のHTML要素を使用します。
let obj = {}
let summary_data = []
for(let i = 0; i < result.length; i++){
obj[result[i]] = data.map(function(elem){return elem[result[i]]});
let count = 0
let summarize = {}
if(result[i]!='DATE'){
obj[result[i]] = obj[result[i]].map(Number)
}
summarize['Field'] = result[i]
summarize['Max'] = d3.max(obj[result[i]])
summarize['Min'] = d3.min(obj[result[i]])
summarize['Deviation'] = d3.deviation(obj[result[i]])
summarize['Mean'] = d3.mean(obj[result[i]])
summarize['Median'] = d3.median(obj[result[i]])
summarize['Count Not Null'] = countNotNull(obj[result[i]])
summary_data.push(summarize)
}
let result2 = summary_data.flatMap(Object.keys)
result2 = [...new Set(result2)];
tables("data_table2",summary_data,result2,false)
結果は以下のようになるはずです。
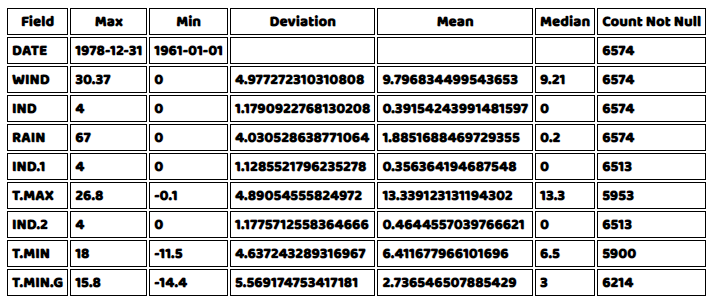
さて、ヒストグラムと箱ひげ図の形で、データの各列の実際の分布を見たいと思います。どちらのプロットでも、ソースファイルで提供されているヘルパー関数を記述する必要があります。これらのヘルパー関数を書いたら、メインのjavascriptファイルの中で直接呼び出すことができます。
## WindSpeed
histogram("my_dataviz",obj['WIND'],'Average Wind Speed')
boxplot("my_dataviz",obj['WIND'],"Wind Speed")
## Precipitation
histogram("my_dataviz2",obj['RAIN'],'Precipitation (Rain)',"orange")
boxplot("my_dataviz2",obj['RAIN'],"Precipitation (Rain)",'brown')
## Max Temperature
histogram("my_dataviz3",obj['T.MAX'],'Max Temperature',"green")
boxplot("my_dataviz3",obj['T.MAX'],"Max Temperature",'yellow')
## Min Temperature
histogram("my_dataviz4",obj['T.MIN'],'Min Temperature',"purple")
boxplot("my_dataviz4",obj['T.MIN'],"Min Temperature",'pink')
## Minimum Grass Temperature
histogram("my_dataviz5",obj['T.MIN.G'],'Minimum Grass Temperature',"cyan")
boxplot("my_dataviz5",obj['T.MIN.G'],"Minimum Grass Temperature",'orange')
## Indicator Variable
histogram("my_dataviz6",obj['IND'],'Indicator')
## Indicator Variable 1
histogram("my_dataviz7",obj['IND.1'],'Indicator 1',"orange")
## Indicator Variable 2
histogram("my_dataviz8",obj['IND.2'],'Indicator 2',"green")
これらのプロット関数のそれぞれにおいて、最初の引数はプロットを描きたいhtml要素のID、次にプロットしたいデータのカラムの配列、そしてタイトルとCSS互換のカラーコードです。Webサーバーからhtmlファイルを開けば、結果を可視化することができます。
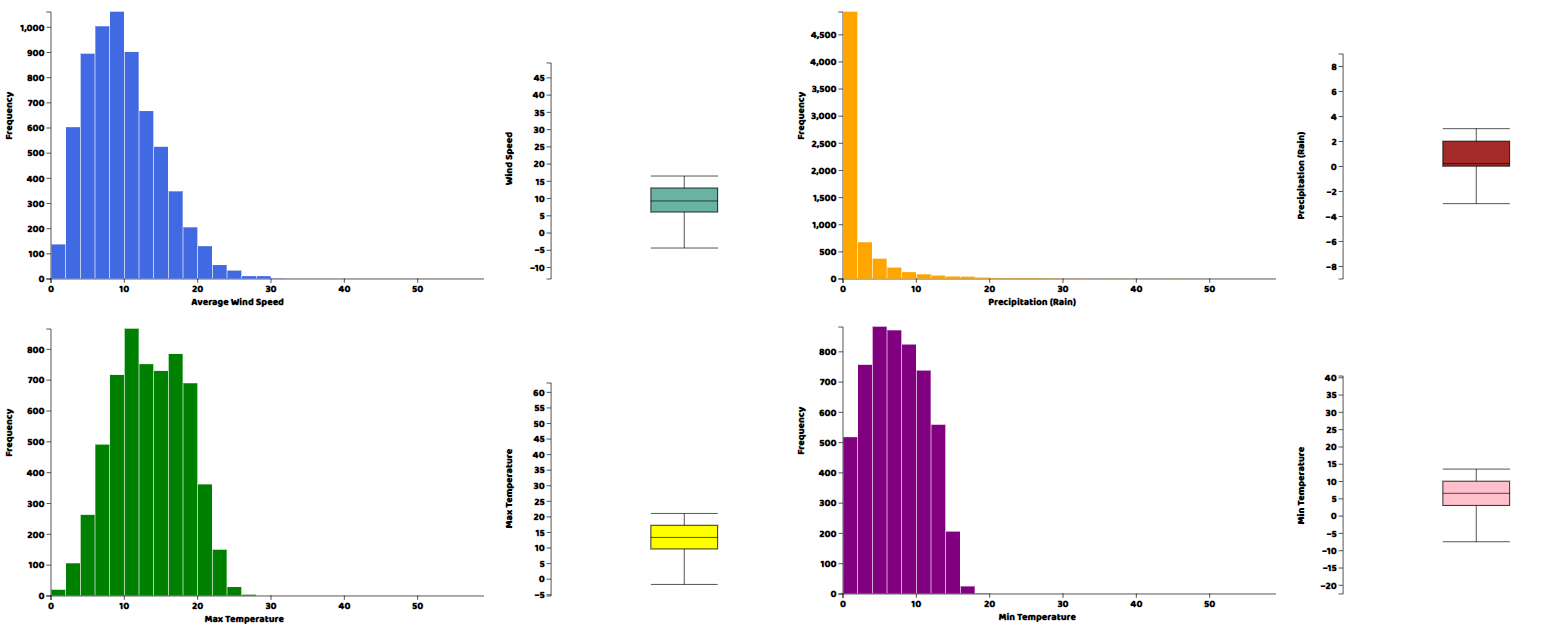
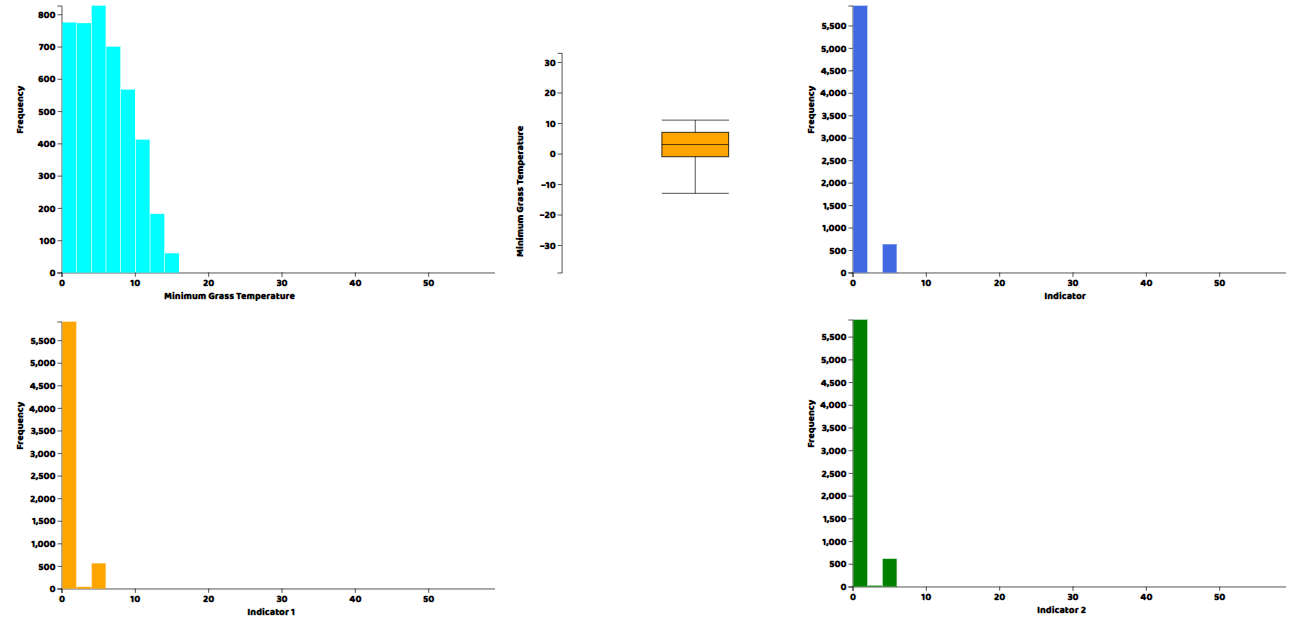
分布のプロットを見てきましたが、このデータは時系列なので、データのトレンドやパターンを可視化するために、時間に対する列のプロットも行う必要があります。そこで、データセットの各変数を折れ線グラフにすることにします。lineplot()関数は私たちが作成したもので、ソースファイルに含まれています。
lineplot("my_dataviz9",data,obj,'DATE','WIND','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','RAIN','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','T.MAX','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','T.MIN','#4169e1')
lineplot("my_dataviz9",data,obj,'DATE','T.MIN.G','#4169e1')
そして、その結果がこちらです。
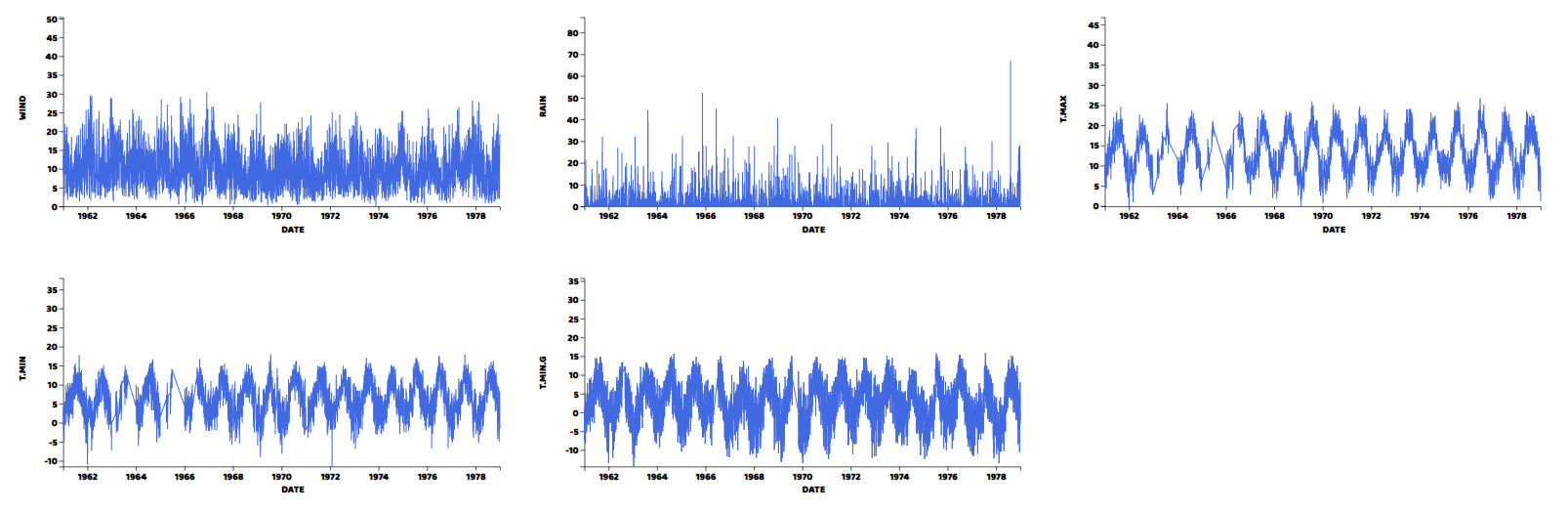
グラフから、すべての変数が気象データから予想される周期的なパターンを持ち、ヒストグラムで示されたとおりの平均値を持つことが分かります。
最後に、相関行列をプロットして、どの列がお互いに相関しているかを見ることができます。これは予測をするときに重要なことで、ターゲット変数と相関する変数をモデルに含め、お互いに相関する変数を除外したいと思うからです。データを引数としてcorrelogram()関数を呼び出すだけで、相関行列が得られます。correlogram()は、ソースファイルにあるcorrel.jsファイルから得られます。
correlogram(data)
そして、相関行列はこのようになります。
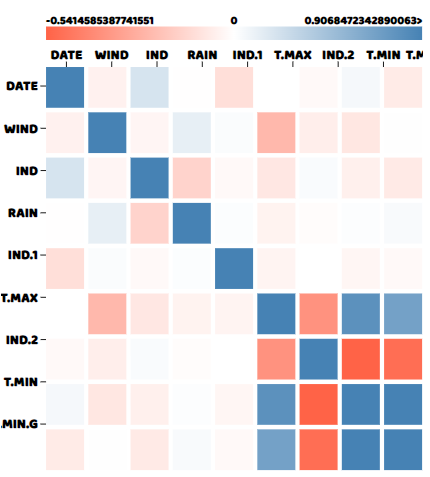
この記事の全ソースコードはこちらをご覧ください。
相関行列から、T.MIN と T.MIN.G は互いに高い相関があり、T.MIN と IND2 は負の相関があることが分かります。他の変数はほとんど互いにゼロに近い相関を持っていますが、これは予想されることです。