スマートフォンの普及に伴い、開発者はAndroidとiOSの両方のプラットフォームで、より多くのモバイルアプリケーションを作成するようになりました。携帯電話の約70%がAndroidを搭載しており、Androidはより多くの人々に利用されています。 このプロジェクトでは、Google Play ストアのデータを調査し、登録されたアプリケーションの情報に基づいてアプリと人気度に関する洞察を得る予定です。
GridDBを使ったデータセットのエクスポートとインポート
GridDBは、高いスケーラビリティとインメモリNo SQLデータベースで、特に当社の膨大なデータセットに対して、より高いパフォーマンスと効率性を実現するための並列処理を可能にします。IoTやビッグデータ技術に対応した時系列データベースに最適化されています。GridDB-pythonクライアントを利用することで、GridDBとpythonを簡単に接続し、リアルタイムにデータのインポートやエクスポートに利用することが可能です。
GridDBのセットアップ
まず第一に、GridDBがシステムに正しくインストールされていることを確認する必要があります。当サイトで公開しているステップバイステップガイドは、異なるOSでのGridDBのセットアップを支援するものです。
データセット
CSV 'apps.csv' に格納された Google Play ストアのデータセットを使用します。これは、Google Play上のアプリケーションのすべての詳細が含まれています。評価、サイズ、ダウンロード数など、13の特徴で与えられたアプリを説明します。
前処理
GridDBにデータをエクスポートする前に、いくつかの前処理を行い、GridDBが最適なパフォーマンスを発揮できるようにデータをクリーニングします。まず、生データを CSV ファイルとして読み込みます。
apps_with_duplicates = pd.read_csv('datasets/apps.csv', index_col=0)
データセットをdataframeとして保存し、クリーニング処理を開始します。アプリのデータセットから、重複やNULL値を削除していきます。また、今回の分析に不要な列を削除し、インデックス列をリセットしてデータの不一致を回避します。
apps = apps_with_duplicates.drop_duplicates()
apps.dropna(inplace=True)
apps.drop(['Genres','Content Rating', 'Last Updated', 'Current Ver', 'Android Ver'],axis = 1)
apps.reset_index(drop=True, inplace=True)
apps.index.name = 'ID'
データセットを保存する前の最後のステップは、数値データを簡単に読めるようにするために、データセットから特殊文字を除去することです。数値の列から除去する特殊文字のリストは既に知られています。
# List of characters to remove
chars_to_remove = ['+', ',', 'M', '$']
# List of column names to clean
cols_to_clean = ['Installs', 'Size', 'Price']
# Loop for each column
for col in cols_to_clean:
# Replace each character with an empty string
for char in chars_to_remove:
#print(col)
#print(char)
apps[col] = apps[col].astype(str).str.replace(char, '')
apps[col] = pd.to_numeric(apps[col])
GridDBにアップロードする前に、データフレームを端末のローカルコピーとして保存しておきます。
apps.to_csv("apps_processed.csv")
データセットをGridDBにエクスポートする
では、GridDBにデータをアップロードしていきます。そのために、ローカルドライブから処理済みのCSVファイルを読み込んで、異なるdataframeに保存します。
#read the cleaned data from csv
apps = pd.read_csv("apps_processed.csv")
次に、行情報を挿入する前にデータベースのデザインを生成できるように、アプリのコラム情報をGridDBに渡すためのコンテナを作成します。
#Create container
apps_container = "apps_container"
# Create containerInfo
apps_containerInfo = griddb.ContainerInfo(apps_container,
[["ID", griddb.Type.INTEGER],
["App", griddb.Type.STRING],
["Category", griddb.Type.STRING],
["Rating", griddb.Type.FLOAT],
["Reviews", griddb.Type.FLOAT],
["Size", griddb.Type.FLOAT],
["Installs", griddb.Type.STRING],
["Type", griddb.Type.STRING],
["Price", griddb.Type.FLOAT]],
griddb.ContainerType.COLLECTION, True)
apps_columns = gridstore.put_container(apps_containerInfo)
スキーマが完成したら、行単位のデータをGridDBに挿入していきます。
# Put rows
apps_columns.put_rows(apps)
これで、GridDBプラットフォームへのデータアップロードに成功しました。
GridDBからデータセットをインポートする
コンテナを作成し、SQLに似た問い合わせ言語であるTQLコマンドを使って関連する行を問い合わせることで、簡単にGridDBからデータを抽出することが出来ます。2つのデータセットを別々に保存するために、異なるコンテナと変数を使用します。
# Define the container names
apps_container = "apps_container"
# Get the containers
obtained_apps = gridstore.get_container(apps_container)
# Fetch all rows - language_tag_container
query = obtained_apps.query("select *")
rs = query.fetch(False)
print(f"{apps_container} Data")
# Iterate and create a list
retrieved_data= []
while rs.has_next():
data = rs.next()
retrieved_data.append(data)
# Convert the list to a pandas data frame
apps = pd.DataFrame(retrieved_data, columns=["ID","App","Category","Rating","Reviews","Size","Installs","Type","Price"])
# Get the data frame details
print(apps)
apps.info()
これで、解析に使えるデータが揃いました。
データ解析と可視化
データセットを探索し、いくつかの特徴を理解することから分析を開始します。
1. データセットに含まれる別個のアプリの総数
# Print the total number of apps
print('Total number of apps in the dataset = ', len(apps))
![]()
2. 最も高価なアプリ
Expensiveapp = apps.iloc[appdata['Price'].idxmax()]
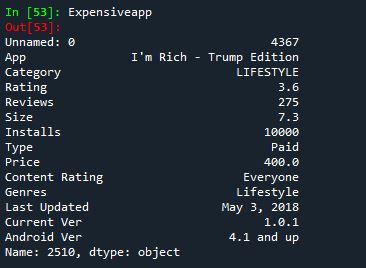
3. データセットに含まれるカテゴリーの総数
# Print the total number of unique categories
num_categories = len(apps['Category'].unique())
print('Number of categories = ', num_categories)
![]()
4. アプリの平均評価
avg_app_rating = apps['Rating'].mean()
print('Average app rating = ', avg_app_rating)
![]()
アプリケーションのさまざまな仕様に対していくつかのグラフをプロットすることで、分析を続行します。例えば、アプリをカテゴリに分類し、各カテゴリのアプリの数をプロットして、Playストア上のアプリの中で最も人気のあるカテゴリを探ります。
# Count the number of apps in each 'Category' and sort them in descending order
num_apps_in_category = apps['Category'].value_counts().sort_values(ascending = False)
num_apps_in_category.plot.bar()
plt.show()
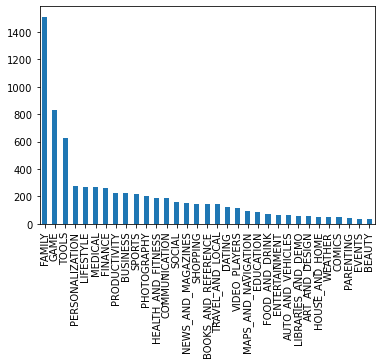
ほとんどのアプリケーションが「ファミリー」カテゴリーに属していることが分かります。このカテゴリーに属するアプリケーションの数が多い理由の1つは、ほとんどの視聴者を対象としているため、市場での成功の可能性が高いということかもしれません。
そして、このデータセットを使って、アプリのコストに対するユーザーの嗜好を洞察するのです。Google Play ストアで利用できるアプリには2種類あり、ほとんどが無料アプリ(0円)ですが、中には有料アプリもあります。ここで、有料アプリと無料アプリのインストール数を比較してみましょう。
type_installs = apps[["Installs","Type"]].groupby(by = "Type").mean()
sns.barplot(data=type_installs, x=type_installs.index , y = "Installs" )
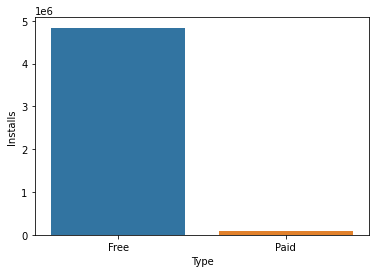
結果は予想通りです。人々は、無料のアプリケーションをダウンロードする傾向があり、通常、必要な場合を除き、お金を払うことを嫌がります。
異なるカテゴリ間でアプリの価格を比較します。データセットの中から人気のあるカテゴリをいくつか選択し、価格が100ドル未満のアプリをプロットすると、モバイルアプリケーションの開発時に使用される価格戦略についてよりよく理解することが出来ます。
# Select a few popular app categories
popular_app_cats = apps[apps.Category.isin(['GAME', 'FAMILY', 'PHOTOGRAPHY',
'MEDICAL', 'TOOLS', 'FINANCE',
'LIFESTYLE','BUSINESS'])]
# Select apps priced below $100
apps_under_100 = popular_app_cats[popular_app_cats['Price']<100]
fig, ax = plt.subplots()
fig.set_size_inches(15, 8)
# Examine price vs category with the authentic apps (apps_under_100)
ax = sns.stripplot(x='Price', y='Category', data=apps_under_100,
jitter=True, linewidth=1)
ax.set_title('App pricing trend across categories after filtering for outliers')
plt.show()
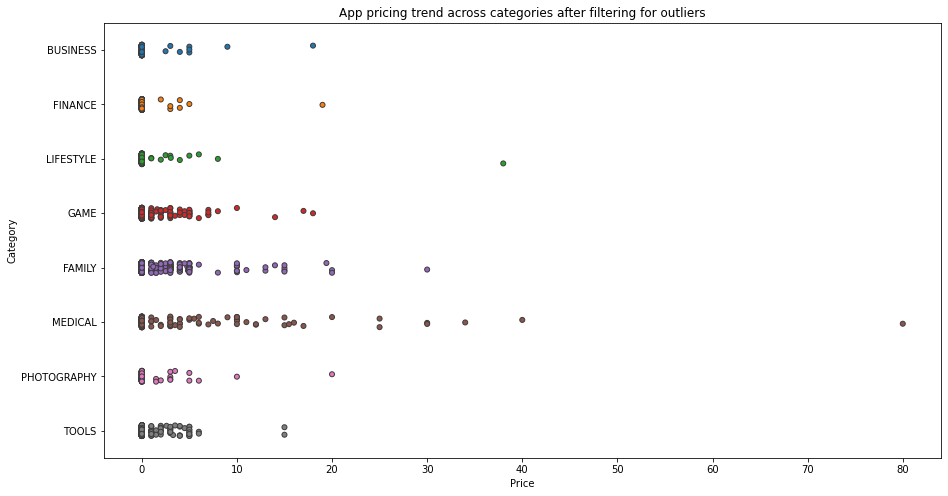
高価なアプリはビジネスや医療分野に属するものが多く、ゲーム、ツール、写真などのカテゴリに属するアプリは20ドル以下であること分かります。これは、アプリが特定されたユーザーを対象としているためです。ゲームやツール、写真アプリの多くは、レジャー目的で設計されており、これらのアプリケーションにお金をかけることを躊躇する傾向があります。彼らは主に広告やサードパーティのコラボレーションを通じて収益を得ます。
結論
素晴らしいアプリケーションを開発することはもちろん重要ですが、それと同じくらい価格設定やターゲット設定を考慮することが重要であると結論付けることができます。すべての分析は、バックエンドのGridDBデータベースを使用して行われ、シームレスかつ効率的な統合を実現しました。