はじめに
本記事では、筆者がこの前提案した、ディリクレ過程とガウス過程で民主主義の発展トレンドを分類するモデルのAPIを作成する方法を紹介する。
(本記事は上記記事の実行を省略する)
筆者が提案したモデルはパラメーター数の多いベイズモデルであるため、ただ単にパラメーターの内容を格納した表を見ても、なかなか示唆が得られない。また、パラメーターが多いため、利用者の関心次第で見たい可視化の切口が異なる。そこで、何かしらの可視化や結論をまとめた表が必要になる。
> m_summary
# A tibble: 17,164 × 7
variable mean median sd mad q5 q95
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 lp__ 14686. 14696. 221. 215. 14286. 15014.
2 lp_approx__ -4259. -4260. 65.2 64.2 -4367. -4153.
3 d_alpha 1.03 1.03 0.0186 0.0194 1.00 1.06
4 breaks[1,1] 0.00629 0.00390 0.00728 0.00343 0.000799 0.0199
5 breaks[2,1] 0.0168 0.0126 0.0148 0.00946 0.00345 0.0417
6 breaks[3,1] 0.0117 0.00749 0.0170 0.00632 0.00147 0.0355
7 breaks[4,1] 0.0101 0.00670 0.0110 0.00598 0.00112 0.0318
8 breaks[5,1] 0.762 0.765 0.0456 0.0441 0.686 0.832
9 breaks[6,1] 0.0768 0.0609 0.0600 0.0424 0.0179 0.192
10 breaks[7,1] 0.0287 0.0267 0.0114 0.0103 0.0137 0.0502
# … with 17,154 more rows
本記事ではモデルのAPIを作成して、Rの操作に不慣れなユーザーやR以外のシステムが自由にモデルの示唆を抽出する仕組みを作る方法を紹介する。
前回の記事で紹介した内容は、各グループのトレンドというマクロな可視化に焦点を絞ったが、本記事では各国の状況を可視化するというミクロな観点を中心に、RのplumberでAPIを作成する方法を説明する。
最後に話は少し脱線するが、筆者のデータサイエンティストの経験からすると、APIはモデルが吐き出した結果(一般的には「推論結果」という)をレコメンドエンジンやダッシュボードに投入する際に必要不可欠な工程なので、API作り方の基礎はぜひ覚えていただきたい。
詳細は話せないが、筆者は現在まさに本業のデータサイエンティストの業務で計量経済学モデルをデプロイするためのAPIを作っている。
前提と注意事項
本記事で説明するAPIは、あくまでもローカルで動作するAPIであり、実際のクラウド環境でデプロイする方法はスコープ外である。ただ、ローカルで動くAPIをスモールスタートとしてとりあえず作ってみてから、クラウド環境で動くようにチューニングしていくのは悪いプロセスではないと思われる。
また、本記事で説明するAPIはセキュリティー面のことを最低限しか考慮していない。もし読者が本当にRでモデルAPIを作ってオンラインでデプロイする場合、必ず所属する機関のIT・データガバナンス関連部署の担当者に相談し、指示に従ってください。
実現したい機能の説明
本項目では、まずAPIで実現したい三つの機能をそれぞれ説明する。
指定した国が所属する民主主義発展トレンドグループの抽出
ここで実現したいことは簡単で、指定した国が所属する民主主義発展トレンドグループを抽出すればいい。
まず、前回の記事で作成したinferred_group(予測されたグループ番号)をcountry_masterに追加して、国名でfilterをかければ良い。
たとえば、日本はグループ1に所属しており、前回の記事でも説明したように、いわゆる比較的後から民主主義が発展したグループである。
> country_master %>%
bind_cols(inferred_group = inferred_group) %>%
filter(country_name == "Japan")
# A tibble: 1 × 3
country_name country_id inferred_group
<chr> <int> <int>
1 Japan 84 1
指定した国と民主主義発展トレンドが似ている国の抽出
二つ目は、指定した国と民主主義発展トレンドが似ている国を抽出する機能である。
具体的には、前回の記事で紹介した国が所属する民主主義発展トレンドグループの事後分布(前回の記事でいうとdp.stan)zを利用する。
zは国が持つ各グループの要素を表しているといえよう。具体的には、台湾の状況を確認すると
par(family= "HiraKakuProN-W3")
barplot(
z[which(country_master$country_name == "Taiwan"),],
main = "台湾のz",
xlab = "グループ", ylab = "確率(割合)"
)
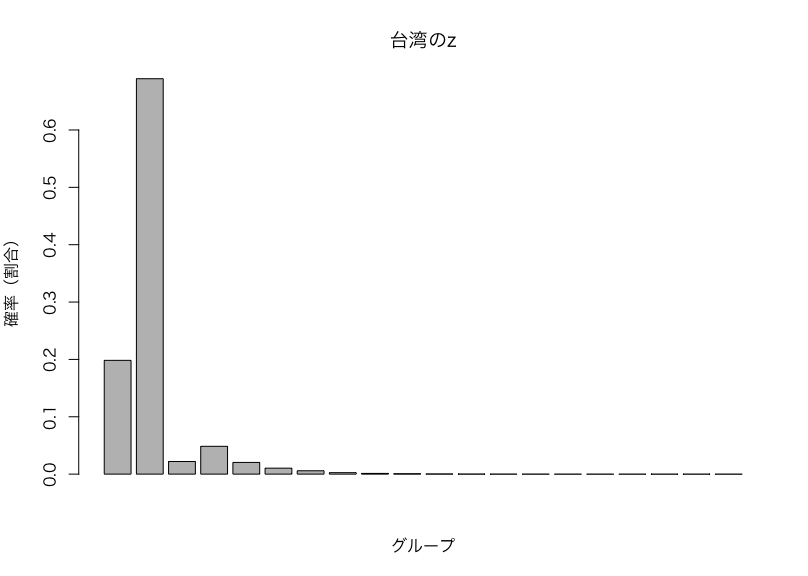
台湾はグループ2の発展特徴を最も強く表しているが(6割以上)、グループ1の要素も2割ほど持つ。要するに、全体的には前回の記事でいうノーコメントグループの特性を最も強く持つが、後発的民主主義国のグループ1の特性も持っている。
このように、各国が持つzのコサイン類似度を比較すれば、その国がどの国の発展と最も似ているかが判断できる。具体的に台湾についてみると
#台湾のcountry_masterにおけるIDを抽出
> taiwan_id <- country_master$country_id[which(country_master$country_name == "Taiwan")]
#コサイン類似度格納用
> cos_sim <- c()
> for (i in 1:nrow(country_master)){
cos_sim[i] <- (z[taiwan_id,] %*% z[i,])/sqrt(sum(z[taiwan_id,]^2) * sum(z[i,]^2))
}
>
> country_master %>%
bind_cols(cos_sim = cos_sim) %>%
arrange(-cos_sim) %>%
head(10)
# A tibble: 10 × 3
country_name country_id cos_sim
<chr> <int> <dbl>
1 Taiwan 172 1
2 Tuscany 183 0.999
3 Cuba 40 0.998
4 Parma 135 0.997
5 South Korea 162 0.995
6 Two Sicilies 184 0.994
7 Cape Verde 31 0.990
8 Saxony 150 0.987
9 South Sudan 163 0.985
10 Egypt 48 0.984
このように、既に消滅した国もあるが、韓国と発展が似ているなど政治学で解釈できる結果が出ている。
指定した国との民主主義発展トレンド類似度を地図上での可視化
最後に、指定した国とのコサイン類似度を地図上で可視化する方法を説明する。
まず、世界地図情報が必要なのでmapというパッケージを入れる。次に、指定する国(ここではフランス)
library(map)
#フランスのIDを取り出す
france_id <- country_master$country_id[which(country_master$country_name == "France")]
#全ての国と入力された国のコサイン類似度を計算する
cos_sim <- c()
for (i in 1:nrow(country_master)){
cos_sim[i] <- (z[france_id,] %*% z[i,])/sqrt(sum(z[france_id,]^2) * sum(z[i,]^2))
}
#マップ作成
g <- map_data("world") %>%
#コサイン類似度を追加したcountry_masterを世界地図データにLEFT JOINする
left_join(country_master %>%
#名寄せ
mutate(
country_name = case_when(
country_name == "United States of America" ~ "USA",
country_name == "United Kingdom" ~ "UK",
country_name == "Burma/Myanmar" ~ "Myanmar",
TRUE ~ country_name
)
) %>%
bind_cols(cos_sim = cos_sim),
by = c("region" = "country_name")) %>%
ggplot(aes(x = long, y = lat, group = group)) +
geom_polygon(aes(fill = cos_sim), size = 0.1) +
scale_fill_continuous(name = str_c("cosine similarity"), low = "white", high = "blue") +
ggtitle("cosine similarity with France")
ここでgを実行すると下記の世界地図が出てくる。
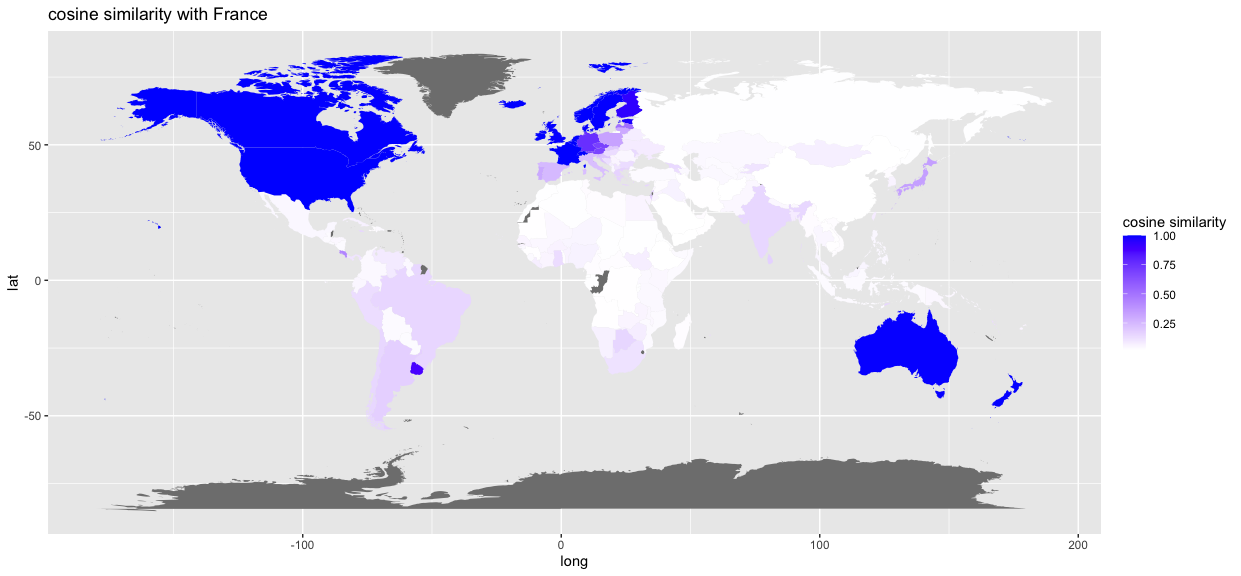
この世界地図で、国の色が青ければ青いほど、フランスのzとのコサイン類似度が高い。要するに、フランスの民主主義の発展の類似度が高い。
地図の中身を説明すると、フランスの民主主義の発展と似たような民主主義の発展を辿った国は、だいたい西ヨーロッパ、北米、およびオーストラリアとニュージーランドになっている。自分の勉強不足で今後はより多くの文献を読むが、南米の色がアフリカとアジアより濃いのは興味深いと思った。
これはあくまでも個人的な意見だが、このように結果を地図上で表示した方が、単純なコサイン類似度の表データよりわかりやすいと思われる。
API作成
コード
API作成で利用するplumberというパッケージは便利で、上記の三つの処理を関数化すればほぼ問題ない。
plumberの使い方に関して筆者も下記のサイトを参考にまだ勉強しているが、
内容を簡単に説明すると、#* @get /XXXと書けば、APIを利用してXXXの後に定義される関数をXXXで呼び出し、必要な引数を渡して実行できる。また、#* @serializer pngを入れれば出力が画像になる。
コードの内容は上の「実現したい機能の説明」のところで紹介した内容とほぼ変わらないため、詳細の説明は省く。また、ファイル名はgpdp_api.Rにした。
library(tidyverse)
library(maps)
#* @apiTitle ディリクレ・ガウス過程モデルAPI
#* @apiDescription ディリクレ・ガウス過程モデルの様々なQOIを返却するAPI
#* @param country_name 対象の国名
#* @get /get_country_group
function(country_name){
#安全性のため、APIが予期しない入力を受け取ったら実行を終了する
if (country_name %in% country_master$country_name == FALSE){
return("正しくない国名です。")
}else{
#二度手間になるが、安全性のため、ユーザーが入力した内容をそのままモデルに入れない
#信頼できるユーザーしかアクセスしないなら、下記のコードを requested_country_name <- country_name に変更しても良い
requested_country_name <- country_master$country_name[which(country_master$country_name == country_name)]
return(
country_master %>%
bind_cols(inferred_group = inferred_group) %>%
filter(country_name == requested_country_name)
)
}
}
#* @param country_name 対象の国名
#* @get /get_cos_sim
function(country_name){
#安全性のため、APIが予期しない入力を受け取ったら実行を終了する
if (country_name %in% country_master$country_name == FALSE){
return("正しくない国名です。")
}else{
#ユーザーが入力した国名に対応する国IDを取り出す
requested_country_id <- country_master$country_id[which(country_master$country_name == country_name)]
cos_sim <- c()
#全ての国と入力された国のコサイン類似度を計算する
for (i in 1:nrow(country_master)){
cos_sim[i] <- (z[requested_country_id,] %*% z[i,])/sqrt(sum(z[requested_country_id,]^2) * sum(z[i,]^2))
}
return(
country_master %>%
bind_cols(cos_sim = cos_sim) %>%
arrange(-cos_sim) %>%
head(10)
)
}
}
#* @param country_name 対象の国名
#* @get /plot_cos_sim
#* @serializer png
function(country_name){
if (country_name %in% country_master$country_name == FALSE){
return("正しくない国名です。")
}else{
#ユーザーが入力した国名に対応する国名とIDを取り出す
requested_country_name <- country_master$country_name[which(country_master$country_name == country_name)]
requested_country_id <- country_master$country_id[which(country_master$country_name == country_name)]
cos_sim <- c()
#全ての国と入力された国のコサイン類似度を計算する
for (i in 1:nrow(country_master)){
cos_sim[i] <- (z[requested_country_id,] %*% z[i,])/sqrt(sum(z[requested_country_id,]^2) * sum(z[i,]^2))
}
requested_map <- map_data("world") %>%
left_join(country_master %>%
mutate(
country_name = case_when(
country_name == "United States of America" ~ "USA",
country_name == "United Kingdom" ~ "UK",
country_name == "Burma/Myanmar" ~ "Myanmar",
TRUE ~ country_name
)
) %>%
bind_cols(cos_sim = cos_sim),
by = c("region" = "country_name")) %>%
ggplot(aes(x = long, y = lat, group = group)) +
geom_polygon(aes(fill = cos_sim), size = 0.1) +
scale_fill_continuous(name = str_c("cosine similarity"), low = "white", high = "blue") +
ggtitle(str_c("cosine similarity with ", requested_country_name))
print(requested_map)
}
}
では、早速APIのコードを実行してみよ
library(plumber)
pr("gpdp_api.R") %>%
pr_run()
実行すれば、このようなウィンドウが出てくる。
このウィンドウの上の方にあるOpen in Browserを押せばデフォルトのブラウザで開かれる。
では、APIをテストするため、下のGET /get_country_groupのところを開いてみると
こんな画面が出てくる。右上のTry it outを押せば下の対象の国名を入力することができるようになる。ここで、とりあえずJapanを入れてみる
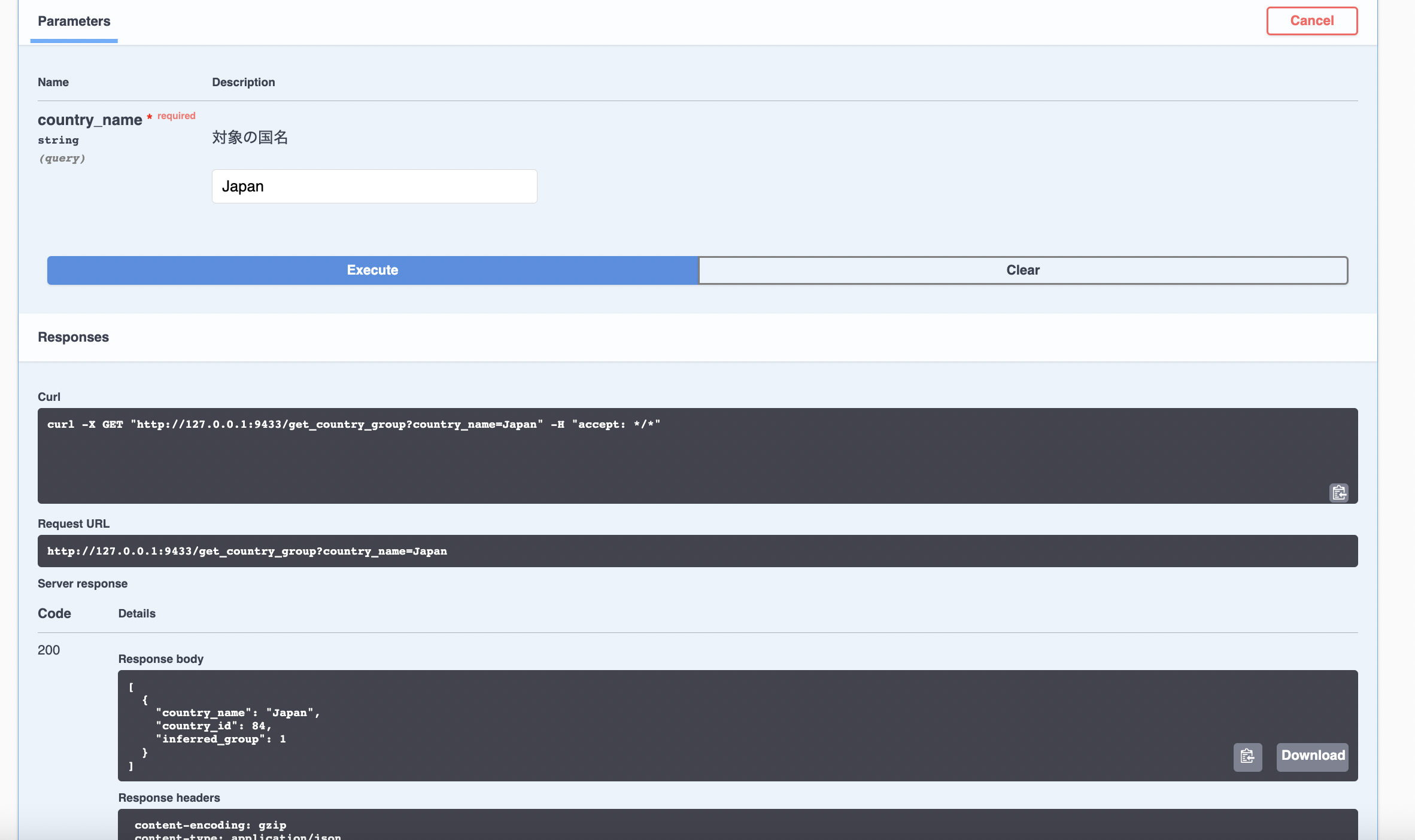
このように、日本がグループ1に属している結果がJSONファイル形式で返却された。
次に、下のGET /get_cos_simにFranceを入れてみると
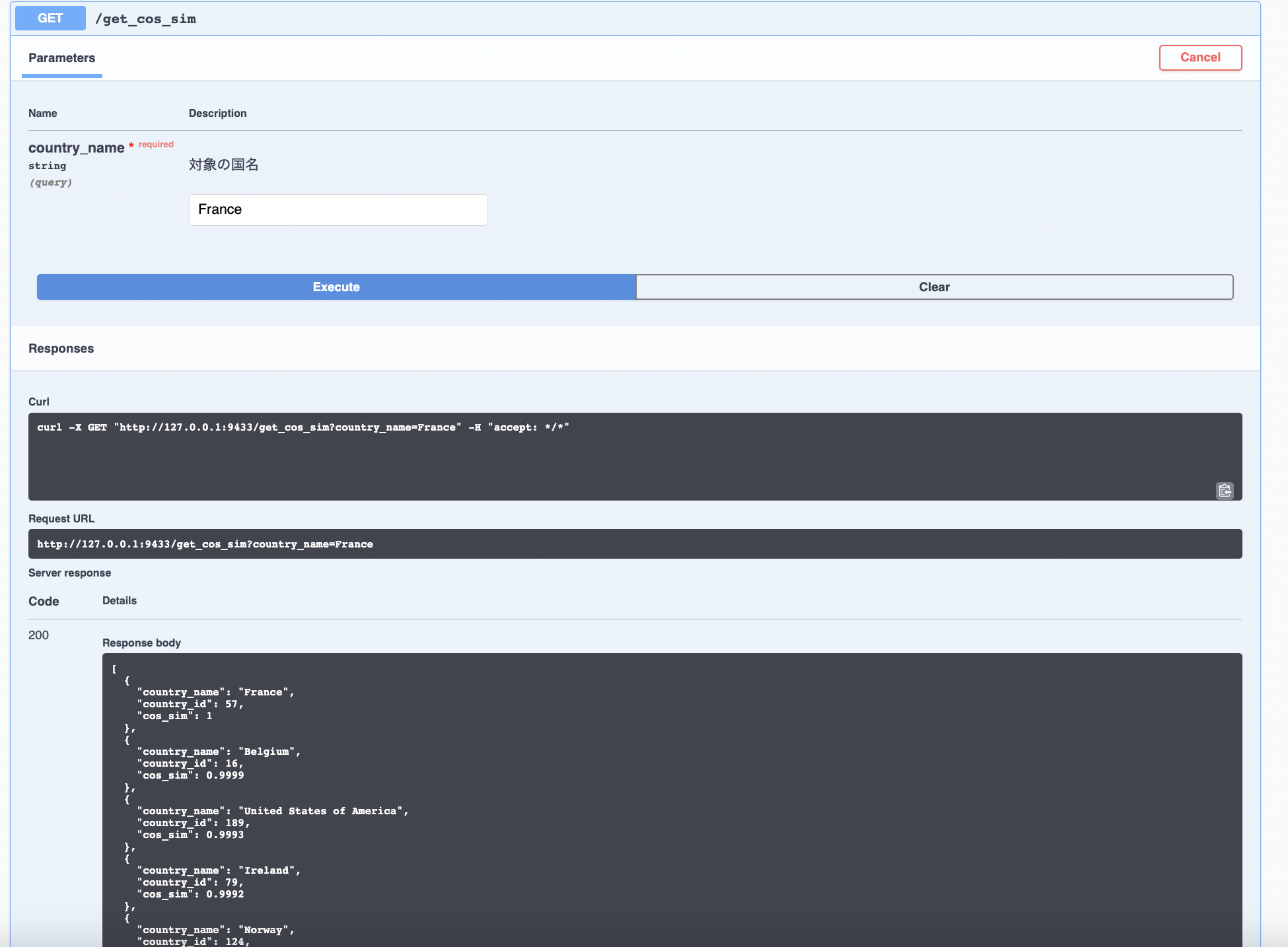
同じように、結論がJSON形式で返却された。また、Request URLに書いてあるURLを実際にブラウザに入れてみると
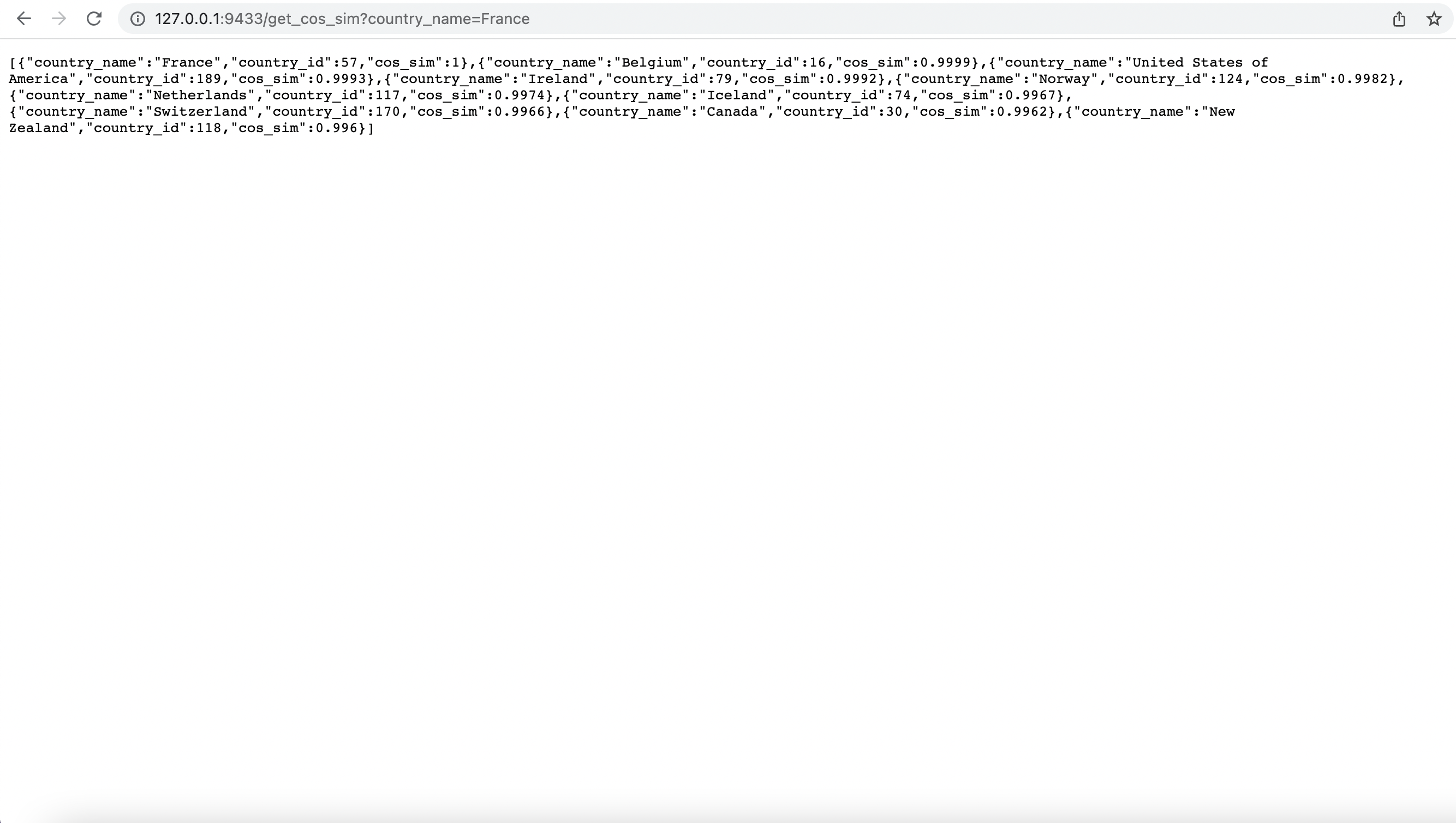
なので、クラウド環境でデプロイする際も、URLはもちろん異なるが、基本的にはこのように指定の形式のURLを送信すればAPIがデータを送ってくれる。受信したデータをRやPythonなどのプログラミング言語で加工すれば利用しやすくなる。
最後に、似たようなやり方でオーストリアとの民主主義の発展の類似度を可視化した世界地図をリクエストすると

このように指定された地図が返却される。プログラミング的には画像が返却されるのを確認できただけだが、政治学的には、オーストリアの民主主義の発展のパターンが西欧と北米など早い段階から民主化が進んできた国だけでなく、南米などの後になって民主主義は発展し始めた地域とも似ているのは興味深い。