クソアプリアドベントカレンダー2022 6日目です。
セキュリティインシデント怖いですよね。そんな昨今のセキュリティ事情を考慮に入れたドキュメントキャプチャアプリ「SecDocCap」を作成しました。
Androidアプリです。iPhoneユーザーの皆様すみません。デモだけでも見ていってください。
デモがこちらになります。
- ドキュメントを撮影します。
- 斜めから撮影したドキュメントを正面から見たように補正をかけます。
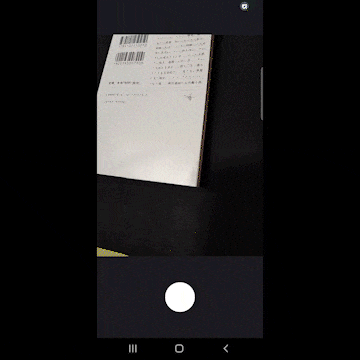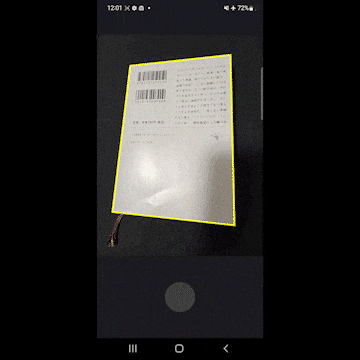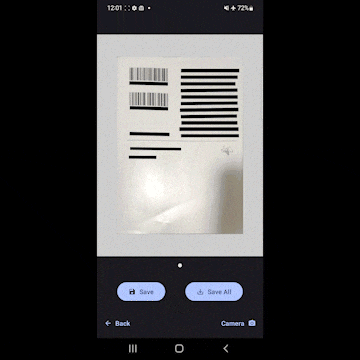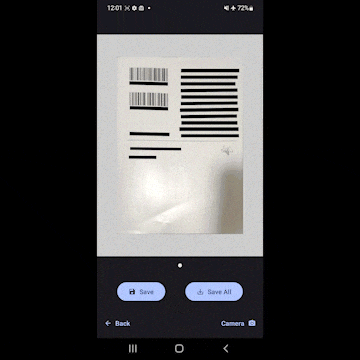
- 補正と同時にテキスト部分を全て黒で塗りつぶします。ドキュメントが全部読めなくなるので、セキュリティ的に安全というわけです。
- 塗りつぶした後の画像をギャラリーに保存することができます。
Androidユーザーの方は、こちらからダウンロードできます。
使っている技術
画像処理関連の技術は主にOpenCVのC++ APIをAndroid NDKを使って、利用しています。テキスト検出にはMLKitのテキスト認識モデルを使用しています。
全部端末上で処理されるので、そこの部分も一応セキュアです。
以下で処理内容についてもう少し詳しく説明します。
矩形検出
カメラのプレビュー画面ではリアルタイムで矩形検出を行なっています。AndroidのCamera2 APIを使って、YUV画像をカメラから連続で取得できるので、Yチャンネルのみの白黒画像を以下の関数に入力して、矩形領域を取得します。
処理内容としては、白黒画像の2値化、輪郭検出、閾値以下の閉領域のフィルター、四角形以外の輪郭のフィルター等が含まれています。
ここでは、OpenCVのAPIを使い倒しています。
std::vector<std::vector<cv::Point>> findContours(
int width,
int height,
uint8_t *pY,
int yPitch) {
cv::Mat gray(height, yPitch, CV_8UC1, pY);
cv::Mat grayCropped = gray(cv::Rect(0, 0, width, height));
cv::threshold(
grayCropped,
grayCropped,
0,
255,
CV_THRESH_BINARY | CV_THRESH_OTSU);
std::vector<std::vector<cv::Point>> contours;
std::vector<cv::Vec4i> hierarchy;
cv::findContours(
grayCropped,
contours,
hierarchy,
cv::RETR_EXTERNAL,
cv::CHAIN_APPROX_TC89_L1);
std::vector<std::vector<cv::Point>> rectangleContours;
double areaThreshold = width * height / 20.0;
for(auto& contour : contours) {
double a = cv::contourArea(contour, false);
if(a > areaThreshold) {
// approximate curve as line
std::vector<cv::Point> approx;
cv::approxPolyDP(
cv::Mat(contour),
approx,
0.01 * cv::arcLength(contour, true),
true);
// get only rectangles
if (approx.size() == 4) {
rectangleContours.emplace_back(approx);
}
}
}
return rectangleContours;
}
ホモグラフィー変換
矩形を検出した後、それを正面から見たように変換するのがホモグラフィー変換です。
src、dstとしてそれぞれ変換前、変換後の4点を指定してあげると、ホモグラフィー変換行列が得られて、それをホモグラフィー変換のAPIの引数として与えてやります。
void warpPerspective(
cv::Point2f *src,
cv::Point2f *dst,
int width,
int height,
uint8_t *input,
uint8_t *output) {
cv::Mat inputMat(height, width, CV_8UC4, input);
cv::Mat outputMat(height, width, CV_8UC4, output);
cv::Mat perspectiveMat = cv::getPerspectiveTransform(src, dst);
cv::warpPerspective(
inputMat,
outputMat,
perspectiveMat,
outputMat.size(),
cv::INTER_LINEAR);
}
テキスト検出
テキスト検出には、MLKitのテキスト認識モデルを使用しています。
使い方はとても簡単で、TextRecognizerを取得したら、BitmapからInputImageオブジェクトを作って、recognizer.process(inputImage)と渡してやるだけです。
あとは成功時、失敗時のコールバックを登録すると結果をコールバック関数に返してくれます。
実際の処理では、コールバック関数の中で、テキスト検出された矩形を黒く塗りつぶしています。
こちらはKotlinでの処理になります。
fun detect(
inputBitmap: Bitmap,
onSuccessCallback: (List<Text.TextBlock>) -> Unit
) {
val recognizer = TextRecognition.getClient(JapaneseTextRecognizerOptions.Builder().build())
val inputImage = InputImage.fromBitmap(inputBitmap, 0)
recognizer.process(inputImage)
.addOnSuccessListener { visionText ->
onSuccessCallback(visionText.textBlocks)
}
.addOnFailureListener { e ->
Log.e(TAG, "${e.message}")
}
}
課題
- 矩形検出の精度が悪いです。今の実装だと、濃い背景の上に白いドキュメントが載っている場合でないと検出できません。要改善です。
- ホモグラフィー変換後のアスペクト比がうまく調整されません。元ドキュメントのアスペクト比を類推するのが意外に難しく、後回しになってしまいました。
まとめ
まともに使えるドキュメントキャプチャを探している方は、Microsoft Lensの方が絶対におすすめです!
不真面目なドキュメントキャプチャを探している方は、暇があれば私のアプリをダウンロードしてみてください!
明日は@iotasさんよろしくお願いいたします!