先日新バージョンがリリースされたUnity ML-Agents v0.3を使っていろいろ遊んでみました。
ML-Agents v0.3 Beta released: Imitation Learning, feedback-driven features, and more
新機能の紹介や変更点などは前回の記事をご覧ください。

今回は上から降ってくる物体を避けるというゲームを作ってみました。シューティングゲームみたいなもんです。
新バージョンの注意点
まずは新しくなったUnity ML-Agentsの使い方などを少し紹介していきたいと思います。
Adademy, Brain, Agent という基本構造などは変わりませんが、APIに関していろいろ変更されています。
public class TemplateAgent : Agent {
public override void CollectObservations()
{
}
public override void AgentAction(float[] vectorAction, string textAction)
{
}
public override void AgentReset()
{
}
public override void AgentOnDone()
{
}
}
新バージョンではCollectObservations()に状態を書いていきます。
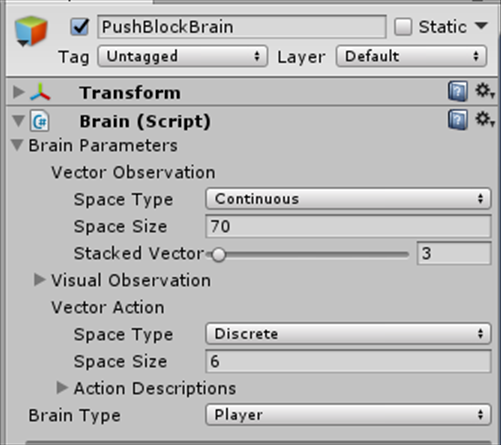
例えばサンプルにあるPushBlockを例にしてみます。

public override void CollectObservations()
{
float rayDistance = 12f;
float[] rayAngles = { 0f, 45f, 90f, 135f, 180f, 110f, 70f };
string[] detectableObjects;
detectableObjects = new string[] { "block", "goal", "wall" };
AddVectorObs(rayPer.Perceive(
rayDistance, rayAngles, detectableObjects, 0f, 0f));
AddVectorObs(rayPer.Perceive(
rayDistance, rayAngles, detectableObjects, 1.5f, 0f));
}
AddVectorObs()を使って状態を取得していきます。
また、あらたにRayPerceptionというスクリプトも追加され、これをAgentに張り付けて使います。

これはrayDistanceの距離,rayAnglesの方向に向けて、Physics.SphereCast()を使うことで、半径0.5の球体を飛ばして衝突判定を行いエージェントからオブジェクトまでの距離を取得しています。

PushBlockの場合であれば、高さ0fと1.5fから7方向ずつ、計14本のレーザーで物体を検出します。
RayPerceptionを使った場合の状態数の計算式は以下の通りです。
(rayAngles) * (detectableObjects+2) * (rayPer.Perceive())
PushBlockでは 7*(3+2)*2で状態数は70になります。
しかし、なぜdetectableObjectsに+2するのかは謎。RayPerceptionスクリプト内にその記述があります。
※コメント欄より
どうやら、detectableObjectsとしてTagを渡したオブジェクトに当たったかどうかの当たり判定、そのオブジェクトまでの距離、の2点を情報として追加しているため+2しているようです。
シューティングゲームを作る
シューティングゲーム自体の実装はたくさん記事があると思うのでここでは割愛させていただきます。
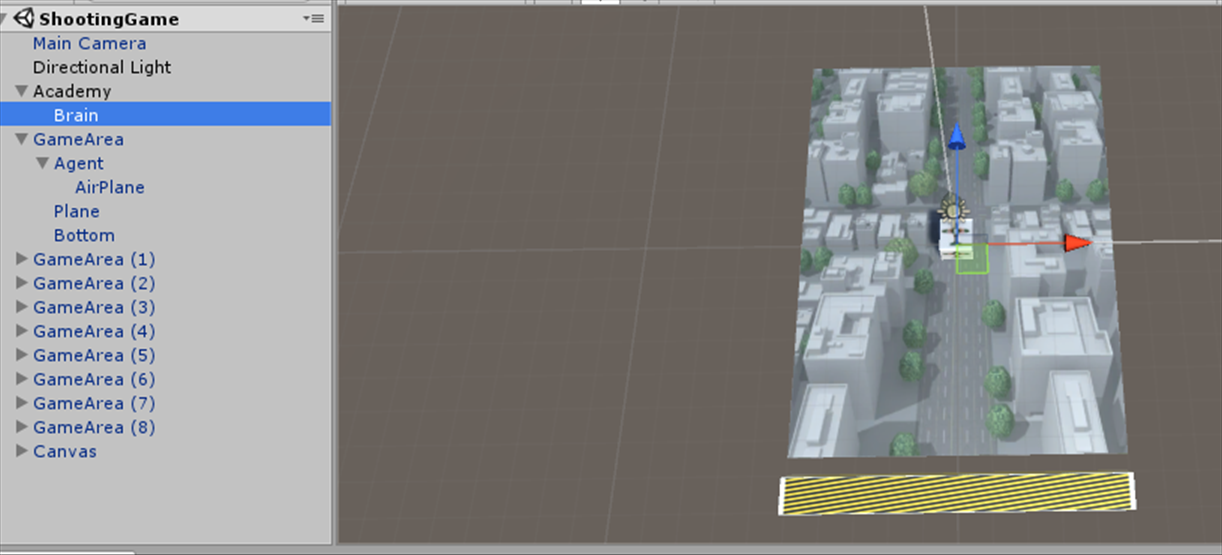
私は上の画像のような感じで作りました。
上からボールが降ってきてぶつかるとゲームオーバーです。

public override void CollectObservations()
{
float rayDistance = 10f;
float[] rayAngles = {0f,15f,30f,45f,60f,75f,
90f,105f,120f,135f,150f,165f,
180f,195f,210f,225f,240f,255f,
270f,285f,300f,315f,330f,345f};
string[] detectableObjects;
detectableObjects = new string[] { "Enemy" };
AddVectorObs(rayPer.Perceive(
rayDistance, rayAngles, detectableObjects, 0f, 0f));
}
状態はこんな感じで取得しています。状態数は72。
ちなみにdetectableObjectsはタグを利用します。ボールにEnemyというタグをつけています。
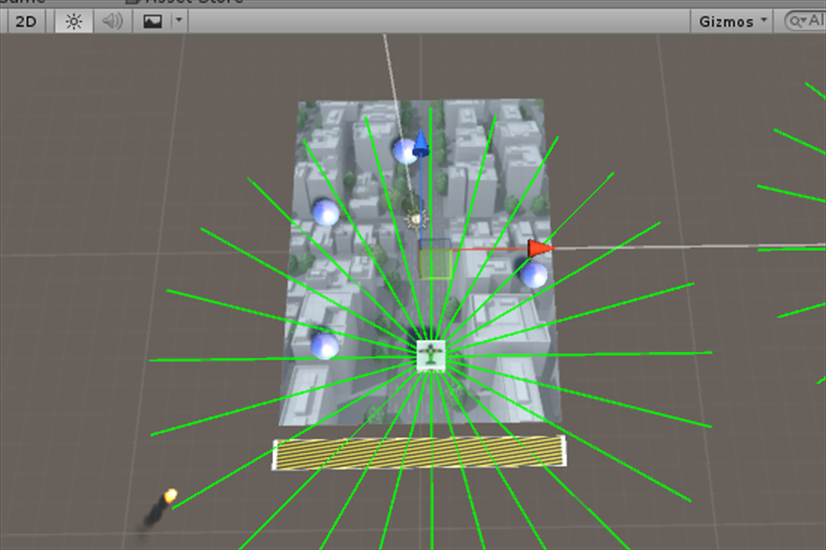
ゲームを実行して、右上にあるGizmosというボタンを押せば、レーザーがどのように照射されているか確認できます。
プレイヤーとボールが衝突したときは以下のような記述を書きました。
void OnTriggerEnter(Collider col)
{
if (AirPlane.activeSelf == true)
{
if (col.gameObject.tag == "Enemy")
{
Instantiate(explosion, transform.position, Quaternion.identity);
AddReward(-10f);
AirPlane.SetActive(false);
Done();
}
}
}
プレイヤーがボールに衝突したとき、プレイヤーのアクティブをオフにし、爆発エフェクトを発生させます。
また、AddReward()を使うことで報酬を追加します。ボールにぶつかったら-10。
Done()は旧バージョンでのdone=trueです。これでAgentReset()を呼び出します。
public override void AgentAction(float[] vectorAction, string textAction)
{
MoveAgent(vectorAction);
AddReward(0.01f);
}
ボールにぶつかっていない状態のときは、毎アクションごとに0.01の報酬を追加します。
MoveAgent()にはプレイヤーのアクションを書きましょう。ここは旧バージョンと変わりません。
私はこんな感じで書きました。
public float speed;
public void MoveAgent(float[] act)
{
int action = Mathf.FloorToInt(act[0]);
//アクション
if (action==1)
{
transform.Translate(0, 0, speed);
}
if (action==2)
{
transform.Translate(-speed, 0, 0);
}
if (action==3)
{
transform.Translate(0, 0, -speed);
}
if (action==4)
{
transform.Translate(speed, 0, 0);
}
//移動制限
if (transform.localPosition.x < -4.5f)
{
transform.localPosition =
new Vector3(-4.5f, 0.5f, transform.localPosition.z);
}
if (4.5f < transform.localPosition.x)
{
transform.localPosition =
new Vector3(4.5f, 0.5f, transform.localPosition.z);
}
if (transform.localPosition.z < -6f)
{
transform.localPosition =
new Vector3(transform.localPosition.x, 0.5f, -6f);
}
if (6f < transform.localPosition.z)
{
transform.localPosition =
new Vector3(transform.localPosition.x, 0.5f, 6f);
}
}
BrainTypeをPlayerにしてActionSizeを5、Elementにキーを割り当てます。
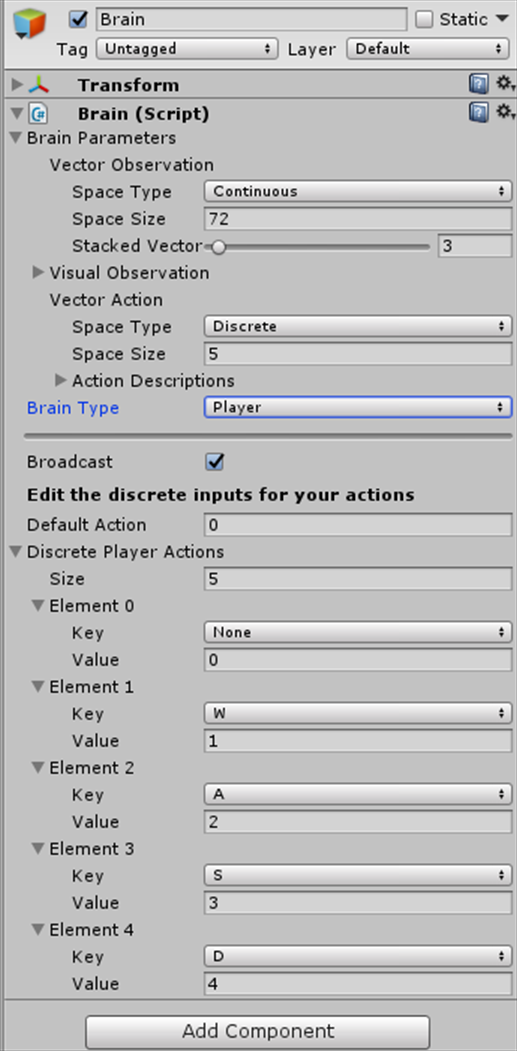
これでWASDでプレイヤーを操作できます。
あと、AcademyのTimeScaleの部分なんですが、ここで少しハマりました。
このタイムスケールは何倍の速度で強化学習をするのかを指定できます。数字を上げていけば10倍、100倍のスピードでゲームを進行させていくので単純に時間の節約になります。
ただ、FixdUpdate()のタイミングで時間を早めていますのでUpdate()に処理などを書いてタイムスケールを上げていくと挙動がおかしくなるので注意です。
タイムスケールが1なら問題ありませんが、もっと上げていく場合はUpdate()ではなくFixeUpdate()に処理を書きましょう。
あとはビルドして学習をしていきましょう。

ppo.pyはlearn.pyに変更され、ハイパーパラメータなどはtrainer_configファイルで指定するようになりました。
オプションなども少し変更されているので注意。
python learn.py ShootingGame --train --run-id=SG
結果
学習結果
5万回

5万回でもすでにそこそこ避けています。
35万回

35万回になるとほぼぶつかることはなくなりました。しかも、5万回のときに比べて、かなりギリギリ(小さい動き)でボールを避けているのがわかります。
バグ?
今回の実験ではAIは基本的に左下に陣取ってボールを避けています。しかし、なぜか一番右端のボールは見えていないのか避けることができません。100万回ぐらい学習させても、上の画像のようにほとんどは避けられるのですが、一番右端だけは避けられないのです。
何度か実験してみたところ、今回とは対照的に右下に陣取るときもありました。そのときもほとんどは避けられるのですが、今度は一番左端のボールが避けられなくなります。
Tensorflow内でどのように計算されているのか私にはわからないので原因は不明です。
ダウンロード
GitHubから今回作った環境をダウンロードできます。
My ML-Agents Game
5万回~35万回の学習済みデータも付属しています。