こんにちは。
今回は、SELECT文の書き方についての3回目となります。
前回は演算結果や編集加工値を項目に設定する機能が多くありましたが、今回はSQLの連結や内部でのサブクエリ宣言などを利用した少し複雑な内容にも触れます。
※実行環境がベーシスリリース7.53ですので、最新リリースの7.54については未確認です。
また、ABAP SQLでの検証となりますので、ABAP CDSのみで動作する機能についても記述及び
動作確認をしていません。その点のご留意をお願いいたします。
記事一覧
-
[7.5xの新しいSELECT文記述方法について(その1)] (https://qiita.com/Go_Ohta/items/3882caf9149619e8bdd7)
- これまでの記述方法との比較、FIELDS句、インライン定義
-
[7.5xの新しいSELECT文記述方法について(その2)]
(https://qiita.com/Go_Ohta/items/450fa2ed291ec9279b9d)- リテラル・固定値・演算値・文字列編集・条件分岐・型変換
-
[7.5xの新しいSELECT文記述方法について(その3)] ※当記事
- 日付系機能・グループ化・内部テーブルをデータソースとして使用・UNION/WITH・RIGHT JOIN/CROSS JOIN
・・・
内容
-
日付・タイムスタンプ機能
- 日付・タイムスタンプ機能一覧
-
グループ化
- GROUPING、GROUP BY GROUPING SETS
-
内部テーブルをデータソースとして使用
-
UNION
-
WITH
-
RIGHT JOIN/CROSS JOIN
-
まとめ
1.日付・時刻・タイムスタンプ・タイムゾーン機能
日付・時刻・タイムスタンプ系の機能が増えました。
暦日付としての使用に限定されます。稼働日(稼働日カレンダ)を考慮した日付演算やチェックはできないので注意が必要です。
機能一覧
分類の凡例
DT:日付、TM:時刻、TS:タイムスタンプ、TZ:タイムゾーン、TF:変換
※がついている機能は後述します
| 分類 | 機能名 | 説明 |
|---|---|---|
| DT | DATS_IS_VALID | 日付(YYYYMMDD)妥当値チェック。 妥当値なら1、妥当値でないかNullの場合は0を取得 |
| DT | DATS_DAYS_BETWEEN | 第2日付値から第1日付値を引いて求めた日数を取得 |
| DT | DATS_ADD_DAYS | 指定日付値に指定日数を加算した日付を取得 ※マイナス値を使用して減算も可能 |
| DT | DATS_ADD_MONTHS | 指定日付値に指定月数を加算した日付を取得 ※マイナス値を使用して減算も可能 |
| TM | TIMS_IS_VALID | 時刻値(HHMMSS)妥当性チェック。 妥当値なら1、妥当値でないかNullの場合は0を取得 |
| TS | TSTMP_IS_VALID | タイムスタンプ値(YYYYMMDDHHMMSS)妥当値チェック。 妥当値なら1、妥当値でないかNullの場合は0を取得 |
| TS | TSTMP_CURRENT_UTCTIMESTAMP | 現在のUTC基準のTIMESTAMP値を取得 |
| TS | TSTMP_SECONDS_BETWEEN ※ | タイムゾーン値2値の差となる秒数を取得 |
| TS | TSTMP_ADD_SECONDS ※ | タイムスタンプ値に秒数を加算した値を取得 |
| TZ | ABAP_SYSTEM_TIMEZONE ※ | 指定したクライアントのシステムタイムゾーンを取得 |
| TZ | ABAP_USER_TIMEZONE ※ | 指定したクライアントとユーザIDに設定されている タイムゾーンを取得 |
| TF | TSTMP_TO_DATS ※ | タイムスタンプ値を日付値に変換 |
| TF | TSTMP_TO_TIMS ※ | タイムスタンプ値を時刻値に変換 |
| TF | TSTMP_TO_DST ※ | 指定したクライアントとユーザIDに設定されている タイムゾーンにて、サマータイム適用時期であれば'X'、 そうでなければSPACEを設定 |
| TF | DATS_TIMS_TO_TSTMP ※ | 日付+時刻(YYYYMMDDHHMMSS)値をタイムスタンプ値に変換 |
SELECT SINGLE
FROM demo_expressions
FIELDS
dats_is_valid( @sy-datum ) as datvalid1,
dats_is_valid( cast( '20200832' as dats ) ) as datvalid2,
dats_days_between( @sy-datum, cast( '20201231' as dats ) ) as days_betw,
dats_add_days( cast( '20210301' as dats ) , -1 ) as days_add,
dats_add_months( cast( '20210228' as dats ) , 1 ) as months_add1,
dats_add_months( cast( '20210331' as dats ) , -1 ) as months_add2,
tims_is_valid( cast( '123456' as tims ) ) as timvalid1,
tims_is_valid( cast( '234567' as tims ) ) as timvalid2,
tstmp_is_valid( timestamp1 ) as tstmpvalid,
tstmp_current_utctimestamp( ) AS tstmp
INTO @DATA(result).
cl_demo_output=>display( result ).

リテラルパラメータ設定を行う機能について
上記の機能一覧にて機能名の末尾に「※」がついている機能については、「引き渡しパラメータ名 = 値 」と記述する方法が採用されています。また、エラー発生時に返す値が設定されています(ON_ERRORパラメータ)。詳細はDate Time ConversionのSAPHELP内サンプルコードを参照してください。
SELECT SINGLE
FROM demo_expressions
FIELDS
abap_system_timezone(
client = @sy-mandt,
on_error = @sql_abap_system_timezone=>set_to_null )
AS system_tz,
abap_user_timezone(
user = @sy-uname,
client = @sy-mandt,
on_error = @sql_abap_user_timezone=>set_to_null )
AS user_tz
INTO @DATA(result).
cl_demo_output=>display( result ).
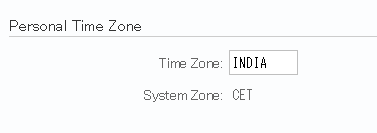
上記の結果は、ユーザIDに設定されているタイムゾーンは、ユーザプロファイルから確認できる下記ショットの内容と同一です。
SAPHELPへのリンク
SAPHELP Date Functions
SAPHELP Time Functions
SAPHELP Time Stamp Functions
SAPHELP Time Zone Functions
SAPHELP Date Time Conversion Functions
2.グループ化
GROUP BYで記述するデータ集約基準を複数記述することや、
対象項目が集約対象となっているかどうかを判定することが可能となりました。
GROUP BY GROUPING SETS( … ):GROUP BYの集約セットを複数記述できる。集約セットは「( 項目名1, 項目名2,…)」と記述して、それぞれカンマで区切る。
GROUPING( 項目名 ):指定した項目が集計対象となっていれば1、そうでなければ0を設定する
SELECT FROM mard AS t1
FIELDS
t1~matnr,
t1~werks,
t1~lgort,
SUM( labst ) AS sum_labst,
grouping( matnr ) AS grp_matnr, "集計の対象項目の場合1、そうでない場合0
grouping( werks ) AS grp_werks,
grouping( lgort ) AS grp_lgort
GROUP BY GROUPING SETS (
( matnr, werks, lgort ),
( matnr, werks ),
( matnr, lgort ),
( werks, lgort ),
( matnr ),
( werks ),
( lgort ) )
ORDER BY grp_matnr DESCENDING,
grp_werks DESCENDING,
grp_lgort DESCENDING
INTO TABLE @DATA(result).
cl_demo_output=>display( result ).
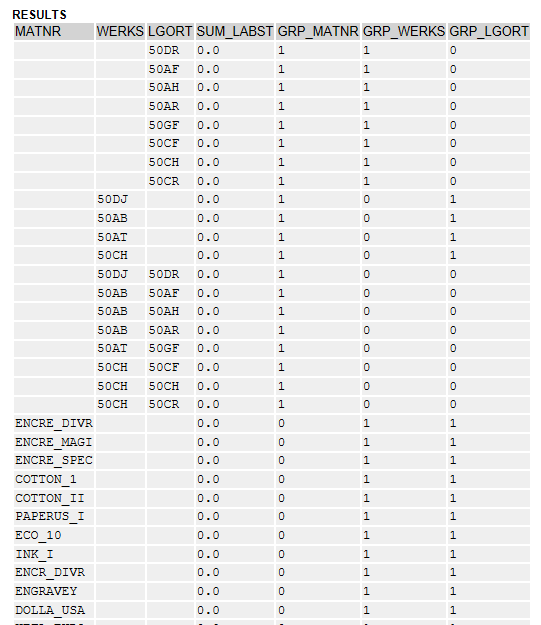
当方の実行環境で行った結果を一部だけ下記に記載します。
GROUPING( 項目名) の値が1のところは実際の項目にブランクが設定されており、集約されていることがわかるかと思います。
SAPHELPへのリンク
SAPHELP GROUPINGS
SAPHELP GROUP BY GROUPING SETS
3.内部テーブルをデータソースとして使用
1つのSELECT文において、内部テーブル1つのみですがデータソースとして扱うことができるようになりました。
内部テーブル名の先頭には@を付与して使用します。下記のサンプルコードは内部テーブルにDBをJOINしていますが、
DBに内部テーブルをJOINすることも可能です。
TYPES: BEGIN OF t_test,
werks TYPE vbap-werks,
lgort TYPE vbap-lgort,
END OF t_test,
tt_test TYPE TABLE OF t_test WITH KEY werks lgort.
data(tests) = value tt_test( ( werks = '0070' lgort = '0001' )
( werks = '9001' lgort = '9001' ) ).
SELECT FROM @tests AS t1 "先頭に@をつけて表す、テーブルエイリアス名の定義が可能
INNER JOIN vbap AS t2
ON t1~werks = t2~werks
AND t1~lgort = t2~lgort
FIELDS t2~vbeln,
t2~posnr,
t2~matnr,
t2~werks,
t2~lgort
ORDER BY vbeln, posnr
INTO TABLE @DATA(results).
cl_demo_output=>display( results ).
SAPHELPへのリンク
4.UNION
2つのSELECT文を連結し1つの内部テーブルに抽出結果を格納することができます。
SELECTは2つあっても、格納先を指示するINTO TABLE~は1つしかないことに注目してください。
※3つ以上のSELECT文を連結する場合も、UNIONでつなげて記述することが可能です(後述の、WITHのサンプルコードにて記載)。
DATA(datumuzeit) = sy-datum && sy-uzeit.
SELECT
FROM cdhdr AS t1
INNER JOIN cdpos AS t2
ON t1~objectclas = t2~objectclas
AND t1~objectid = t2~objectid
AND t1~changenr = t2~changenr
FIELDS
t1~objectclas,
t1~objectid,
t1~udate,
t1~utime,
t2~tabname,
t2~tabkey,
t2~fname
WHERE t1~objectclas = 'VERKBELEG' "販売伝票
AND concat( t1~udate, t1~utime ) >= '20200801000000'
AND concat( t1~udate, t1~utime ) <= @datumuzeit
UNION
SELECT
FROM cdhdr AS t3
INNER JOIN cdpos AS t4
ON t3~objectclas = t4~objectclas
AND t3~objectid = t4~objectid
AND t3~changenr = t4~changenr
FIELDS
t3~objectclas,
t3~objectid,
t3~udate,
t3~utime,
t4~tabname,
t4~tabkey,
t4~fname
WHERE t3~objectclas = 'EINKBELEG' "発注伝票
AND concat( t3~udate, t3~utime ) >= '20200701000000'
AND concat( t3~udate, t3~utime ) <= @datumuzeit
ORDER BY objectclas "指定しないと並び順が不定
INTO TABLE @DATA(result).
cl_demo_output=>display( result ).
注意点
- 取得結果数を制限する、UP TO n ROWSは使用できない
- 最初のSELECTの結果に続いて2つ目のSELECTの結果が追加されるわけではなく、並び順は不動になる(通常のSELECT文と同様)
- ORDER BYを指定する場合は、「テーブルエイリアス名~項目名」ではなく「項目名」で指定する
同一データのマージ有無設定(UNION DISTINCTとUNION ALL)
UNIONには、取得した結果が同一内容である場合のデータのマージ処理有無をオプションとして指定できます。
| パターン | 説明 |
|---|---|
| UNION DISTINCT | 結果の同一内容行をマージして1行のみとした状態でデータを取得する ※デフォルトなので記述不要 |
| UNION ALL | 結果の同一内容行をマージせず重複内容を含めたすべてのデータを取得する |
集計処理などでデータをマージされると困るような場合は「UNION ALL」を明記する必要があります。
SAPHELPに記載されているコードがシンプルでわかりやすいので、下記リンク先のサンプルコードを参照してください![]()
SAPHELPへのリンク
5.WITH
WITHを使用すると、Common Table Expression(CTE)を用いて、WITH内で使用できるサブクエリを定義できます。
定義したサブクエリはWITH内のSELECT文でデータソースとして使用することができます。
CTEは「+」を最初にした名称を設定し、AS( )内に抽出ロジックや抽出項目を記述します。
下記サンプルコードは、テーブルMARDのデータのうち、
品目単位で集計した結果を「+AGGRS_MATNR」、
プラント単位で集計した結果を「+aggrs_werks」としてそれぞれCTEで定義し、
それらの結果とMARDのそのままのデータをUNIONを使って1つにまとめて取得しています。
WITH
* +AGG_WERKS:プラント単位で利用可能在庫を集計
+aggs_werks AS (
SELECT FROM mard
FIELDS
matnr,
werks,
'ZZZZ' AS lgort,
SUM( labst ) AS labst
GROUP BY matnr, werks ), "次もCTEなのでカンマで区切る
* +AGG_MATNR:品目単位で利用可能在庫を集計
+aggs_matnr AS (
SELECT FROM mard
FIELDS
matnr,
'ZZZZ' AS werks,
'ZZZZ' AS lgort,
SUM( labst ) AS labst
GROUP BY matnr ) "次はCTEではないのでカンマで区切らない
* 上記CTEで定義したサブクエリを以降のSELECTで使用
SELECT FROM mard
FIELDS
CAST( '01:DATA' AS CHAR( 16 ) ) AS desc,
matnr,
werks,
lgort,
labst
UNION SELECT FROM +aggs_werks
FIELDS
'99_SUM_WERKS' AS desc,
matnr,
werks,
lgort,
labst
UNION SELECT FROM +aggs_matnr
FIELDS
'99_SUM_MATNR' AS desc,
matnr,
werks,
lgort,
labst
ORDER BY matnr, werks, lgort
INTO TABLE @DATA(result).
cl_demo_output=>display( result ).
注意点
CTEを複数記述する場合はカンマで区切る。実際のSELECT文の前のCTEにはカンマ区切りは不要。
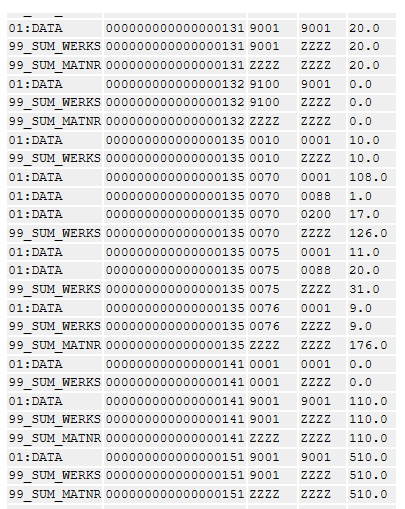
結果(の一部)
ENDWITH
ENDWITHは、WITH内のSELECTがループする場合(SELECT SINGLEやINTO TABLE等でない場合)に、ENDSELECTの代わりに
記述して、ループの切れ目を表現します。
先ほど書いたWITHは、INTO TABLEなのでループが発生しないのでENDWITHは書いていませんが、
下記のサンプルコードは結果がループするのでENDWITHが必要となります。
with
+test as ( select from mara
fields matnr
where right( matnr, 1 ) = '1' )
select from +test
fields
matnr
into @data(result). "SELECT文の場合、この後にENDSELECTが来る
cl_demo_output=>write( result ).
endwith. "ENDSELECTの代わりのように記述する
cl_demo_output=>display( ).
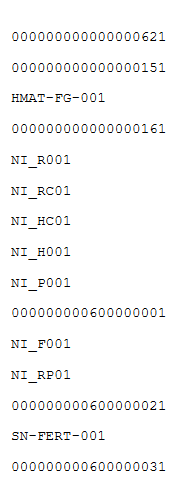
結果
SAPHELPへのリンク
6.RIGHT JOIN/CROSS JOIN
RIGHT JOIN
これまで外部結合(OUTER JOIN)は左辺外部結合(LEFT OUTER JOIN)のみが使用可能でしたが、
右辺外部結合(RIGHT OUTER JOIN)も使用できるようになりました。
下記は、プラントのコード値の先頭が1であるものに「FIRST1」を表示するサンプルコードです。
RIGHT JOINで記述した場合でも、テーブルをひっくり返してLEFT JOINで記述した場合でも同様の結果が得られることが分かります。
・・・となるとよほどの理由がない限りはLEFT JOINで書いた方が良いのでは・・・RIGHT JOINの有効活用方法をご存じの方がいらっしゃいましたら、コメントでご教示いただければ幸いです。
* RIGHT JOIN版
WITH +cte1 AS (
SELECT FROM t001w
FIELDS 'FIRST 1' AS msg,
werks WHERE left( werks,1 ) = '1' ) "先頭が1のみ
SELECT FROM +cte1 AS t1
RIGHT OUTER JOIN t001w AS t2 "T001wの対象エントリが基準
ON t1~werks = t2~werks
FIELDS t1~msg,
t2~werks
WHERE ( left( t2~werks, 1 ) = '0' OR "先頭が0or1
left( t2~werks, 1 ) = '1' )
ORDER BY t2~werks
INTO TABLE @DATA(result1).
cl_demo_output=>write( result1 ).
* 上記をLEFT JOINで書き直し
WITH +cte1 AS (
SELECT FROM t001w
FIELDS 'FIRST 1' AS msg,
werks WHERE left( werks,1 ) = '1' )
SELECT FROM t001w AS t1
LEFT OUTER JOIN +cte1 AS t2 "T001Wの対象エントリが基準
ON t1~werks = t2~werks
FIELDS t2~msg,
t1~werks
WHERE ( left( t1~werks, 1 ) = '0' OR
left( t1~werks, 1 ) = '1' )
ORDER BY t1~werks
INTO TABLE @DATA(result2).
cl_demo_output=>write( result2 ).
ASSERT result1 = result2.
cl_demo_output=>display( ).
CROSS JOIN
内部結合や外部結合とは異なり、結合条件不要で複数のテーブルエントリを組み合わせる結合方法です。
左側のデータセットと、右側のデータセットを掛け合わせる(クロスする)ようにデータを作成します。
3つの結合パターンのイメージ図を以下に示します。
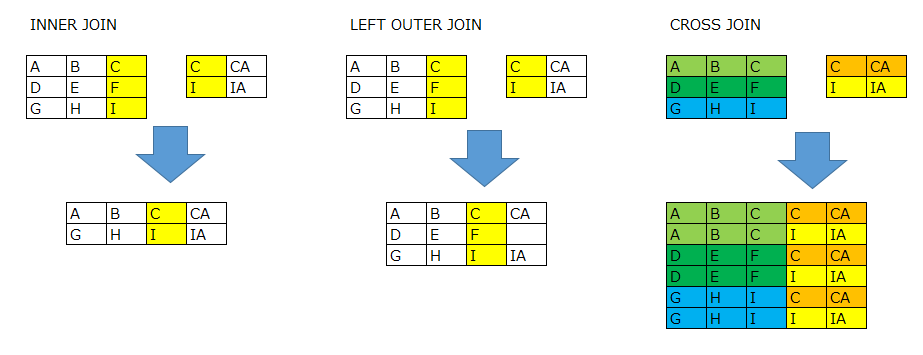
以下、サンプルコードですが、「条件を使用しない結合」って業務要件的なコードだとなかなか使用する事例が少ないかなと思います。
こちらにつきましても有効活用方法ご存じの方いらしゃいましたらコメントよろしくお願いします。
TYPES: typ_demo_exp TYPE demo_expressions.
DATA: itab TYPE TABLE OF typ_demo_exp.
TYPES: BEGIN OF typ_match,
1st TYPE char10,
2nd TYPE char10,
END OF typ_match.
DATA: itab2 TYPE TABLE OF typ_match WITH EMPTY KEY.
itab = VALUE #( ( id = '1' char1 = 'FIELD1' )
( id = '2' char1 = 'FIELD2' )
( id = '3' char1 = 'FIELD3' ) ).
DELETE FROM demo_expressions.
INSERT demo_expressions FROM TABLE itab.
itab2 = VALUE #( ( 1st = 10 2nd = 20 )
( 1st = 30 2nd = 40 )
( 1st = 50 2nd = 60 ) ).
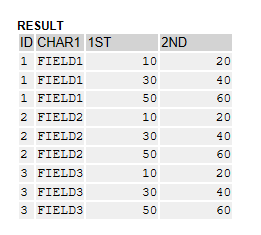
SELECT FROM demo_expressions AS t1
CROSS JOIN @itab2 AS t2
FIELDS t1~id, t1~char1, t2~1st, t2~2nd
INTO TABLE @DATA(result).
cl_demo_output=>display( result ).
SAPHELPへのリンク
7.まとめ
SQLの中でもSELECT文限定、しかも7.5xのアップデート内容の一部だけでこれほどのボリュームのある記事になりました。R/3時代は「OPEN SQLって、SQLの初歩的な機能しかないし、パフォーマンス観点から使えない命令も多いので正直チョロい」なんて言われていた時代もありましたが、今は簡単には全機能を覚えきれないほどの高機能になったなと思います(実は今回の記事にも載せていないものがチラホラあります)。
今回の内容は以上です、ありがとうございました。