やりたいこと
論文を追いたいが、英語 + 難しい + 多すぎる で辛い。
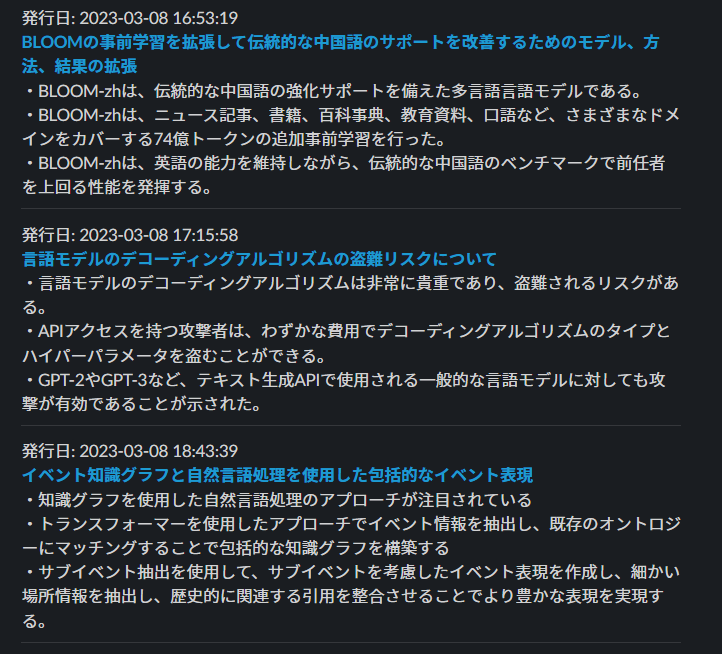
なら、ChatGPT に要約してもらって Slack 通知してもらえばええやん。
実装の流れ
- arxiv.org の API を1時間ごとに叩いて新着論文を確認する
- 新着があったら ChatGPT に要約してもらう
- Slack で通知
実装
AWS オンリーで実装。
Lambda で作って EventBridge で叩くだけ。
すでに Slack 通知済みのやつをもう一回投稿しないように、通知済みの論文の最後の日付を S3 に保存しておく。
RSS とか使えば S3 いらないかも。
レイヤー
レイヤーを作成。
pip install openai slack-sdk arxiv -t ./python
zip -r python ./python
Lambda
import json
import openai
import slack_sdk
from datetime import datetime
import arxiv
import boto3
import asyncio
# ChatGPT setting
# OpenAI API KEY
openai.api_key = 'OpenAI の API key'
# ChatGPT setting
system = """与えられた論文の要点を3点のみでまとめ、以下のフォーマットで日本語で出力してください。```
タイトルの日本語訳
・要点1
・要点2
・要点3
```"""
async def summarize(paper_data):
text = f"title: {paper_data.title}\nbody: {paper_data.summary}"
loop = asyncio.get_event_loop()
response = await loop.run_in_executor(
None, lambda: openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{'role': 'system', 'content': system},
{'role': 'user', 'content': text}
],
temperature=0.25,
)
)
summary = response['choices'][0]['message']['content']
title, *body = summary.split('\n')
body = '\n'.join(body)
date_str = paper_data.published.strftime("%Y-%m-%d %H:%M:%S")
message = f"発行日: {date_str}\n*<{paper_data.entry_id}|{title}>*\n{body}\n"
return message
# Slack setting
# Slack bot token
slack_token = "Slack の token"
client = slack_sdk.WebClient(token=slack_token)
def send_slack(message, channel_id):
client.chat_postMessage(
channel=channel_id,
blocks=[
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": message,
}
},
{
"type": "divider"
}
],
unfurl_links=False
)
# Slackへすでに投稿済みの論文の中で最新のものの日付を保存するためのS3バケット
bucket = 'paper-log'
# 日付を取得する(保存されていない場合はNoneを返す)
def get_last_paper_date(file_path):
s3 = boto3.Session(region_name=None).resource('s3')
obj = s3.Object(bucket, file_path)
try:
json_txt = obj.get()['Body'].read()
except:
return None
item_dict = json.loads(json_txt)
str_date = item_dict['before_latest_date']
return datetime.strptime(str_date, "%Y-%m-%dT%H:%M:%S.%f%z")
# 日付を保存する
def save_last_paper_date(file_path, latest_date):
date_str = latest_date.strftime("%Y-%m-%dT%H:%M:%S.%f%z")
test_json = {'before_latest_date': date_str}
s3 = boto3.Session(region_name=None).resource('s3')
obj = s3.Object(buscket, file_path)
obj.put(Body=json.dumps(test_json, ensure_ascii=False))
async def main(query: str, file_path: str, slack_channel_id: str):
# 論文の検索
result = arxiv.Search(
query=query,
max_results=200,
sort_by=arxiv.SortCriterion.SubmittedDate,
sort_order=arxiv.SortOrder.Descending,
).results()
# 空なら終了
result = list(result)
if len(result) == 0:
return
# すでに投稿済みの論文の中で最新のものの日付を取得
before_date = get_last_paper_date(file_path)
# 取得した論文の中で最新のものの日付を保存
save_last_paper_date(file_path, result[0].published)
# 未投稿の論文のみを抽出
if before_date is not None:
new_results = [data for data in result if data.published.timestamp(
) > before_date.timestamp()]
result = new_results
# 要約
summarize_tasks = []
for paper_data in result:
summarize_tasks.append(summarize(paper_data))
summarize_results = await asyncio.gather(*summarize_tasks)
# Slackへ投稿
for result in reversed(summarize_results):
send_slack(result, slack_channel_id)
async def async_handler():
await main('cat:"cs.CV"', "cs.json", "SlackチャンネルのID")
def lambda_handler(event, context):
asyncio.get_event_loop().run_until_complete(async_handler())
main の第一引数は arXiv の検索クエリ。基本はカテゴリ検索だろうからカテゴリ一覧参照。
cat:"cs.CL" で cs.CL、つまりComputation and Language だけ検索可能となる。
その他の細かいクエリ仕様はこちら参照。
あとは EventBridge で 1時間ごとに起動すれば OK。あと S3 のバケットとアクセス権限が必要なので追加しておくこと。
また、結構時間かかるので Lambda はタイムアウトを長めにしておく。
完成
最高!ChatGPT便利!
備考
- API が参照しているデータは特定の時間(日本時間で12~13時くらい?)にしか更新されないように見える。なのでそのタイミングでめちゃめちゃ論文が来る。
- 本当にその時間だけなら API アクセスタイミングはそこだけでよい
- 今は最大200件しかとってないので、それ以上論文が出てたら取り逃す
- エラーハンドリングおよび EventBridge の再実行の停止をしておいた方がいい。そうしないとエラー時に再実行が繰り返されめちゃくちゃ API を使っちゃう。