pythonにはnumpyという、数値計算と多次元配列を提供するライブラリがあります。
こいつがあったからこそpythonはデータサイエンスの中心的言語になったと言っても過言でないほどよくできており、numpy前提のライブラリも非常に多く存在しています。
僕はC#が好きなのでこういうライブラリがあったらなーと思うんですが、あまりめぼしいものがありません。
多分ほっといてそれらしいものが落ちてくることもないだろうし、それならいっそ勉強半分で作ってみようではないか、と思いたち、開発してみました。そして挫折しました。
GitHubのリポジトリはあるのですが、READMEだけだと書きたいことを書ききれないので、使い方、開発中どんな事を考えていたのか、といったことを備忘録の意味も込めてここにまとめます。
件のライブラリはこちら
NeodymiumDotNet - GitHub
設計思想
目指したもの
(ユーザーにとっての)書きやすさ、見やすさ
ライブラリがどのレイヤーで利用されるかにもよりますが、ユーザーフレンドリーなAPIは何にも増して重要な性能だと思います。使ってて苦痛なライブラリはどんなにパフォーマンスが良かろうと受けが良くないのではないかと思います。ここは譲れないスペックとして先頭に据え置きました。
言語の機能・文化との親和性
前項にも関連しますが、プログラミング言語のコミュニティが培ってきた文化に逆らったAPIは大抵まともに見れるものにはなりません。開発のきっかけであるnumpyは本当に素晴らしいライブラリですが、pythonの文化に合わせて作られたnumpyをC#にそのまま持ってくるのは文化的にも(何より僕のスキル的にも)無理があります。
結局、numpyは参考程度にとどめ、フルスクラッチで開発することにしました。
チューニング可能性
プログラムの実行環境は様々です。特にJITで実行されるC#は生成されたバイナリが多種多様なマシンで実行される可能性があります。そこで、ユーザーが自身の環境・目的に合わせてチューニングできる余地を残そうと考えました。
落とし穴を少なく
プログラミングには落とし穴がつきものです。サンプル通りに書いたつもりでも些細なミスで動かなかったりやたら重かったり、何時間も悩む羽目になることもしばしばでしょう。本ライブラリではそのような落とし穴が可能な限り少なくなるよう作りたいと考えました。
目指さなかったもの
パフォーマンスの極限
自分の実力では無理なので。とりあえず極端に遅くなければ良しとします。
とはいえ、性能評価はきっちりやっておきます。
簡潔さ
言語によっては表現の短さは非常に重要です。略語を導入したり、演算子を無理やりオーバーロードしたり、あの手この手の短縮手段が存在します。
しかしながらC#はIDEによるコーディング支援でガリガリ書いていく言語なので、多分そんなに短くしなくても問題ないでしょう・・・読みやすくなってれば。
シェイプのブロードキャスティング
正直言ってこれバグの温床では?という思いが拭えないので。
LL向けの機能としてはなかなかありがたいんですけどね。
LINQ to NdArrayにより、スカラ値の加減乗除算にブロードキャスティングの必要がなくなったというのも大きいです。
実装中に諦めたもの
遅延評価機構
LINQ to NdArrayですが、実は即時評価になっています。設計当初はto Objectと同様遅延評価になっていたのですが、パフォーマンス面で壁にぶつかったときに遅延評価だと詰んでしまうと判断し即時評価に作り直しました。まあ、キャッシュ取るせいでメモリの節約効果はまったくなかったのでその点では特に問題ないですが。イミュータブルなら即時でも遅延でも結果が変わらないですし多分許されるでしょう。
基本設計はそのままなので遅延評価用の機構はそのまま残っている状態ですが、手を加えようとするとかなりの大改造なので据え置きにしています。
契約プログラミング
行列演算ではシェイプが合ってないと計算できないケースが非常に多いので、契約プログラミングによる静的検証が適用されていれば非常に効果的にコーディングできると思われます。
そんな訳で、本当はちゃんと導入したかったんですけどね・・・。当初はCode Contractsを全体に仕込もうとしたんですが、やはりお亡くなりプロジェクトということで諦め。
csharplangにはMethod Contractなるプロポーザルも上がっているんですが、全然音沙汰ない様子。
nullable reference type入ったから優先度落ちてるのかな・・・。
筋の良いメモリ管理
行列演算では大量のメモリ領域を確保しては破棄するといったことが起こりえます。
場合によっては演算途中の一時変数として即使い捨てられるということもありえるでしょう。
.Netでは、ある程度大きなオブジェクトはLOH送りとなりGCによる回収が大幅に遅延するという仕様があります。
これは、大きなオブジェクトは寿命も長い傾向にあるという事実に基づいた設計ですが、行列演算とは相性がよくありません。
そこで登場するのが配列プールなのですが、これは借りた配列を明示的に返却しなければなりません。
かといって確保するNdArray<T>すべてをIDisposableにしていくというのはあまりに使い勝手が悪くなってしまいます。
そして、最終的に以下のような実装に落ち着きました。
public static (T[] array, ArrayCollector<T> collector) Alloc<T>(int minLength)
{
// ~~~
var array = ArrayPool<T>.Shared.Rent(minLength);
return (array, new ArrayCollector<T>(array));
}
// ~~~
internal class ArrayCollector<T>
{
private readonly T[] _array;
public ArrayCollector(T[] array)
=> _array = array;
~ArrayCollector()
{
ArrayPool<T>.Shared.Return(_array);
}
}
はい、デストラクタです。
いまどきのC#でDisposeパターンでさえないデストラクタを使うことになるとは想像もしてなかったのですが、使い勝手まで考えるとこれが妥協点でした。
基本的な使い方
NeodymiumDotNetで最も基本的な型はNdArray<T>です。
その名の通り型Tのジェネリックな多次元配列になっており、NdArray.Createメソッドで作ることが出来ます。
要素のアクセスは普通にインデックスを使ったり、平坦化インデックスを使ったり。スライスにも対応します。
// 一次元のT型配列+シェイプを表すint型配列から作ります
var ndarray1 = NdArray.Create(new double[24], new int[]{2, 3, 4});
// 多次元配列を直接渡しても作れます
var ndarray2 = NdArray.Create(new double[2, 3, 4]);
var element1 = ndarray1[1, 2, 3];
var element2 = ndarray1.GetByFlattenIndex(23);
// これ作ったときにはスライス構文はまだプロポーザルの段階だったので独自実装で無理やり。C# 8.0にはそのうちちゃんと対応したい・・・
var sliced = ndarray1[new Index(1), Range.Whole, new Range(0, 4, 2)];
不変性の保証で性能向上の余地を取り1、また値変更に起因するバグのリスクを減らしたりするために、NdArray<T>はイミュータブルです。
要素を直接編集するならミュータブル版のMutableNdArray<T>に変換してやる必要があります。
var mndarray1 = NdArray.CreateMutable(new double[2, 3, 4]);
var mndarray2 = ndarray1.ToMutable();
// ToImmutableはコピーによる生成。
var ndarray3 = mndarray1.ToImmutable();
// MoveToImmutableはムーブによる生成。効率がいい代わりにもとのMutableNdArray<T>を破壊します。
var ndarray4 = mndarray2.MoveToImmutable();
NdArray<T>はIEnumerable<T>を実装していません。意図せずLINQ to Objectに繋がって型が落ちたりパフォーマンスが落ちたりといったことを防ぐためです。LINQ to Objectにつなぎたいときは明示的にAsEnumerable()を呼んで変換する必要があります。
かわりに、NdArray<T>専用のLINQであるLINQ to NdArrayを用意したので大抵はそれで事足りると思います。
LINQ to NdArrayは演算子適用の役割を含んでいます。
numpyの場合、次のように多次元配列同士に演算子を適用することで要素ごとに演算した結果を得ることが出来ます。
A = someNdArrayA()
B = someNdArrayB()
result = A + B
しかしながら、静的型付け言語であるC#において総称性と演算子適用をどう両立するか非常に悩みました。
その結果、次のようにLinqのZipを用いるAPIを採用することにしました。
var A = SomeNdArrayA();
var B = SomeNdArrayB();
// LinqのZipメソッドの適用
var result1 = A.Zip(B, (a, b) => a + b);
// これも上の式と全く同じ演算
var result2 = (A, B).Zip((a, b) => a + b);
これにより要素間の演算は厳密な型検査が入るようになり、また組み込み演算子のみならず任意のメソッドを流し込めるようになりました。特に下の書き方は対称性が良いため結構気に入っています。
何よりこれを導入した結果、numpyのように膨大な数学関数APIを用意する必要がなくなり非常に楽になりました。
また、Linq演算子には反復手法を切り替えられるようなAPIも用意しています。
// System.Threading.Tasks.Parallel.Forによる並列化
var result = (ndarray1, ndarray2).Zip((x, y) => x + y, ParallelIterationStrategy.Instance);
ただここら辺はSIMDに対応できないのでParallel.ForかAlea GPUくらいしか適用先がないんですよね・・・。
もっとうまい方法を模索したいところです。
集計関数や行列関数もある程度用意しました。
特に行列演算の方は、愚直な実装なのでクッソ遅いままですが・・・。
var A = SomeNdArrayA();
var B = SomeNdArrayB();
var sum = A.Sum();
var mean = A.Mean();
var max = A.Max();
var det = A.Determinant();
var dot = A.Dot(B);
これらの演算は、必要な演算子がTに用意されていれば型によらず適用可能です。最速のジェネリック特殊化を目指してで検証した結果2とリフレクションによる演算子オーバーロードの探索を駆使したトレイトが裏に仕込んであります。
その他には乱数生成器があったり、.npyシリアライザがあったりしますが、ひとまずはここまで。
ベンチマーク
多次元配列ライブラリである以上、あまりに遅いと使い物になりません。
そんな訳で、ここまで作ってベンチマークを取ってみました。
比較用にnumpyも計測。
謎のベンチマークフレームワークを使っていますが、BenchmarkDotNetに似せた自作のなにかなので、あくまで参考値程度に見てください。
ただの加算
$n$x$n$のdouble配列を加算。
-
Add*: $n$x$n$のNdArray<double>の単純な加算。 -
AddParallel*: イテレーションにParallel.Forを採用した加算。 -
Add*NegativeControl: 比較用として、NdArray<double>ではなく同サイズのdouble[]の加算。 - numpyの
add*: 比較用として、numpyでの同じ加算。
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362
Intel Core i7-6700K CPU 4.00GHz (Skylake), 1 CPU, 8 logical and 4 physical cores
.NET Core SDK=3.0.100
[Host] : .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64bit RyuJIT
DefaultJob : .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64bit RyuJIT
| Method | Mean | Error | StdDev |
|---------------------- |---------------:|--------------:|--------------:|
| Add1 | 55.078 ns | 0.2411 ns | 0.2255 ns |
| Add2 | 63.239 ns | 0.9937 ns | 0.9295 ns |
| Add5 | 121.717 ns | 1.3872 ns | 1.2297 ns |
| Add10 | 290.949 ns | 0.8916 ns | 0.6961 ns |
| Add20 | 996.042 ns | 6.2021 ns | 5.1791 ns |
| Add50 | 5,851.582 ns | 85.2103 ns | 75.5367 ns |
| Add100 | 24,440.219 ns | 482.1122 ns | 450.9680 ns |
| Add200 | 160,390.700 ns | 1,710.3412 ns | 1,599.8542 ns |
| AddParallel1 | 1,537.889 ns | 8.2465 ns | 7.3103 ns |
| AddParallel2 | 1,657.140 ns | 21.6251 ns | 19.1701 ns |
| AddParallel5 | 2,584.595 ns | 13.3847 ns | 11.1768 ns |
| AddParallel10 | 3,528.856 ns | 14.7608 ns | 13.8072 ns |
| AddParallel20 | 5,725.524 ns | 18.5874 ns | 16.4773 ns |
| AddParallel50 | 11,128.889 ns | 34.6393 ns | 30.7069 ns |
| AddParallel100 | 25,411.936 ns | 53.7914 ns | 50.3165 ns |
| AddParallel200 | 90,820.789 ns | 1,800.8980 ns | 3,953.0148 ns |
| AddNegativeControl1 | 3.891 ns | 0.0263 ns | 0.0246 ns |
| AddNegativeControl2 | 7.591 ns | 0.0827 ns | 0.0691 ns |
| AddNegativeControl5 | 34.720 ns | 0.1450 ns | 0.1357 ns |
| AddNegativeControl10 | 135.969 ns | 1.0374 ns | 0.8662 ns |
| AddNegativeControl20 | 511.970 ns | 3.9569 ns | 3.5077 ns |
| AddNegativeControl50 | 2,955.916 ns | 12.4024 ns | 11.6013 ns |
| AddNegativeControl100 | 12,251.763 ns | 66.1508 ns | 58.6410 ns |
| AddNegativeControl200 | 65,790.409 ns | 731.2961 ns | 684.0548 ns |
testutils, OS=Windows-10-10.0.18362-SP0
Intel64 Family 6 Model 94 Stepping 3, GenuineIntel
python 3.7.4
numpy 1.16.3
method call overhead estimated: 0.12171221897006035us
method: add1 mean: 729.6 ns serr: 294.3 ns sdev: 4.71 us outlier samples: 0
method: add2 mean: 122.1 ns serr: 121.8 ns sdev: 1.949 us outlier samples: 0
method: add5 mean: 365 ns serr: 209.5 ns sdev: 3.352 us outlier samples: 0
method: add10 mean: 602.1 ns serr: 266.7 ns sdev: 4.267 us outlier samples: 0
method: add20 mean: 847.1 ns serr: 315.8 ns sdev: 5.052 us outlier samples: 0
method: add50 mean: 2.195 us serr: 511.3 ns sdev: 8.181 us outlier samples: 0
method: add100 mean: 4.747 us serr: 707.1 ns sdev: 11.31 us outlier samples: 0
method: add200 mean: 20.7 us serr: 914.9 ns sdev: 14.64 us outlier samples: 0
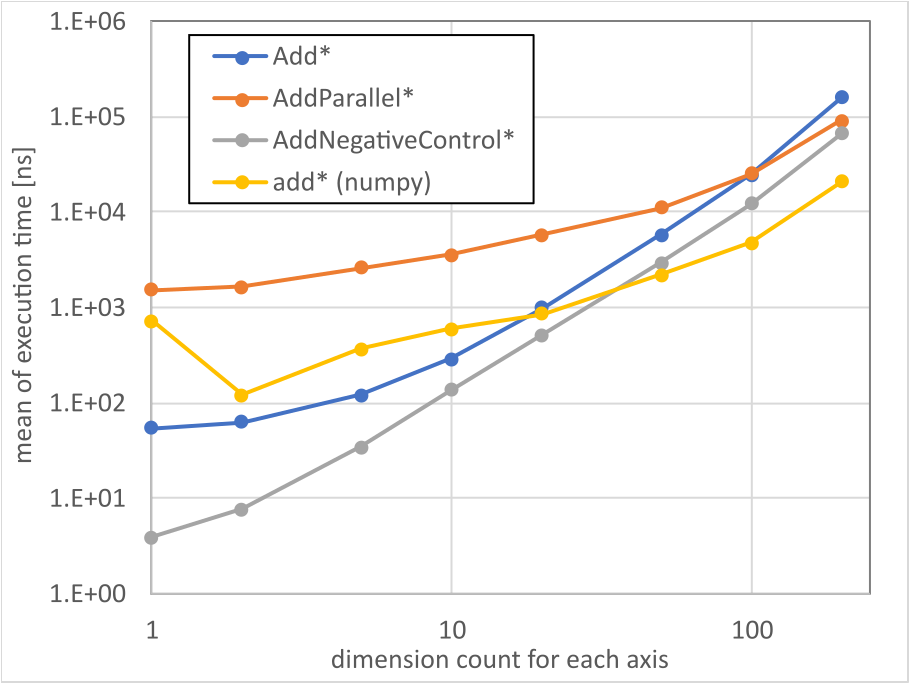
ネイティブ配列に対するオーバーヘッドは2~倍程度。
演算子をデリゲートに押し込んでforで回すのは流石にオーバーヘッドが大きいのか。
次元数が小さいうちはパラレルのメリットは小さい模様。
総要素数10000くらいが並列化の目安かなぁ・・・。
そしてこの時点ですでにnumpyが速い。
中身BLASなんだろうけど、やはりSIMD並列化あたりが入っているのか。
行列式
100x100の行列式も評価。
| Method | Mean | Error | StdDev |
|------------ |---------:|----------:|----------:|
| Determinant | 36.26 ms | 0.0638 ms | 0.0597 ms |
method: det mean: 1.91 ms serr: 5.065 us sdev: 81.04 us outlier samples: 0
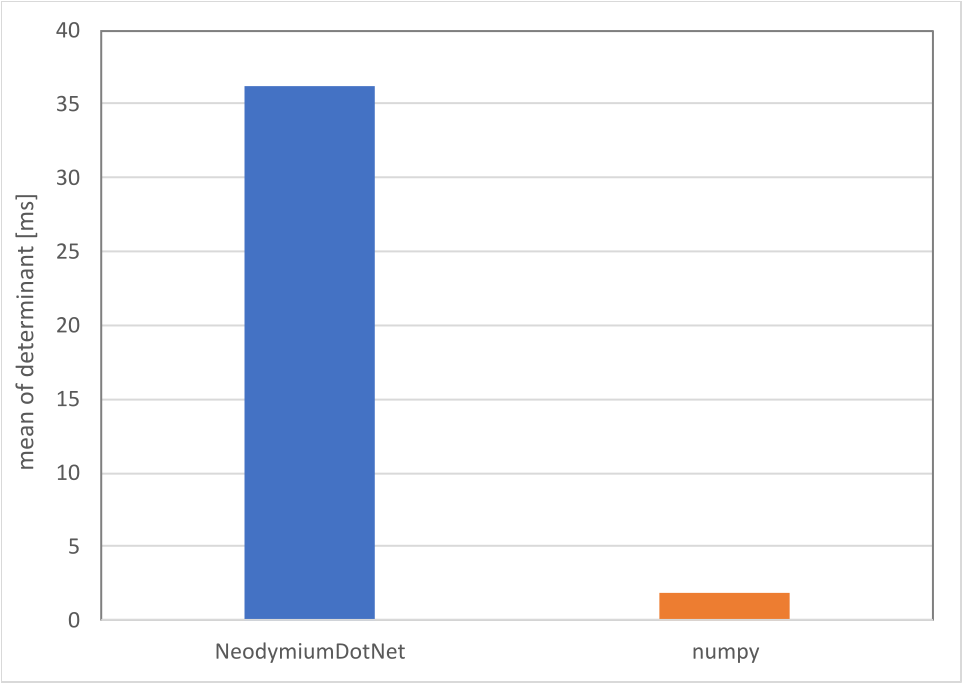
もう少し高度な行列演算では圧倒的に遅い。
実数についてはやっぱBLAS/LAPACKで差し替えたほうがいいのかなぁ・・・。
バックエンドの対応が不完全であろう四元数などが相手ならもう少し戦えるような予感はする。
結論
シグニチャの設計はそこそこがんばれたので一応は決着をつけられたという感じ。
やっぱりパフォーマンス上げるは僕の腕ではこれが限界でした。
自分ひとりだとこれ以上どうにかなるとも思えないので、提案・指摘・改善策等いただけたら幸いです。