前置き
この記事は講義課題に論文要旨を書く課題の写しです。半ばやっつけ仕事にやっているためかなり無理やりでおかしい箇所があるかもしれませんが、ご了承ください。
想定される読者
工学系の大学1年生ほど。(理工系としての素養は持っているが、専門分野としての知識は乏しい)
論文情報
タイトル: "World Models" ~ Recurrent World Models Facilitate Policy Evolution ~
著者: David Ha, Ju ̈rgenSchmidhuber
インタラクティブペーパー: https://worldmodels.github.io
論文PDF: https://arxiv.org/abs/1803.10122
NeurIPS 2018 32th Annual Conference
現論文を読むことを強く推奨します。
要旨
領域
この論文の研究分野は機械学習の領域内の、モデルベース深層強化学習にあたる。
強化学習とは、エージェントが動的環境と与えられる報酬を最大化することを目的とし、繰り返し試行錯誤のやりとりを重ねることによってタスクを実行できるようになる手法だ。モデルベース深層強化学習とは、すでに環境のモデルが既知でありエージェントが複数層の構造である深層学習モデルである場合を言う。

背景
近年深層学習が飛躍的に発展し、その恩恵は強化学習の領域も受けている。
特に数百万パラメータを持つRNNといった時系列モデルは、強化学習のエージェントに大きな可能性をもたらすと考えられる。しかしその恩恵は、信用割当問題(強化学習においてどの行動が報酬を増減させたか不明確である問題)によってあまり受ける事ができていない。それはこの問題を回避するために、計算量が少なくより試行回数を増やすことのできる小規模なモデルを使っているからである。
深層強化学習も数百万パラメータという大きなエージェントモデルを扱えるようにする事が課題である。
この課題を解決する一つの方法として、エージェントを環境のダイナミクスモデルを学習する大きなモデルと、動作を学習する小さなモデルに分割する方法がある。
環境ダイナミクスモデルを学習するという発想は人間の振る舞いから得られた。例えば人間は目にも止まらぬ速さのボールをバットで打つ事ができる。それは投げられたボールがいつどこに到達するかを無意識的に予測し、行動する事ができるからだと考えられる。
この先行研究として、PILCO というガウシアンプロセス(GP)を使って環境ダイナミクスモデルを学習するもの がある。しかし、これは環境から得られる観測が低次元の場合は良い性能を発揮するが、画像といった複雑かつ高次元の情報を扱うことは難しい。またベイジアンニューラルネットワークでGPを置き換えてみると、比較的低次元の観測かつ環境モデルがよく定義されている時に、将来性のある性能を見せた。
主張
この論文ではエージェントモデルを、環境から観測した情報を圧縮するV モデル、環境の状態遷移を予測す る RNN ベースの M モデル、実際の動作を生成する C モデルに分割し、数百万パラメータを持つ大きな RNN ベースのエージェントを提案する。このエージェントは画像情報のみを観測し、近似された環境ダイナミクス モデル(M モデル)の中だけで VizDoom といった今まで解けていないタスクを解き、SOTA(過去最高性能)を達成した。
モデルを分割する意味
上記にある通り、この論文ではエージェントモデルを V モデル、M モデル、C モデルに分割して提案して いる。

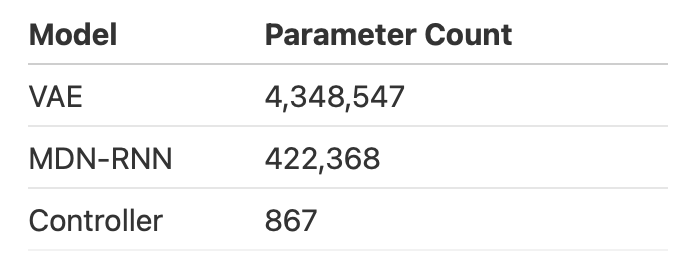
- V モデル: 入力画像を圧縮し、状態を表現する小さなデータにする。(数百万パラメータ)
- M モデル: V モデルから得られるデータと過去から引き継ぐ隠れ表現データをもとに、次の観測(環境の状態)や報酬を確率的に予測する。(数十万パラメータ)
- C モデル: M モデルの隠れ表現と V モデルの出力をもとに行動を生成。パラメータ数が少ない非常にコンパクトなモデル。(訳 1000 パラメータ)
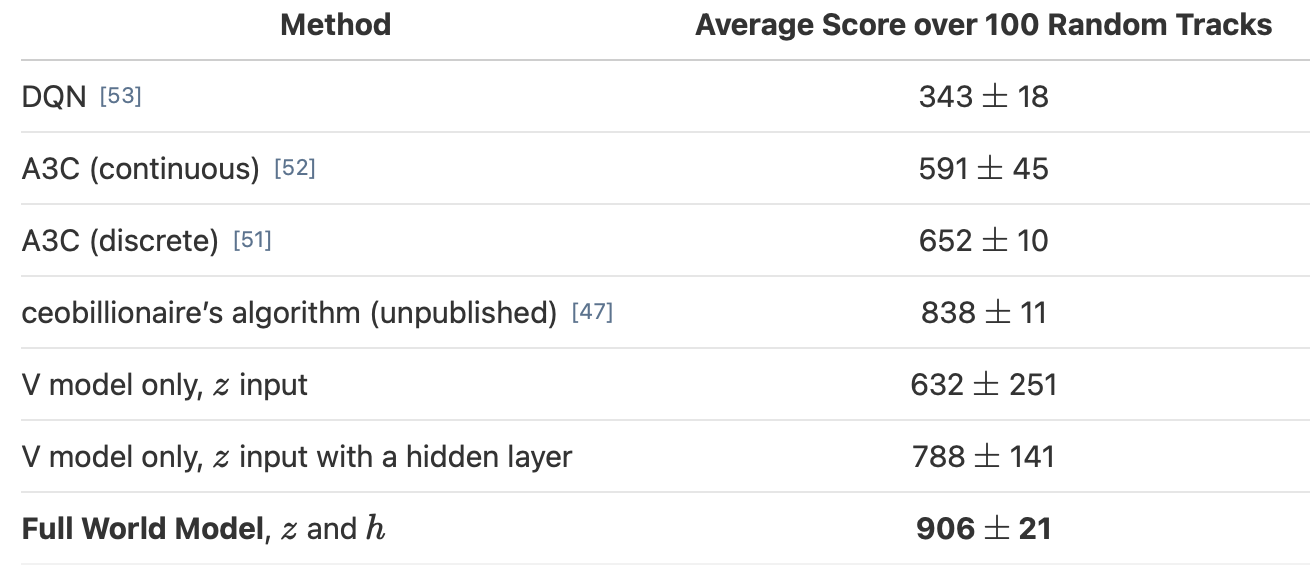
Car Raceゲームをこの世界モデルに解かせたところ、906±21 点という高得点を記録した。これは現在報告されている最良モデルの 838±58 点の 訳1.1倍の得点である。
このようにエージェントモデルをコンポーネントとして分割し学習することは、既存の手法に比べて
有用である事がいえる。
Mモデルの必要性
また、M モデルを取り除き V モデルのみを用いて C モデルを学習させた場合も検証した。これは従来の強化学習の形式と同様である。
カーレースゲームをこのエージェントに解かせたところ、632±251 点を記録した。Cモデルを多層化しパ ラメータを増やしても 788±141 点だった。これは過去最高得点の 838±11 を超えられておらず、プレイ中の 動作も左右に大きく揺れ、不安定だった。
V モデルだけでは性能を十分に向上させることは難しいと考えられる。RNN ベースの M モデルの存在が大きく性能に貢献しているといえる。

"夢"の中で学習する
Mモデルは世界の状態遷移を学習していくため、実環境の近似シミュレータとなる。よってVモデルとMモデルをランダムに行動を生成するCモデル用いてデータセット集め事前に学習させた。そしてCモデルをMモデルの内部でのみ学習させた。
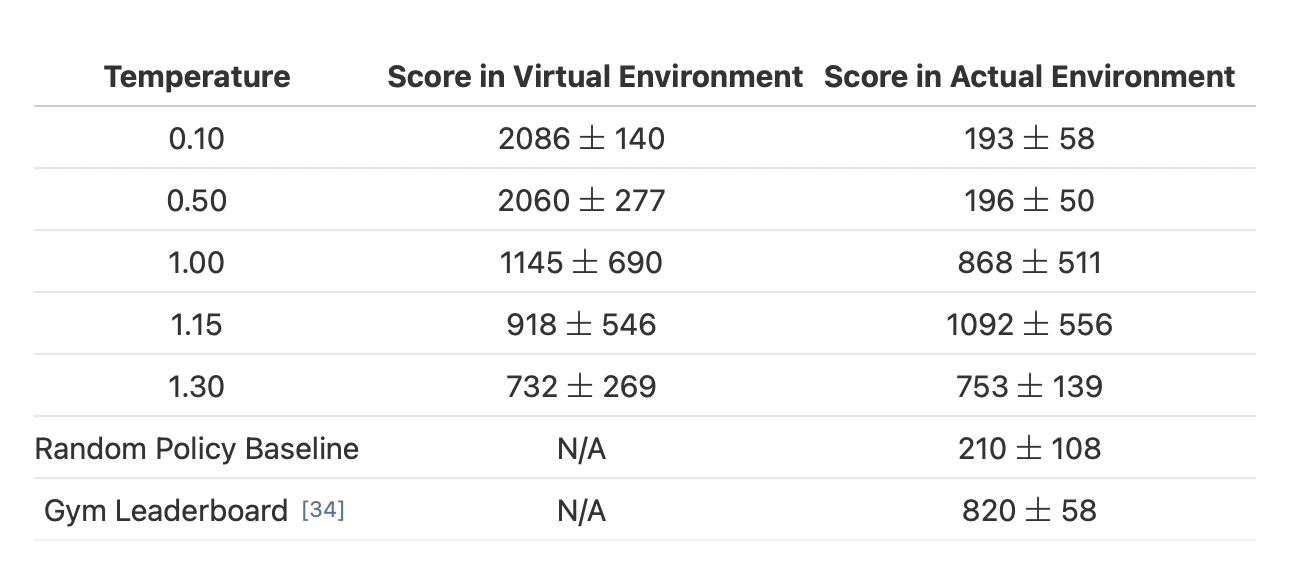
VizDoomというゲームをこのような形で解かせたところ、実環境において1092±556という高得点を記録した。Mモデルの中では918±546点であった。ランダムに行動させた場合のスコアが210±108であり、報告されている中で最高性能が820±58点である。
また実環境を用いずに並列化処理が用意なMモデル内部でのみCモデルを訓練するため、計算機のパワーを十分に使う事ができ、学習データのサンプル効率が良かった。
従って性能・計算効率の二つの観点から見て、Mモデルの内部でのみCモデルを学習させる方法(夢の中で学習すること)は有用である事がいえる。
CモデルのCheating
決定的に次の状態を予測するMモデルの中でCモデルを学習させた。
Mモデルは近似された環境ダイナミクスモデルであるため不完全である。決定的に次の状態を予測する M モデルを用いると、その中で学習する C モデルはその決定的に起こる不完全な予測を利用し、本来のタスクを解かずに得点だけを得てしまった。
実世界の環境が確率的であることも踏まえ、M モデルは次の状態を確率的に予測できなければ、目的のタスクを解く C モデルを得ることは難しいといえる。

まとめ
深層強化学習エージェントを、環境をシミュレートするように学習する大きなパラメータを持つモデルと、コンパクトなコントローラーモデルに分割することによって、効率的かつ高い性能に訓練可能である。
環境の移り変わりを近似した M モデルのみを用いてコンパクトな C モデルをトレーニングする事ができ、 計算効率の観点からも非常に有用で、大きなパラメータ用いたエージェントにおいても信用割当問題を回避する事ができる。
世界のモデルをエージェントの内部に持たせるこの手法は、私たちの直感にも合致し高い性能を発揮する上に、将来性も非常にあるとても強力な手法である