はじめに
どうも、限界ちゃんです🐹
この度はセキュリティ・キャンプ全国大会へ参加することになったので、応募課題晒しというものをやってみようと思います。
※私の課題は必ずしも正解ではありません。そこはお許しを...
来年度以降参加を考えている人の参考になったら嬉しいです。
私は専門コースの「脅威解析クラス」に応募しました。体調も悪かったこともあり、だいたい1週間弱の期間で課題は完成させました。(体調管理めっちゃ大事。)

課題に取り組むにあたって、先輩方の応募課題晒しをたくさん読みまくりました。あとは、担当プロデューサーの選考のポイントをチェックしておくのも大切です。

脅威解析クラスの応募課題は、例年技術的に難しいと言われていますが、これは決して現在の技術力が高い人を選ぼうと意図しているからではありません。
/ 略
応募課題は正答することがすべてではありません。今現在においてハードルの高い課題であっても、果敢に立ち向かってくる人、将来的にはそのハードルを超えると思わせてくれる人、そういった方からの応募をお待ちしています。
本当に応募課題は難易度が高くて本当に心が折れかけました笑。書いてあるように、正解が全てではありません。
実際に、私も解けなかった大問があります。全ての問題を解けることが1番いいですが、解けなかったとしても諦めないでください。その"過程"で「なにをやってみたのか・勉強になったことはなにか」を全力で書くのが大事です。これは、このコースに限ったことではないと個人的に思っています。
課題
問1
あなたがセキュリティ・キャンプ全国大会に応募する理由を教えてください。受講生や講師とのコミュニケーション、受講したい講義、なりたい自分など、何でも構いません。
私がセキュリティキャンプに応募した理由は「自分の興味と知識を深めたい。新しい領域にも足を踏み入れたい。」からです。特に以前から興味のある「脅威インテリジェンス」というキーワードが入っていたのが、このコースを選択した1番の決め手です。
私は今年の春にインターンシップに参加して、初めて脅威インテリジェンスについて本格的に触れました。そこではAPTグループについて調査と考察をして、レポートにまとめるという経験をしました。
APTグループの複雑さや脅威インテリジェンスの奥深さを知り、さらに脅威インテリジェンスについて興味を持つようになりました。しかし、MITRE ATT&CKフレームワークの活用やIOCの作成技法など経験したことがないことなどまだ経験したことがないものが沢山あります。
また、マルウェア解析にも興味があります。CTF(Capture The Flag)の問題で実行ファイルの解析をした経験が少しだけあります。しかし、この分野にはほとんど足を踏み入れたことがありません。本コースの講義では、「マルウェア解析の基礎からはじめて、応用方法まで学べる」という点に加えて、実務におけるマルウェア解析と同じ手順を学べるということで、非常に良い経験ができると感じました。
これ以外の講義でも、全体を通して、自力で脅威の本質を見極め、適切な対策を行えるようなトレーニングを受けられることにワクワクしています。
同じセキュリティに興味を持った受講生と関わることで、お互いに良い影響を与えながら技術や知識を高め合える関係を築けることを期待しています。
問2
今までに解析したことのあるソフトウェアやハードウェアにはどのようなものがありますか?解析の目的や解析方法、結果として得られた知見などを含めて教えてください。
私はCTFでWeb問題やOSINT問題をメインで解いていますが、PwnやReversingをはじめとした他の領域も力をつけたいという目的で、いくつかのファイルを解析したことがあります。その中でも、最近解いたReversing問題について書きます。対象のファイルは64ビットのELF形式の実行ファイルです。
まず、Ghidraを使用しての静的解析を行いました。関数の一覧から、mainが見つかったので、そこから確認をしました。ここではユーザーからの入力を受け付けて、入力値とハードコードされたデータを比較し、両者が一致するかどうかを判定しているようでした。なので、このハードコードされたデータをメモしておきます。
他の関数も確認しましたが、その動作を理解するのが難しかったため、デバッガーを使った動的解析に移りました。
動的解析はgdb-pedaを使って行いました。runコマンドを実行すると入力が求められるので、適当に「ABCDE」などと入力しておき、プログラムの実行を一時中断しました。ここから1命令ずつプログラムを実行して、動作を細かく確認をしていきます。進めていくと、ハードコードされたデータの1バイト目をraxレジスタ、2バイト目をrbxレジスタに格納しこれらをxorした結果と入力値の1バイト目をcmp命令で比較していることが分かりました。続けて、ハードコードされたデータの3バイトをraxレジスタに4バイト目をrbxレジスタに格納しxorし、これらをxorした結果と入力値の2バイト目を比較、以降同様の処理が続いていましたその結果を入力値の2バイト目と比較、以降同様の処理が続いていました。よって、ハードコードされたデータの奇数バイト目を直後の1バイトをxorしていくことで、解析が進められると考えました。この処理をするpythonスクリプトを作成して実行したところ、flagを入手できました。
これまで、プログラムのリバースエンジニアリングをやった経験がほとんどなかったため、Ghiraやgdb-pedaの使い方に慣れていませんでした。この解析を通して、レジスタの状態や次に実行される命令、スタックの状態などを確認するためにはどうすれば良いのかを学習することができました。また、cmp命令に関して追加で調査したところ、異常文字列判定を行なう際に使用されることがあると知り、さらに理解が深まりました。
問3
今までに作成したソフトウェアやハードウェアにはどのようなものがありますか?
どんな言語やライブラリ、パーツを使って作ったのか、どこにこだわって作ったのか、などたくさん自慢してください。
ここは個人的な内容なので公開なしにします...!
問4
ここ数年に発表された、以下のキーワードに関連するニュースや記事や学術論文から1つ選び、それに関して調べた内容を記述してください。内容には、1.選んだ理由、2.技術的詳細、3.被害規模または影響範囲、4.対策、の4点を必ず含めてください。なお、対策は今ある技術のみに捕われず、将来的な技術や法律など、自由な発想で書いてください。
キーワード:
- 脆弱性
- マルウェア
- エクスプロイト
- サプライチェーン
- 国家支援型攻撃
<選んだニュース>
北朝鮮のハッカーグループであるKimsukyがDMARCを悪用しているというニュースを選びました。
“North Korean Actors Exploit Weak DMARC Security Policies to Mask Spearphishing Efforts”
”北朝鮮APT攻撃グループ「TA427」:DMARC設定が緩い日本政府などの組織になりすまし、ソーシャル・エンジニアリングで情報収集”
<選んだ理由>
友人との会話でこのニュースを知ったことがきっかけです。最近、北朝鮮のハッカーグループに関する本を読み、北朝鮮のハッカーグループの行動についても興味を持ったためこの記事を選びました。
<技術的詳細>
今回悪用された技術はDMARC(Domain-based Message Authentication Reporting and Conformance)という送信ドメイン認証技術です。
受信したメールが正規のメールサーバーを経由してメールが送信されたのかを受信者が確認できる仕組みで、偽装メールを防ぐことが目的です。
この仕組みを送信ドメイン認証といいます。
DMARCはSPF(Sender Policy Framework)とDKIM(DomainKeys Identified Mail)と呼ばれる技術がベースとなっています。
SPF
SPFはメールに記載されているエンベロープFromのドメインと送信元のメールサーバーのIPアドレスが一致しているかを受信側のサーバーで確認します。
メール送信時に利用するIPアドレスを送信側のDNSにSPFレコードを事前に登録しておき、受信側はメール受信時に送信側のSPFレコードと照合することで、正当なメール送信元であるかを判断します。
SPFレコード例:hoge@huga.com. IN TXT “v=spf1 ip4: IPアドレス -all”
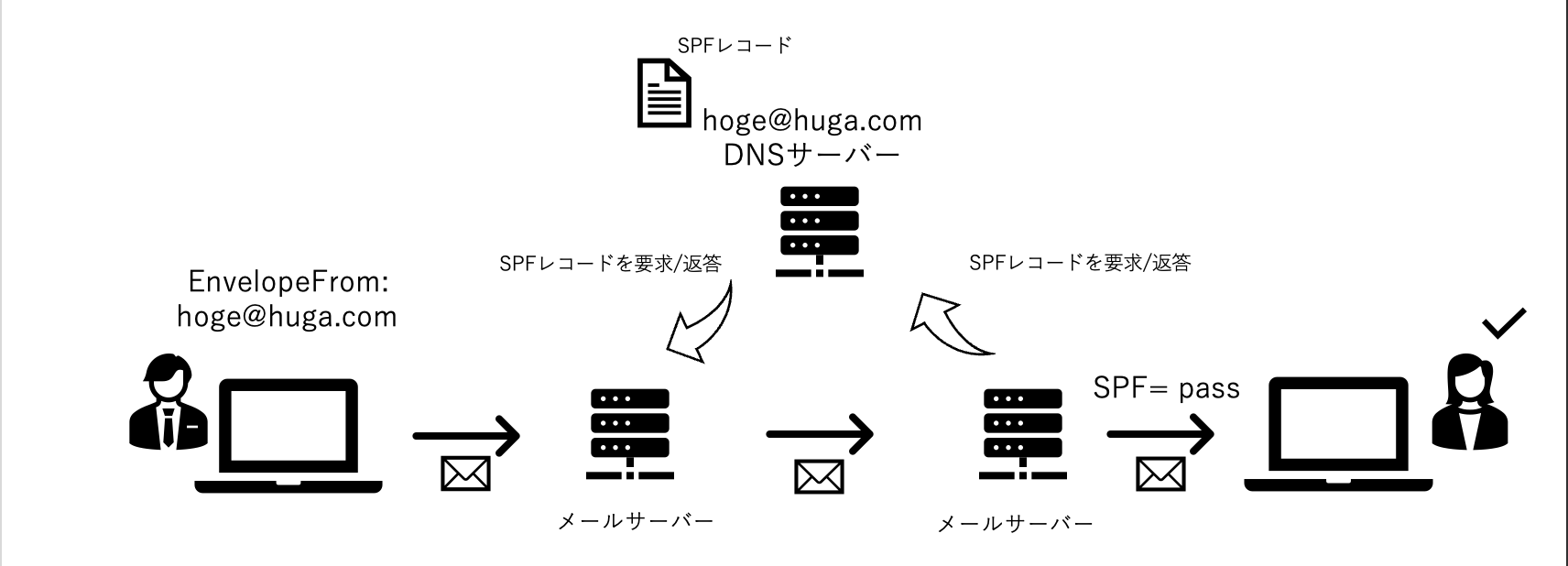
正当なメールが届いた場合には、ヘッダー部分に「Recived-SPF: pass」と記載されます。一方、異なるメールサーバーを使って第三者がメールを送る場合、IPアドレスが一致しないので「Recived-SPF: fail」となります。
ただし、SPFには以下のような欠点があります:
・SPFに失敗しても、そのメッセージが常に受信トレイからブロックされるとは限らない。
・メッセージが転送されると、SPFは解除されてしまう。
・SPFを使用していない、偽のメールサーバーを使用することでSPFチェックを無効にすることができる。
DKIM
DKIMはメールのヘッダーや本文から作成したデジタル署名をメールに付加して、メールサーバーがその署名を検証することで、メールの送信元を認証する技術です。
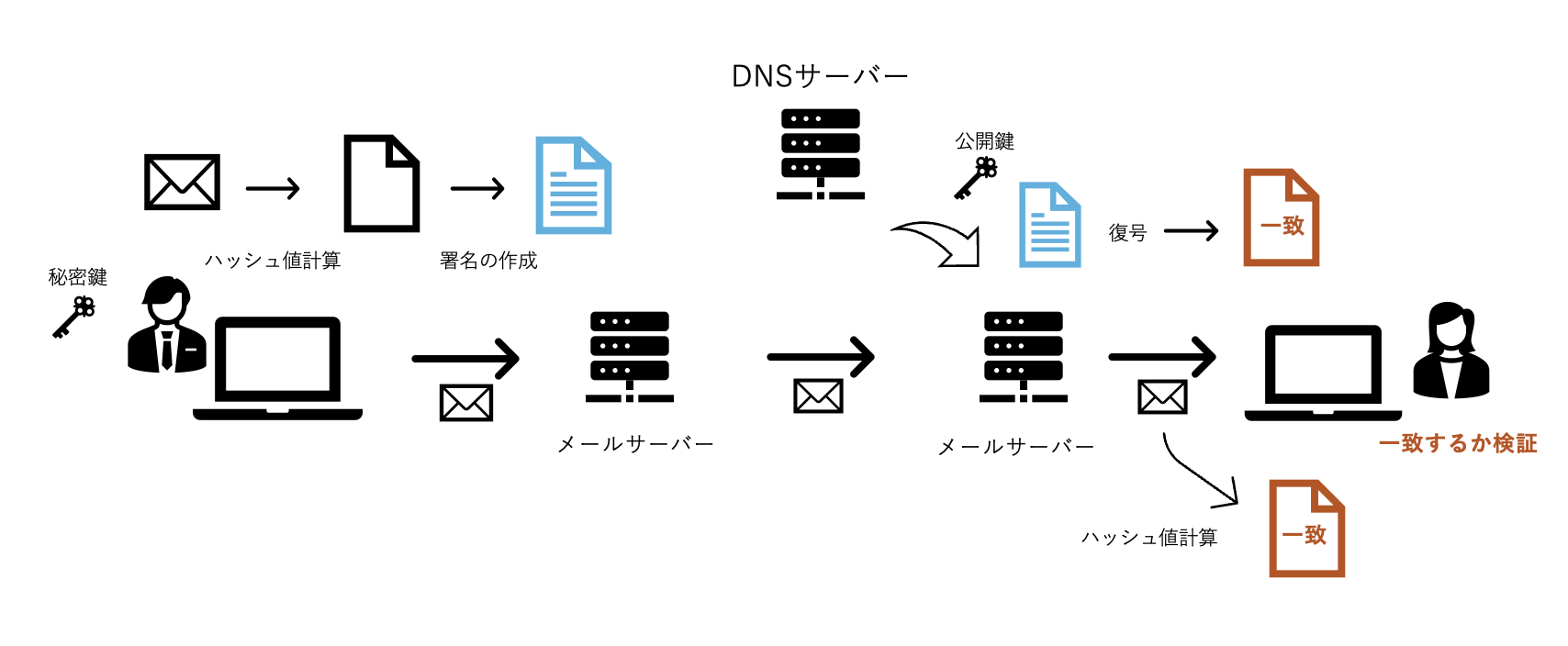
ただし、DKIMには以下のような欠点があります:
・実装と管理が難しいため、普及率が低い。
・偽のメールサーバーを使用して、DKIMをつけずに送信することができる。
DMARC
SPFやDKIMでの認証失敗時のアクションをDNSにDMARCポリシーとして宣言して、受信メールの扱いを判断します。
DMARCポリシーでは、「None」「Quarantine」「Reject」の3つを設定できます。
- None(なし)
メールは受信者に配信されて、DMARCレポートはドメイン所有者に送信されます。
- Quarantine(隔離)
メールが隔離され、迷惑メールフォルダに移されます。
- Reject(拒否)
メールは拒否され、送信元にバウンスメールが送信されます。
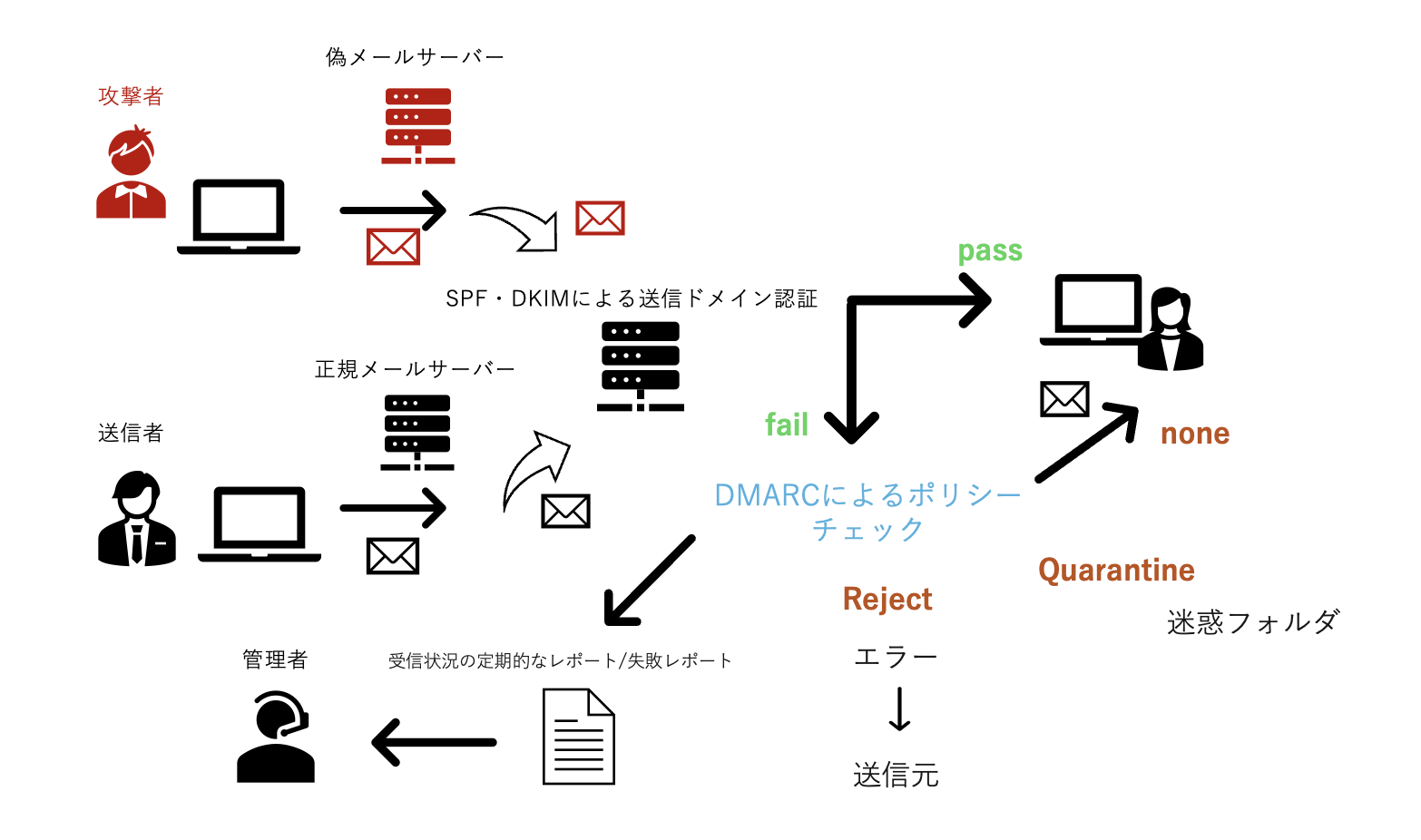
DMARCレコードに
「_dmarc.hoge.com. IN TXT “v=DMARC1; p=none”」
と登録すると、noneポリシーが設定されます。
今回Kimsukyはポリシーが”none”に設定されているのを悪用し、メールを送ってスピアフィッシングを行いました。
<被害規模または影響範囲>
2024年3月20日、国連安全保障理事会は北朝鮮が外貨収入の約50%をサイバー攻撃によって得ているということにあわせて、核やミサイルなどといった大量破壊兵器の開発費用の約40%がサイバー攻撃から得た資金であることも指摘しました。被害額として、2017年から去年までで日本円で4500億相当が奪われました。
今回のKimsukyの目的は、標的となる個人や組織の秘密の文書・研究・通信への不正アクセスを通じて、地政学的な出来事・対抗する外交政策戦略・および北朝鮮の利益に影響を与える情報に関する情報を収集することです。これらのことを踏まえて考察すると、以下3つの影響が考えられます。
1. 外交政策戦略への影響
対抗国の外交政策戦略に関する情報は北朝鮮の対外政策の方針を決める手助けとなります。他国との関係を調整する中で、北朝鮮が国際社会での立場を強化するきっかけにもなると思います。
2. 経済への影響
Kimsukyの活動によって、技術や研究といった機密情報が流出することで企業や組織の競争力や価値が奪われ、北朝鮮が経済的な利益を得ることになります。また、地政学的な情報を使って隣国や主要国との経済関係や貿易動向などを把握することで、北朝鮮は外交政策や経済戦略を立案するカギになると思います。
これらによって得られた利益でさらなる軍事力強化がされてしまう可能性があると思います。
3. 国内政治の安定性
政府や重要機関がサイバー攻撃のターゲットになってしまった場合、国内の政治的な不安定化や国民の信頼を失う原因にもなりかねないと思います。
<対策>
今回1番の原因であったのは、DMARCポリシーの設定が「none」であり、どのようなメールも受け取れてしまう状況にあったことです。
そのためDMARCポリシーを「Quarantine」または「Reject」に設定することが推奨されています。
メールを受け取ってしまった場合でも、メールの内容からも判断できます。メール内の文章が文法的に少し変であったり、稚拙だったりする場合には注意する必要があります。
安易に添付されてきたファイルを開くことやリンクをクリックしないようにトレーニングを提供することも対策として有用だと思います。
また、DMARCで防ぎきれなかったメールを機械学習やAIを使って送信されるメールのパターンや特性を学習して事前に悪意のあるメールをブロックしたりMFAをより強化して送信元の正当性を確認できたりするような新たな技術ができると思います。
問5-1
TCPのポートに対するポートスキャンの方法には、TCP SYNスキャン、TCP Connectスキャンが知られています。それぞれの動作原理を説明してください。
また、これらの手法には互いに長所と短所が存在します。
TCP SYNスキャンとTCP Connectスキャンのそれぞれの長所/短所を動作速度や検知されやすいかという観点から述べてください。
SYNスキャン
TCP SYNスキャンはステルススキャンやハーフオープンスキャンとも呼ばれている、ポートスキャン方式です。
動作原理
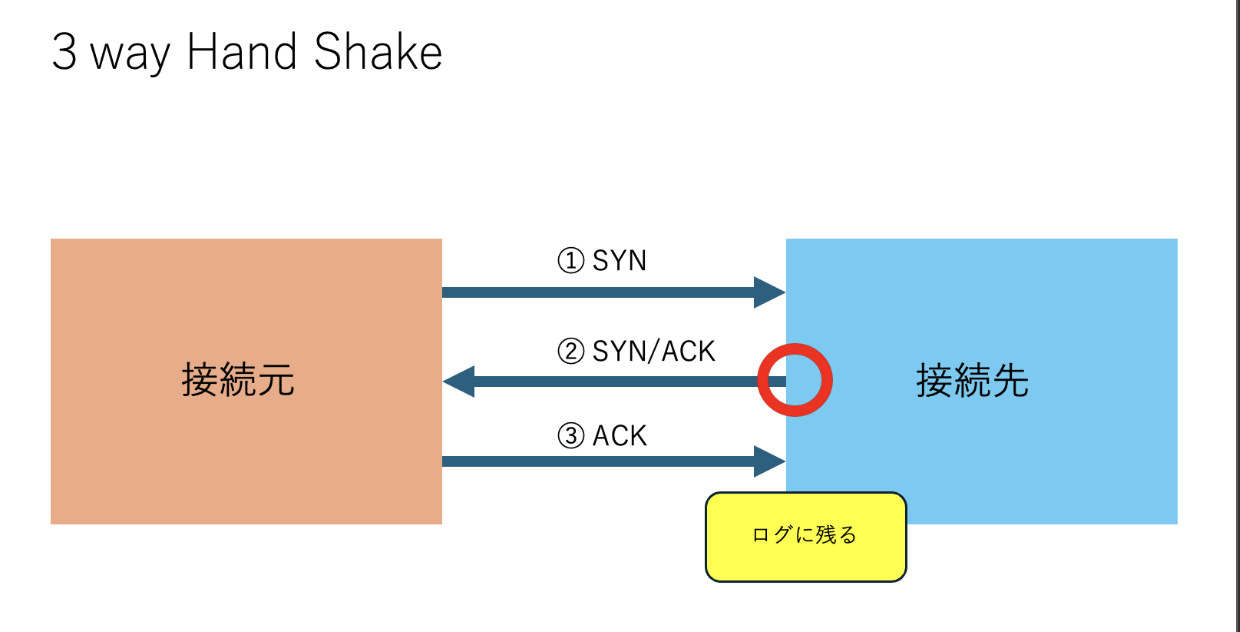
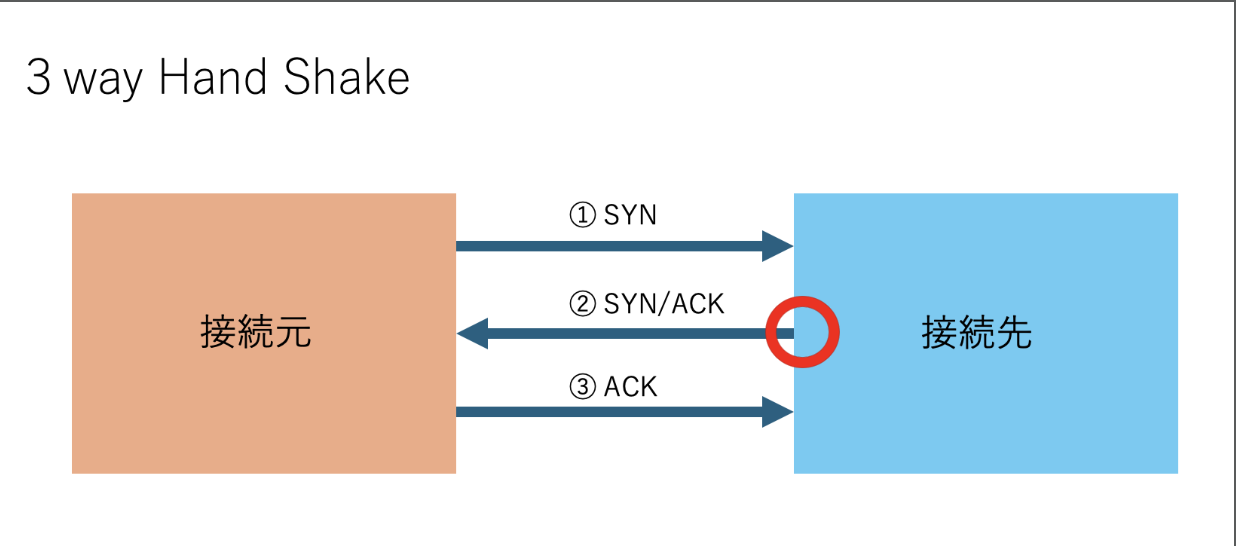
3 way Hand Shakeという方法で接続が成立したかを判断し、ポートの開閉を判断します。
まずは、TCP接続の基本原理である3 way Hand Shakeを説明します。
AとBが通信する状況で、A起点で3 way Hand Shakeを始めることにします。
3 way Hand Shake
① AはBの宛先ポートに”SYN”パケットを送ります。このとき、TCPヘッダ内のSYNフラグ
が1となります。
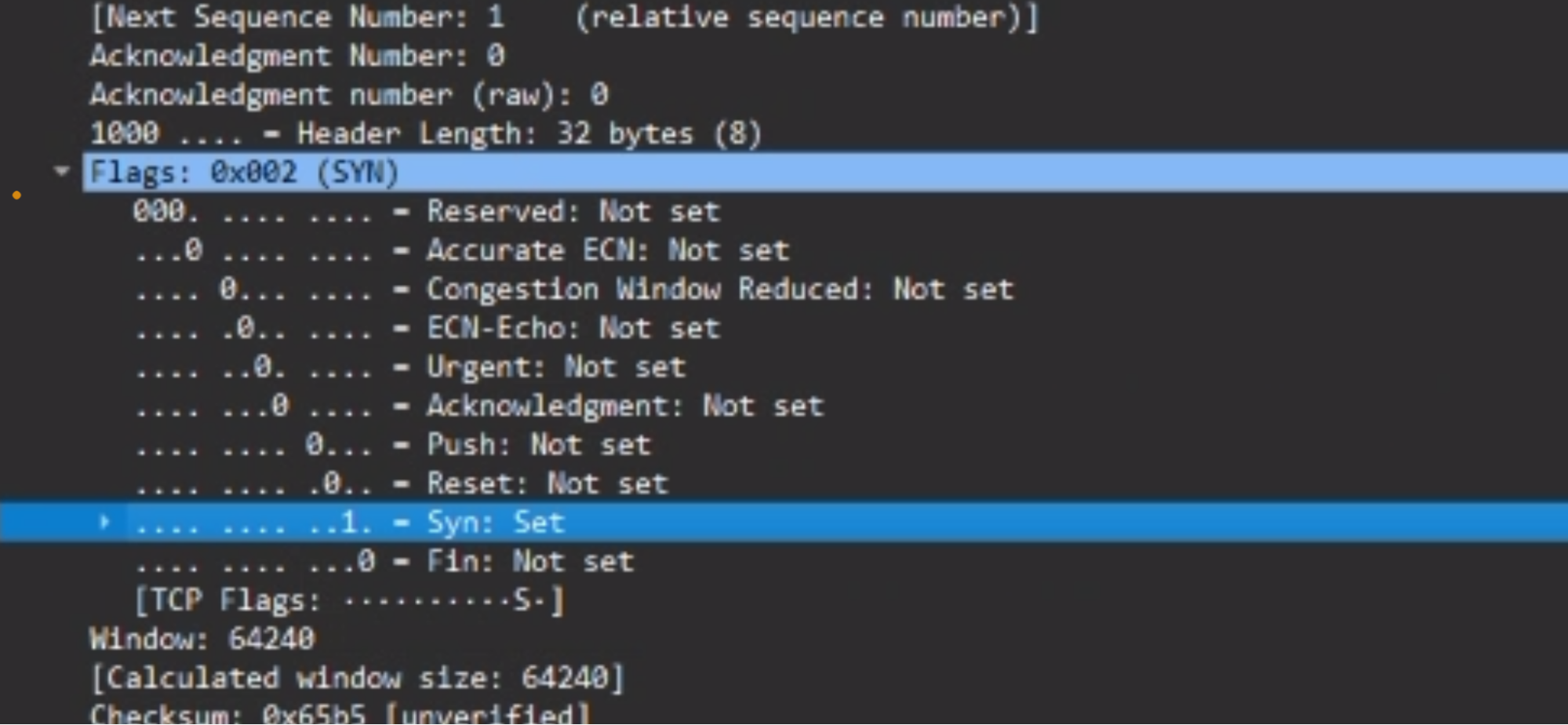
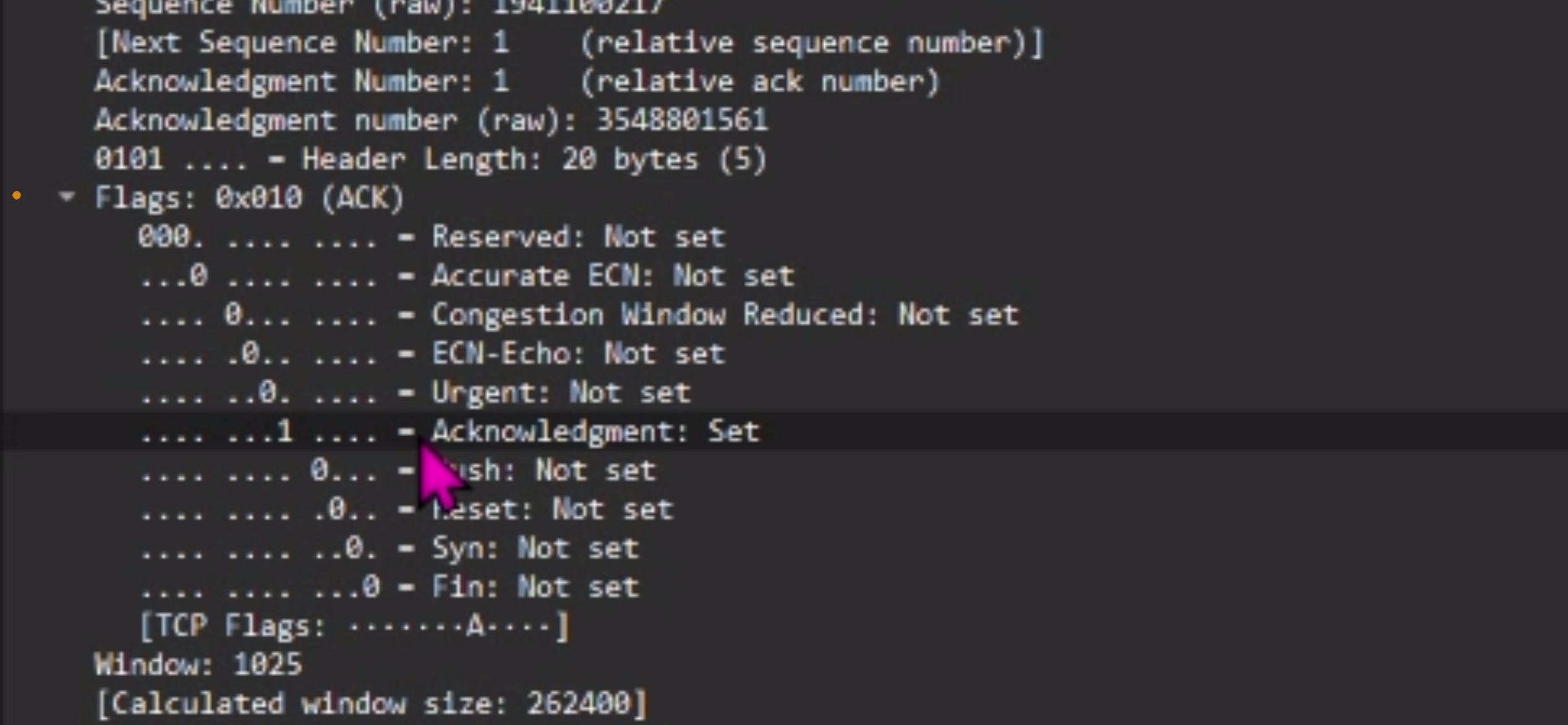
② Bは“SYN”パケットを受信し、そのポートが開いている場合は”SYN/ACK”パケットをAに返し、そのポートが閉じている場合は”RST/ACK”パケットをAに返します。”SYN/ACK”パケットではTCPヘッダ内のSYNフラグとACKフラグが1となり、”RST/ACK”ではRSTフラグとACKフラグが1となります。
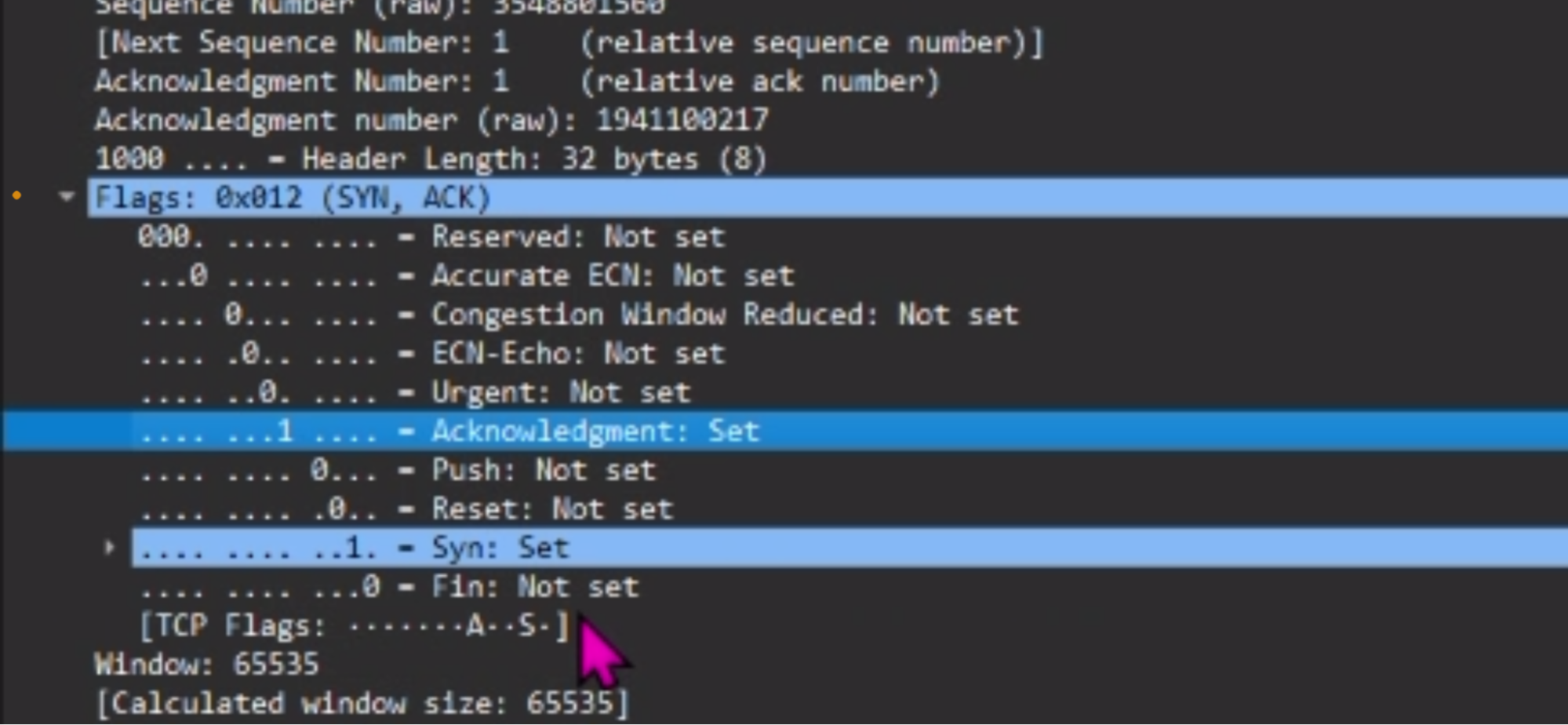
③ Aは”SYN/ACK”パケットを受信すると、Bに”ACK”パケットを返します。このとき、TCPヘッダ内のACKフラグが1となります。これで、TCP接続が確立します。この時点でログに残るようになります。
イメージ図:
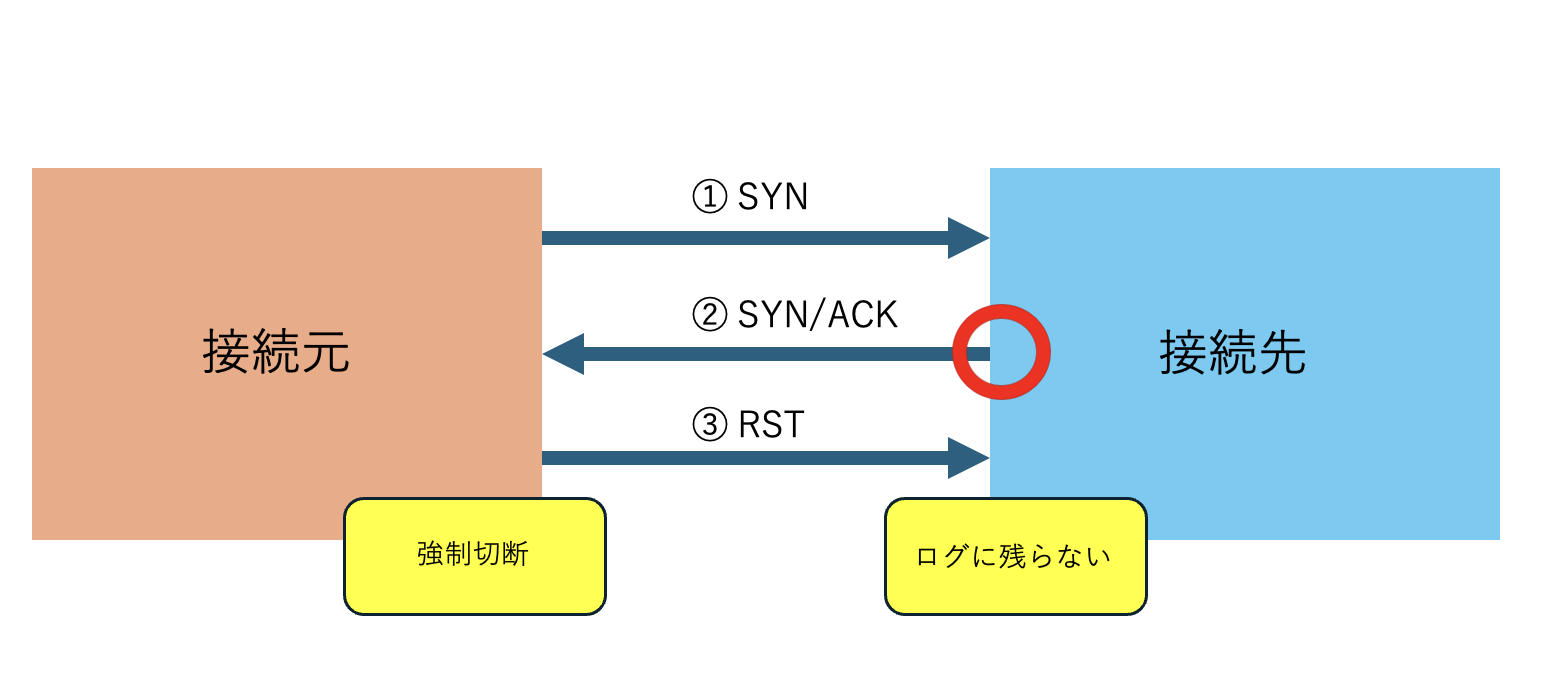
SYNスキャン
3 way Hand Shakeを踏まえて説明すると、②の”SYN/ACK”パケットを受信した時点で、ポートが開いているかが分かります。つまり、最後の③まで行わなくても良いということです。②を終えたタイミングで、TCPヘッダのRSTフラグ(接続強制切断)のみを1にしたパケットを返します。これがSYNスキャンです。
【長所、短所、動作速度、検知されやすさ】
・NmapのFin・Null・Xmas・Mamion・Idleスキャンのように特定のプラットフォームに左右されずに、規格準拠のTCPスタックなら何に対しても機能します。
・open・closed・filteredというポートの状態を明確かつ確実に区別することができます。
・強制的なファイアウォールによる妨害のない、高速なネットワーク上では、数千ポート毎秒という高速なスキャンを実行できます。
・コネクションの確立を行わないため、検知がされにくいです。
・Rawソケットを使ってパケットの生データを扱うので、管理者権限が必要になります。
・IPv6のホストには対応していないことが短所です。
Connectスキャン
TCP Connectスキャンでは、3 way Hand Shakeを最後まで行います。
【長所、短所、動作速度、検知されやすさ】
・通常のネットワークアプリケーションが使用するような方法で接続を確立するので、管理者権限が必要ありません。
・IPv6のホストに対しても使用ができます。
・生パケットよりも高レベルのシステムコールを使用するため、制御が制限され、処理効率が低下するため、SYNスキャンよりも低速です。
・IDSやfirewallに検出されやすいです。
問5-2
RustScanやMASSCANなど、Nmapより高速にスキャンを行えるポートスキャナが台頭しています。
しかし、ポートスキャンを高速に行うと問題が生じる場合(特に社内/学内などの内部ネットワークを対象とする場合)があります。
具体的な影響の例とともに考えられる問題点を述べてください。
高速なポートスキャンが行われると、ネットワークトラフィックが急増し、ネットワークに過度な負荷がかかる可能性があります。これにはいくつかの具体的な影響があると考えます。
①ネットワークトラフィックの急増
短時間に大量のパケットのやり取りをすることで、ネットワークトラフィックが急増してしまいます。これによってネットワーク領帯が圧迫されてしまいます。その結果、通信が遅延したり途絶えたりする可能性があります。例えば、多くのデバイスが接続されている環境などだと大きな影響になってしまうと思います。
②サーバーへの負荷
高速なポートスキャンによってサーバーに大量のリクエストが送信されると、サーバーがそれを対応仕切れなくなってしまいます。その結果、サーバーの応答が遅くなってしまったりサーバーがクラッシュしてしまう危険もあります。ウェブサーバーやデータベースのサーバーなどがこのような状態になってしまうと、業務で使用するアプリケーションなどが使えなくなってしまうかもしれません。
③サービスの一時停止
高速なポートスキャンをすることで、サービスが一時停止されてしまうかもしれません。例えば、オンラインショッピングサイトや金融機関のシステムが一時停止されると、金銭的な面でも影響を及ぼしてしまいます。
ペンテスターが早く業務を終わらせたいと考えて、高速なポートスキャンを使用してしまうと、以上のような、サーバーが応答しなくなったりサービスが一時的に利用できなくなったり、通信が低速になってしまったりしてしまいます。これによって、メールやチャット通信が遅れてしまって、大切な業務連絡を即座に受け取ることができなかったり、リモートワークをしている社員がVPN接続の遅延のせいで、業務効率が低下してしまったりと検査対象を業務で使用しているクライアントに迷惑をかけてしまいます。
問6
配布したアーカイブファイル内のimage.ddはディスクをddコマンドでコピーしたイメージファイルです。これらを用いて以下の問題に簡潔に解答してください。
問6-1
イメージファイルimage.ddに存在するファイルシステムをmountコマンドまたは同等の機能を持つユーティリティでマウントできるようにしてください。
その過程でイメージファイル内のどの部分をどのように変更したのか、なぜそれでマウントできるようになるのかを簡潔に解答してください。
大問6はいろいろな方法を試してみましたが、知識不足で解くことができませんでした。そのため、自分が試してみたこと・勉強になったことを書きます。
<試してみたこと>
①ファイル情報を確認してみる
fileコマンドで情報を確認しました。
$ file image.dd
image.dd: DOS/MBR boot sector; partition 1 : ID=0xee, start-CHS (0x0,0,2), end-CHS (0x3ff,255,63), startsector 1, 2097151 sectors, extended partition table (last)
このディスクイメージがGPTディスクを保護するMBRパーティションを含んでおり、複数のパーティションが存在する可能性があることがわかります。
fdiskコマンドでも詳細な情報が確認できるので、このコマンドでも確認をしました。
$ fdisk -l image.dd
Disk image.dd: 1 GiB, 1073741824 bytes, 2097152 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: E83A394F-0BFE-47F9-9837-763DF6404F58
Device Start End Sectors Size Type
image.dd1 2048 2095103 2093056 1022M Linux filesystem
こちらでは、GPTパーティションテーブルの情報がわかります。開始セクターや終了セクターなども表示されます。
②マウントを試してみる
今回はLinuxのファイルシステムであるため、-tで”ext4”を指定しました。
# mount -t ext4 image.dd
mount: image.dd: can't find in /etc/fstab.
「can't find in /etc/fstab」とエラーが返ってきました。「/etc/fstab」ファイルは、マウントするファイルシステムの情報を記述するファイルです。どうやら、mountコマンドは/etc/fstabファイルにエントリがないらしいです。
次にマウントポイントを追加して、どうなるのか確認しました。
$ mount -t ext4 image.dd MountDirectory
mount: MountDirectory: failed to setup loop device for /home/kali/Desktop/work/image.dd.
「failed to setup loop device」と返ってきました。ループデバイスを設定する必要がありそうです。
③ループデバイスを設定してみる
losetupコマンドを使用して、ディスクイメージをループデバイスに関連付けます。
# losetup -P /dev/loop0 image.dd
このとき/dev/loop0というデバイスにimage.ddが関連付けられます。-Pオプションをつけることで、イメージファイル内のパーティションを自動的に検出して、loop0p1やloop0p2などのパーティションデバイスを作成してくれます。
# ls -lta /dev | grep "loop0p1"
brw-rw---- 1 root disk 259, 0 May 18 02:28 loop0p1
作成されていることが確認できました。
loop0p1の仮想デバイスがMountDirectoryにマウントできるか試してみます。
# mount /dev/loop0p1 MountDirectory
mount: /home/kali/Desktop/work/MountDirectory: wrong fs type, bad option, bad superblock on /dev/loop0p1, missing codepage or helper program, or other error.
dmesg(1) may have more information after failed mount system call.
失敗したようです。エラーメッセージで示されているdmesgコマンドを使って、細かくエラーメッセージを確認してみます。
[ 5703.900246] EXT4-fs (loop0p1): VFS: Can't find ext4 filesystem
loop0p1がetx4ファイルシステムとして認識されていないようです。パーティションのファイルシステムを確認してみます。
# file -s /dev/loop0p1
/dev/loop0p1: data
そもそも、マウントしようとしているパーティションが正しく検出されていないようです。
この後、ループデバイスを何度も再設定してみましたがうまくいきませんでした。
④パーティションテーブルの修復を試してみる
パーティションテーブルが故障していると予想をしたので、パーティション情報を修復することができるTestDiskとよばれるソフトウェアを試してみました。使い方が分からなかったため、様々なWebサイトや動画を参考にしながら、どうにか直らないか試行錯誤しました。
Searchをかけたあとに「No partition found or selected for recovery」と表示されてしまったので、DeeperSearchも試してみました。パーティションは表示されましたが、「The following partition can't be recovered」とのことでした。そこで、新たなパーティションを追加してみました。開始セクターと終了セクターはファイル情報を確認したときにわかっていたため、書き込んでみます。
Disk image.dd - 1073 MB / 1024 MiB - CHS 131 255 63
Partition Start End Size in sectors
>P EFI System 2048 2093056 2091009
[ Quit ] [ Return ] >[ Write ]
Write partition structure to disk
その後に、mountコマンドでマウントを試してみましたが、マウントは成功しませんでした。
⑤MBRを修復してみる
HDDの先頭セクタに置かれるMBRはLinuxがブートするためには重要な512バイトになり、ここが壊れるとシステムがブートしなくなるということを知りました。そこで、MBRを修復したらマウントできるのではと予想をたてました。調べてみると、grub-installを使用して修復することが可能ということなので、実際にやってみます。
Installing for i386-pc platform.
grub-install: warning: this GPT partition label contains no BIOS Boot Partition; embedding won't be possible.
grub-install: error: embedding is not possible, but this is required for cross-disk install.
というエラーメッセージが返ってきました。GPTラベルにBIOS Bootパーティションが含まれていないようです。
⑥バイナリをいろいろいじってみる
バイナリエディタで編集してみることにしました。BIOS bootパーティションを追加するために、新しいパーティションを追記してみます。書き込む情報は、パーティションの種類GUID・パーティションの開始位置・パーティションの終了位置です。しかし、こちらもうまくいきませんでした。
もういちど考え直してみることにしました。ゼロがずっと続くのでそこが怪しいと感じました。
# hexdump -C -n 512 image.dd
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000001c0 02 00 ee ff ff ff 01 00 00 00 ff ff 1f 00 00 00 |................|
000001d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000001f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa |..............U.|
00000200
しかし調べてみると、00000000 - 000001bfの部分がすべてゼロでも、ブートストラップコードが含まれることがありますが、ゼロでも問題ないということでした。
⑥OSINTしてみる
もしかしたら、OSINTをすることによってファイルをマウントできるヒントや情報が見つかるのではないかと最後に考えました。そこで、dropboxの情報のところからアップロード元が「Nashiwa Hisao」となっていたので、梨和久雄さんが書かれた記事やSNSなどをかなりチェックしてみました。見つかりませんでした。
<勉強になったこと>
この課題を通して、そもそもファイルシステムとはなにか、パーティションとはなにか、ファイルシステムにはどのようなものがあるか、ブートセクタとはどのようなものでどのような種類があるのか、ループバックデバイスはどういうものなのか、など新しい知識を入れることができました。
また、使ったことのなかったコマンドやTestDiskといったソフトウェアも知ることができたので、CTFのForengics問題に挑戦するときには使ってみたいです。
最後に、どのようなファイルが入っていたのかとても気になったので、foremostを使ってファイルを復元してみました。
# ls -lta
total 20
drwxr-xr-- 4 kali kali 4096 May 18 04:51 .
-rw-r--r-- 1 kali kali 772 May 18 04:51 audit.txt
drwxr-xr-- 2 kali kali 4096 May 18 04:51 pdf
drwxr-xr-- 2 kali kali 4096 May 18 04:51 htm
drwxr-xr-x 4 kali kali 4096 May 18 04:50 ..
pdfファイルとhtmlファイルが見つかりました。pdfファイルとhtmlファイルはどちらもデロイトトーマツのものでした。
この大問6は解くことができませんでしたが、セキュリティキャンプの講義を通して、さらにコンピュータフォレンジックの知識を取り込みたいと思うきっかけになりました。
問6-2
問6-1でマウントしたファイルシステム形式の名称(例:FAT16)と、そう判断した理由を簡潔に解答してください。
マウントができなかったので、解くことができませんでした。しかし、色々勉強になったのでファイルシステム形式についてわかったことをまとめます。
<そもそもファイルシステムとは?>
ファイルシステムとはOSの機能の一つで、永続的にデータを保存できる記憶装置内部の記録状態を管理・制御し、人間に分かりやすいファイル単位でデータの書き込みや読み出しができるようにするシステムのことです。
<ファイルシステムの種類>
①FAT (File Allocation Table)
FATは、昔からあるファイルシステムです。元々はMS-DOSで使用されていました。FATには複数のバージョンが存在し、その中でも特に有名なのがFAT12、FAT16、FAT32です。
特徴:
・FAT12: 初期のフロッピーディスクで使用され、最大容量は32MBです。
・FAT16: HDDにも対応し、最大2GBのパーティションをサポートしますが、ファイルサイズ制限が2GBです。
・FAT32: 最大2TBのボリュームサイズをサポートし、個々のファイルサイズは最大4GBです。互換性が高く、多くのデバイスで使用されています。
拡張版では、exFAT(Extended FAT)というものがあります。大容量で実質的にファイルサイズやパーティションサイズの制限がほぼありません。WindowsとMacOSの両方で使用可能で、FAT32のマイナスな点を解消しています。
②NTFS (New Technology File System)
NTFSは、Microsoftが開発した高性能ファイルシステムであり、Windows NTファミリーのOSで標準的に使用されています。1993年にリリースされたWindows NT 3.1で初めて登場し、現在はほとんどのWindowsバージョンで利用されています。
特徴:
・ディスク空間を節約するためのファイル圧縮機能があります。
アクセス制御リスト(ACL)と呼ばれる、ファイルやフォルダの詳細なアクセス権を設定できます。
・ファイルシステムレベルでの暗号化(EFS: Encrypting File System)ができます。
・システムクラッシュや電源障害からの回復を助けるための変更履歴の記録もします。
NTFSは高い信頼性とセキュリティ機能がありますが、主にWindowsでのみなのがマイナスです。
③HFS (Hierarchical File System)
HFSはAppleが開発したファイルシステムです。Mac OS 8.1以降ではHFS+(Mac OS拡張フォーマット)が登場し、機能が大幅に拡張されました。
HFS+の特徴:
・より大きなファイルサイズとボリュームサイズに対応するようになりました。
・データの整合性を保つためのジャーナリング機能があります。
HFS+は主にMacOSで使用されており、他のOSとの互換性が制限されているのがマイナスです。
④ext (Extended File System)
extは、Linux用に開発されたファイルシステムで、最初のバージョンであるextは1992年に導入されました。いろいろなバージョンがあります。
・ext2: ジャーナリングがないファイルシステムで、比較的シンプルで高速です。
・ext3: ext2の改良版で、ジャーナリング機能が追加されました。クラッシュしたときも、早い回復ができます。
ext4: ext3の拡張版です。より大きなファイルシステムとファイルサイズをサポートできるようになりました。
これらのバージョンは互換性を保っているのも特徴です。
⑤XFS
XFSは、1994年にSGI(Silicon Graphics, Inc.)が開発した高性能ファイルシステムです。特に大規模なデータセットや高スループットを必要とする用途に適しています。主にLinuxで使用されています。
特徴:
・大規模なファイルシステム操作に適しています。
・ファイルシステムの整合性を保つためのジャーナリング機能があります。
・ファイルシステムの動的な拡張が可能です。
XFSは特にNAS(Network Attached Storage)システムでよく使用されており、WindowsやMacOSから直接アクセスすることはできません。
問6-3
イメージファイルimage.ddに存在するファイルシステムをマウントしてもそのままでは通常の方法で中身を参照(マウントしたOS上でファイルをダブルクリックするなどして、ファイルのフォーマットに対応したアプリケーションで中身を表示)できないファイルが存在します。そのファイルを、マウントしたOSから通常の方法で参照できるようにしてください(※ファイルを抽出するのではなく、参照ができる状態に戻してください)。
その過程でイメージファイル内のどの部分をどのように変更したのか、なぜそれで参照できるようになるのかを簡潔に解答してください。
マウントができなかったので、解くことができませんでした。私がもし、参照できるようにするにはどのようなことを試すのか今の時点で考えられることを書かせていただきます。
<予想>
①ファイルシステムを修復してみる
fsckコマンドをつかって、ファイルシステムの修復をしてみると思います。修復をすることによって、ファイルシステムのメタデータを持っているスーパーブロックやファイルのメタデータ(所有者、パーミッション、データブロックの位置など)を持っているインデックスノードやデータブロックの修正をしてみます。
②パーミッションを確認してみる
ファイルのパーミッションを確認してみて、状況に応じてchmodコマンドをつかってパーミッションを与えてみます。
③debugfsをつかう
debugfsというデバッガをつかって、メタデータを修正してみます。ファイルシステムのジャーナリングやファイルのメタデータが破損している場合、特定のファイルが見えないことがあるので、これも1つの方法だと考えました。
問7
今後、より重要になる思われる技術(製品等でも可)の中で、あなたが攻撃の対象として興味深いと感じるものを1つ挙げ、次の設問に回答してください。すべての設問において技術的な回答を期待しています。
問7-1
選んだ技術はどんなものですか?
私は、今後より重要になると思う技術としてIoTを選び、今回はIoT機器全般について考えました。
IoT機器とは、インターネットに接続された機器を指し、身近な例では、監視カメラやウェアラブル端末やスマートロックやスマートテレビ、スマートスピーカーなどが挙げられます。日常生活以外でも医療・交通・物流といった重要インフラや製造業・農業など幅広い分野で活用されています。
問7-2
その技術が脆弱になり得るのはどんなときだと思いますか?
IoT機器には、特に下記のような弱点があると考えます。
① IoT機器を弱いデフォルトパスワードのまま使用することがある
IoT機器に弱いデフォルトパスワードが設定されており、ユーザーがそのまま使用していると、攻撃者はそれを簡単に推測できる可能性があります。
実際に過去の事例として、「Mirai」というボットネットが挙げられます。このマルウェアは、デフォルトのユーザー名とパスワードを使用してIoT機器に侵入するブルートフォース攻撃をし、感染したIoT機器でボットネットを形成してDDoS攻撃を行います。
実際に私もHachTheBoxなどでブルートフォース攻撃を実施するときには、サービスのデフォルトのパスワードや推測しやすいパスワードから試していくので、攻撃者がそれを狙う理由もよくわかります。
② IoT機器のソフトウェアに脆弱性が見つかることがある
IoT機器のソフトウェアに脆弱性が見つかったときは、攻撃者はゼロデイ攻撃やパッチが適応されていない機器を狙って攻撃すると考えます。特に多くのIoT機器で使用されるソフトウェアに脆弱性が見つかったときは、その影響は広範囲に及ぶこととなります。
③ そもそもユーザーのIoT機器に対するセキュリティ意識が低い
①と②にも関連しますが、使用するユーザーのセキュリティ意識が低い場合はIoT機器が脆弱な状態になりやすくなると思います。ファームウェアアップデートやパッチ適応を怠ってしまったり、セキュリティに対する認識不足であったりと多くの要因があります。
IoT機器のユーザーにはさまざまな人がいるため、その全員がセキュリティの意識を高めることや、またそれを継続するのは困難であると考えます。
問7-3
その技術に対して攻撃することを考えたときに、思いつく障壁は何ですか?
IoT機器のセキュリティに関する法整備や取り決めが進むと、IoT機器に対する攻撃が今より困難になると思われます。例えば、2024年4月29日から施行されたイギリスの”PSTI法"が挙げられます。この法律はIoT機器のサイバーセキュリティ対策の向上を目的としており、IoT機器メーカーに対して簡単なデフォルトパスワードの使用を禁止したりします。
これによって、弱いパスワードを狙った攻撃が成功しづらくなると考えます。
2022年に可決され、2024年の4月29日からイギリスで施行された”PSTI法"は大きな障壁になると思います。この法律はIoT機器のサイバーセキュリティ対策の向上を目的とした法律で、IoTデバイスメーカーに対して簡単なデフォルトパスワードを禁止して、デバイスごとに一意のパスワード設定やユーザー自身の設定を求めるというものです。
これによって、攻撃者はパスワードを狙った攻撃をしづらくなるほか、ユーザー自身でパスワードの設定をすることで、セキュリティの意識も高められると考えます。
このような国の法律が制定されてきたことにより、攻撃するのが困難になってくると思います。
問8
ELF ファイル "hack" について、以下の質問に解答してください。
このファイルを IDA 8 (Freeware version) でデコンパイルすると、このようなコードが出力されます。
int __fastcall main(int argc, const char **argv, const char **envp)
{
if ( !strcmp("Reversing is cool.", "Reversing is fun.") )
{
if ( !strncmp("Reversing is cool.", "Reversing is fun.", (size_t)"Reversing is fun.") )
puts("Nope.");
else
puts("Welcome to Security Camp!");
}
else
{
puts("What's wrong?");
}
return 0;
}
このコードを読むと、"What's wrong?" という文字列が表示されることが予想されますが、このプログラムを実行すると、実際に出力される文字列は以下のように異なるメッセージが表示されます。
$ ./hack
Welcome to Security Camp!
この実行ファイルに用いられているトリックについて説明してください。
また、解答に至るまでの調査方法について記述してください。
<前提>
デコンパイルされたコードを確認すると、まずはじめにstrcmp関数で2つの文字列“Reversing is fun.”と“Reversing is cool.”を比較しています。
strcmp関数は比較する2つの文字列が等しい場合に0を返しますが、今回は等しくないのでelseに飛んでWhat's wrong?という文字列が表示されることが予想されます。
<トリック>
gdb-pedaを使用して動的解析を行うために、main関数にブレークポイントを置いてから1命令ずつプログラムを実行して、動作を細かく確認をしていきます。
x86-64では、rdiレジスタに第1引数、rsiレジスタに第2引数、rdxレジスタに第3引数に指定します。
進めていくと、strcmp関数をcallする直前に第1引数の(“Reversing is cool.”)をrdiレジスタに、第2引数の(“Reversing is fun.”)をrsiレジスタに、第3引数の(0xd)がrdxレジスタに格納されていることが分かります。
RDX: 0xd ('\r')
RSI: 0x555555400907 ("Reversing is fun.")
RDI: 0x5555554008f4 ("Reversing is cool.")
/略
RIP: 0x555555400821 (<main+49>: call 0x555555400670 <strcmp@plt>)
前提と予想からですと、rdiレジスタに格納されているデータとrsiレジスタに格納されているデータでstrcmp関数を使用して2つのデータの比較を行うはずです。
実際、callを使用してstrcmp関数を呼び出しているようです。
しかし、もう1ステップ進めると
RIP: 0x7ffff7f3c170 (<__strncmp_sse42>: test rdx,rdx)
となって、strncmp関数が呼び出されています。この場合、0xdは13と同じ意味なので文字列"Reversing is fun."と"Reversing is cool."の前から13文字分の比較を行います。
どちらも前から13文字分は"Reversing is ”までになります。この場合、どちらも一致するため0を返します。strncmp関数を抜けるときには戻り値0がraxレジスタに入ります。条件分岐ifではtrueになるので、このif文の中に入ることになります。
iVar1 = strncmp("Reversing is cool.","Reversing is fun.",0x100907);
if (iVar1 == 0) {
puts("Nope.");
}
else {
puts("Welcome to Security Camp!");
}
この場合、文字列が一致しないのでelseに飛んで"Welcome to Security Camp!"が出力されるようになっています。
本来なら、どうしてstrcmpの代わりにstrncmpが呼ばれてしまったかまでわかれば良かったのですが、今の私の力ではここまでしかわかりませんでした。そのため私の予想ではありますが、どうしてそうなってしまったかを以下に書きます。
<私の予想>
①コンパイラはより効率的な関数があった場合にそちらに置き換えることがあると考えます。今回のように、比較対象の文字列が短い場合にstrncmpは一部のコンパイラでより高速に動作するので、strcmpをstrncmpに置き換えることがあると予想します。
②固定長の文字列を比較する場合にstrncmpは特定の長さまでしか比較を行わないので、strcmpよりも効率的であるので置き換わってしまったのでは?
③使用したC標準ライブラリの特定のバージョンによって、関数の呼び出しを内部で置き換えます。そのため、strcmpがstrncmpに置き換わってしまったのではないかと予想します。
コンパイルが済んでいるバイナリの解析なので、Libc共有ライブラリの中身の問題になってくるので、この中でも特に③が有力なのではないかと考えました。
おわりに
これで私の応募課題は以上です。
さっきも書いたように、問題に正解していなくても選考通過する可能性は十分にあります。熱いパッションを持って課題を書いてみてください!!
最後にtips。応募課題を出すフォームは文字と画像が一緒に貼り付けることができずに、めちゃくちゃ見えづらいです。なので、Qiitaのようなブログサイトで限定公開の記事を書いてそのリンクを解答欄に貼り付けておくのがオススメです。
(念のために文字だけの回答も解答欄に貼っておこう)