ロジスティック回帰分析ついての備忘録。(個人メモ)
ロジスティック回帰とロジットリンク関数
確率分布に二項分布(Binomial Distribution)、リンク関数にロジットリンク関数を指定した一般化線形モデル(GLM)が、ロジスティック回帰。
二項分布では、事象の発生確率 $p_i$ を指定する必要があり、$p_i$ の値の範囲 0≥$p_i$≥1 (確率なので0~100%の範囲)を表現するために適したリンク関数が、ロジットリンク関数。
ロジスティック関数
ロジットリンク関数は、ロジスティック関数の逆関数。ロジスティック関数は、以下の式で表現される。
$z_i$ は線形予測子 $z_i=α_1+β_1x_1+β_2x_2…$ ・・・α:切片 $β_i$:係数
$$ p_i=logistic(x_i)=\frac{1}{1+\exp(-z_i)} $$
ロジスティック関数を描画(シグモイドカーブ)
上記の式の $z$ を -10〜10 で変化させた時の曲線を描画してみる。
$z$ がどのような値になっても 0≥𝑝𝑖≥1 に収まっていて都合が良いこと、またz=0でp=0.5となることに着目!
# -6~6の間で等間隔に1000個の値を取得
x = np.linspace(-10,10,1000)
# 1/(1+np.exp(-x)) がロジスティック関数
plt.plot(x, ( 1/(1+np.exp(-x))) )
plt.axvline(x=0, color='red', linestyle='dotted')
plt.axhline(y=0.5, color='red', linestyle='dotted')
plt.ylabel("確率(p)")
plt.xlabel("確率変数(z)")
plt.show()
下記のようなグラフが描画される。
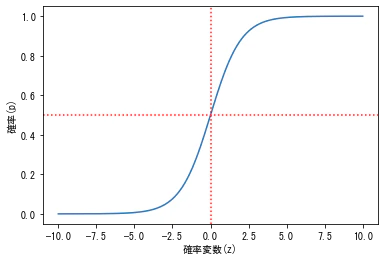
ロジットリンク関数
ロジスティック関数を $z_i$= の形に変形すると以下のようになる。
$$ \log \frac{p_i}{1-p_i}=z_i $$
※ちなみに、$z_i=α_1+β_1x_1+β_2x_2…$ ・・・α:切片 $β_i$:係数
この左辺をロジット関数という。これってつまり以下のようなこと。
$$ α_1+β_1x_1+β_2x_2… = \log \frac{p_i}{1-p_i} $$
ロジスティック回帰によるパラメータの推定
ロジスティック回帰によるパラメータの推定。
(線形結合の式(線形予測子)の切片や各係数*の推定)
尤度関数と対数尤度関数は以下で定義され、$\log L$ を最大にする推定値 $\hat{\beta_j}$ を探し出します。
$$ L(\beta_j)=\prod_i{}_n\mathrm{C}_rp_i^{y_i}(1-p_i)^{N_i-y_i} $$
両辺の対数をとると
$$ \log L({\beta_j})=\sum_i (\log {}_n \mathrm{C} _r+y_i\log(p_i)+(N_i-y_i)\log(1-p_i)) $$
実装
適当にデータを用意。
# 説明変数となるデータを1項目用意
X_train_list = np.r_[np.random.normal(3 ,1, size=50), np.random.normal(-1,1,size=50)]
# 目的変数となるデータを用意
y_train_list = np.r_[np.ones(50),np.zeros(50)]
# データフレームに変換
df = pd.DataFrame(data=[X_train_list,y_train_list]).T
df.rename(columns={0:"X",1:"Y"}, inplace=True)
# 目的変数と説明変数を分ける
X_train = df[["X"]]
y_train = df[["Y"]]
display(X_train.head())
display(y_train.head())
X
0 5.207395
1 2.692299
2 1.560036
3 3.853632
4 4.804304
Y
0 1.0
1 1.0
2 1.0
3 1.0
4 1.0
sklearn.linear_model.LogisticRegressionの場合
モデル作成
from sklearn.linear_model import LogisticRegression
# モデルのインスタンス化
model = LogisticRegression()
# 学習
model.fit(X_train,y_train)
予測(フラグ)
モデル名.predict(説明変数データ)
0と1のリストが返ってくる。デフォルトでは、閾値の0.5 (=50%)を超える場合には1、そうでない場合には0で設定されているとのこと。
引数で渡す説明変数データはDataFrameじゃないとエラーになるみたい。Serieseだとエラーになってしまった。
model.predict(X_train)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
予測(確率)
モデル名.predict_proba(説明変数データ)
array形式で、0に分類される確率、1に分類される確率の各確率が返ってくる。
model.predict_proba(X_train.iloc[0:10])
array([[2.63082246e-05, 9.99973692e-01],
[1.51340331e-02, 9.84865967e-01],
[2.12846522e-01, 7.87153478e-01],
[8.10623998e-04, 9.99189376e-01],
[7.30213967e-05, 9.99926979e-01],
[1.51565245e-02, 9.84843475e-01],
[6.95446239e-04, 9.99304554e-01],
[7.48031608e-02, 9.25196839e-01],
[1.88389023e-02, 9.81161098e-01],
[5.45899840e-04, 9.99454100e-01]])
ちなみに、1に分類される確率だけを出力する場合は、
モデル名.predict_proba(評価用の説明変数データ)[:, 1]
statsmodels.apiの場合
モデル作成
ポイントは、***sm.add_constant(説明変数データ)***をしないと、回帰式の切片が出てこないところ。
import statsmodels.api as sm
# 定数項(切片)のために行う
X_train = sm.add_constant(X_train)
glm_binom = sm.GLM( y_train, X_train, family=sm.families.Binomial())
res = glm_binom.fit()
print(res.summary())
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: Y No. Observations: 100
Model: GLM Df Residuals: 98
Model Family: Binomial Df Model: 1
Link Function: logit Scale: 1.0000
Method: IRLS Log-Likelihood: -8.8540
Date: Thu, 25 Mar 2021 Deviance: 17.708
Time: 10:54:26 Pearson chi2: 48.1
No. Iterations: 8
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const -3.1340 1.046 -2.995 0.003 -5.185 -1.083
X 3.3071 0.952 3.476 0.001 1.442 5.172
==============================================================================
予測
1に分類される確率が返ってくる。
predictする前に、引数で渡す説明変数は、***sm.add_constant(説明変数データ)***をしないとエラーになります。
モデル.predict(説明変数データ)
res.predict(X_train)
0 0.527843
1 0.999978
2 0.999281
3 0.997063
4 0.995389
...
95 0.001322
96 0.000229
97 0.004302
98 0.000940
99 0.000040
AIC(赤池情報量基準)の出力
res.aic
statsmodels.formula.apiの場合
statsmodels.apiよりも細かい指定ができるというものなのだろうか・・・
モデル作成
formulaで 目的変数と説明変数を列挙
Rのように「全体から、この列とこの列を抜く!」という指定はできないのだろうか・・・
import statsmodels.formula.api as smf
# 線形予測子を定義 「1+」は切片
formula = "Y~1+X"
# リンク関数を選択
link = sm.genmod.families.links.logit
# 誤差構造(損失関数)を選択
family = sm.families.Binomial(link=link)
mod = smf.glm(formula=formula, data=df, family=family )
result = mod.fit()
print(result.summary())
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: Y No. Observations: 100
Model: GLM Df Residuals: 98
Model Family: Binomial Df Model: 1
Link Function: logit Scale: 1.0000
Method: IRLS Log-Likelihood: -8.8540
Date: Thu, 25 Mar 2021 Deviance: 17.708
Time: 11:11:39 Pearson chi2: 48.1
No. Iterations: 8
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -3.1340 1.046 -2.995 0.003 -5.185 -1.083
X 3.3071 0.952 3.476 0.001 1.442 5.172
==============================================================================
予測
1に分類される確率が返ってくる。
predictする前に、引数で渡す説明変数は、***sm.add_constant(説明変数データ)***をしないとエラーになります。
モデル.predict(説明変数データ)
result.predict(X_train)
0 0.527843
1 0.999978
2 0.999281
3 0.997063
4 0.995389
...
95 0.001322
96 0.000229
97 0.004302
98 0.000940
99 0.000040
AIC(赤池情報量基準)の出力
result.aic
解釈
ロジット関数の線形予測子を、得られた係数の値で置き換えると、以下の式になります。
例えば、切片が -19.54 $β_1$が1.95 $β_2$が2.02 だったとすると・・・
$$ \frac{p_i}{1-p_i}=\exp(\alpha+\beta_1x_i+\beta_2f_i)=\exp(\alpha)+\exp(\beta_1x_i)+\exp(\beta_2f_i)=\exp(-19.54)+\exp(1.95x_i)+\exp(2.02f_i) $$
左辺は (事象が発生する確率)/(事象が発生しない確率) のオッズになっており、例えば$x$が1増加するとオッズ比は $exp(1.95)=7.06$ 倍になる。あくまで、オッズが7.06倍になる点に注意!
おまけ
予測結果を可視化
シグモイドカーブ描いてるね!
plt.scatter(df["X"],df["Y"])
plt.plot(df["X"],result.predict(df["X"]),"-o",linestyle='None',color="red")
plt.show()
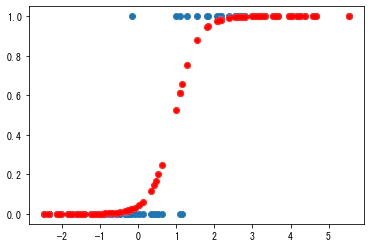
モデルの評価については、別で。
おしまい