こんにちは、な~です。ノンプロ研でPythonを学び始めました。その学びについての第5回目です。今回は、スクレイピング基礎について学びました。私にとっては、初めてのスクレイピングです。
今回の内容
- スクレイピングの基礎知識
- HTTP通信 - requestsモジュール
- HTML解析 - beautifulsoup4モジュール
スクレイピングの基礎知識
スクレイピングとは、Web上のデータを収集することを言います。
Web上で公開されている情報としてもスクレイピングを行う際には注意しなくてはならないことがあります。

相手の立場に立って節度あるスクレイピングをすることが大切そうです。
HTTP通信 - requestsモジュール
まずは、Pythonによるスクレイピングに必要な知識の1つ目、HTTP通信について学びました。
HTTP通信とは、私たちの使っているパソコンにあるブラウザと、インターネット上にあるWebサーバーとがデータをやり取りするための仕組みです。
ホームページのURLの先頭は、「HTTP」からはじまりますよね。

スクレイピングの手順としては、
1.URLにリクエストをする。
2.Webサーバーからのレスポンスを受け取る。
3.レスポンスからほしいデータを取り出す。
この手順の1と2のことをするのがrequestsモジュールです。
requestsモジュールは同梱モジュールですので、import requests モジュールをインポートするだけですぐ使えるようになります。

requestsのgetメソッドは、URLを渡してあげると、Responseオブジェクトが返ってきます。

また、レスポンスに含めれるコンテンツはtextで見ることができます。
中身は簡単に取得できますが、HTMLで書かれているため、目視で確認するのは大変ですが、この先、いろいろすることによって、必要な情報のみを取得して成形することができそうです。

レスポンスのステータスコードを確認することで、このレスポンスが正常処理で受け取れたものかの確認ができます。また、リクエストが成功しなかったらエラーを起こすことも可能です。Responseオブジェクト. raise_for_status()で、エラーが起こせたら、エラーを処理する方がフローが簡単になる場合もありますよね。
検索をしたり、値を渡して処理をするとURLに検索文字列が付加されてリクエストを送ります。この文字列をクエリ文字列と言います。

パラーメータを渡してリクエストができます。

パラメータを辞書形式の変数にして付与するとさまざまな情報を取得できるようになりますね。
HTML解析 - beautifulsoup4モジュール
requestsモジュールで、Web上の必要なレスポンスが取得できましたので、レスポンスから欲しいデータを取り出します。
レスポンス(HTML)から欲しいデータを取り出す解析をするのがbeautifulsoup4モジュールです。
HTMLとは、HyperText Markup Language=Webページを記述するためのマークアップ言語です。「タグを」使って「マーク」をつけます。

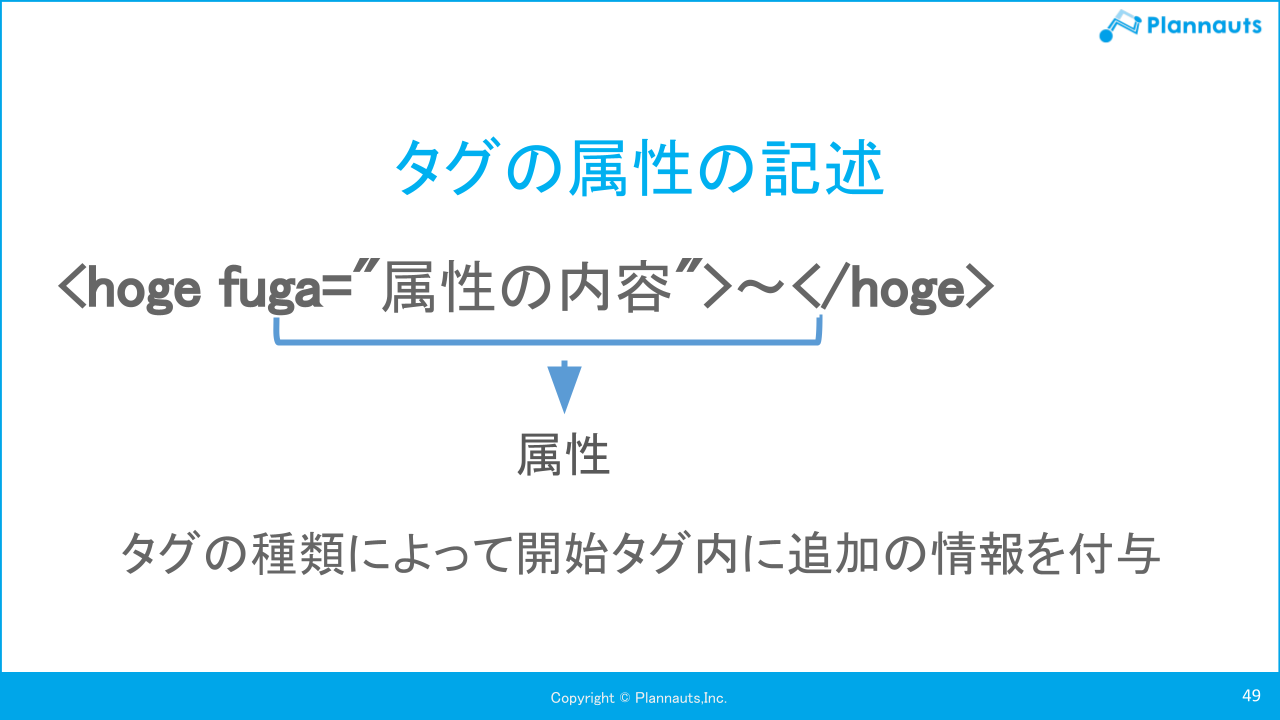
ブラウザは、HTMLドキュメントを解析・変換してWebページとして表示するソフトウェアです。レスポンスの内容を目視でみて理解するのは大変、そこで登場するのが、beautifulsoup4モジュールです。
こちらも、モジュールをインポートして利用します。モジュール名が長いのでbs4に省略して利用できます。

html.parserというHTMLの構文解析を行うツールを利用してBeautifulSoupオブジェクトを生成します。
BeautifulSoupオブジェクトは、ドキュメント全体のツリー構造を表します。
findメソッドやfind_allメソッド、sekectメソッドを利用して必要なTagオブジェクトを抽出して利用できます。
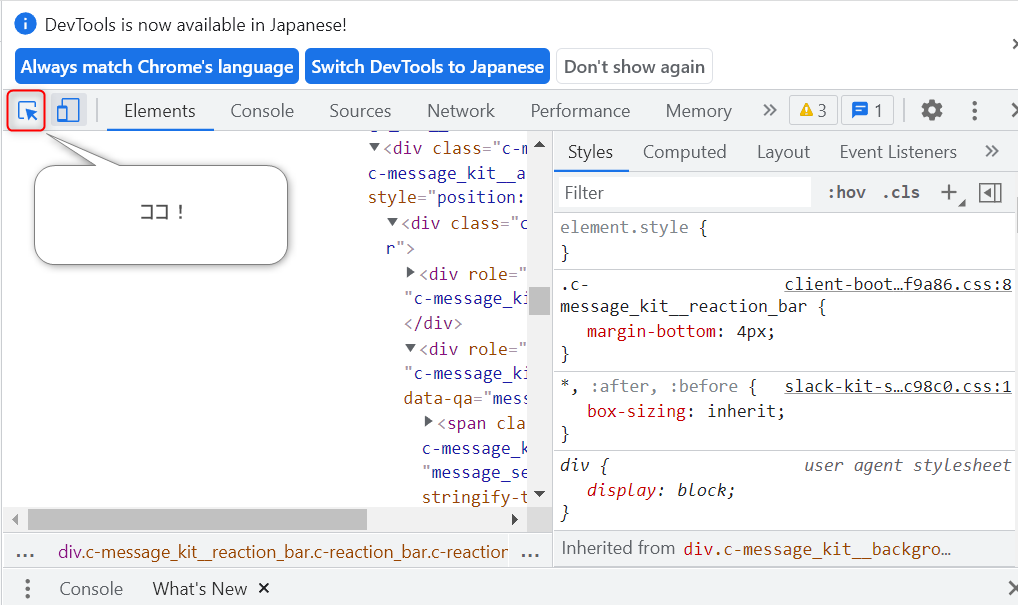
Chromeのデベロッパーツールを使って、要素を探す方法を学びました。
ブラウザで、ショートカットCtrl + Shift + Iで、デベロッパーツールがひらきます。画像にある要素を選択アイコンをクリックして、欲しい要素をクリックして選択します。Elementsタブで内容を確認して、必要な情報にたどり着くよう検索したり、たどったりします。必要な情報を取得できるタグやクラスを探しましょう!
まとめ
今回は、スクレイピング基礎について学びました。初めてのスクレイピングが無事できました。
講座のあと、会社のブログのaタグを取得するコードを書いて無事にURLやタイトルの一覧が取得できました。
次回は、スクレイピング実践ということで、もっといろいろなことを学べそうです。
今回もツイートまとめました!
ノンプロ研 Python初心者講座第5回目 byな~