Aidemyのデータ分析講座を受けた機械学習初学者が初めてゼロから機械学習に取り組んでみました。
はじめに
はじめまして。
インフラおよび業務アプリ系のエンジニアを経験した後、広告代理店に転職し、今は専らデータ分析基盤の構築と運用(主にBigQuery+Looker)をやっています。
40歳を過ぎて自身のスキルレベルに危機感を感じて、独学ではなく体系的に学べる講座を受けようと思いAidemyのデータ分析講座を受講しました。
Aidemyデータ分析講座
働きながらだったので平日残業学習に割ける時間がなかなか取れないと思い6ヵ月コースを受講しました。
学んだこと
機械学習で活用するPythonの初級~中級までの知識や機械学習の概論から、教師あり/なし学習、ディープラーニングのモデル構築や評価方法などを体系的に学ぶことができました。
これまで、Pythonはインターネット上のサンプルコードを参考にさせていただくことがほとんどでしたが、基本文法から応用的な記法を学べることで基礎力UPになったと感じています。
また機械学習についても、具体的にどういう手順でデータを準備して、機械学習モデルを構築し、モデル評価を行うのかの一連の流れを知ることで理解を深めることができました。
分析テーマ
普段から業務で広告データに振れる機会が多いので、今回広告施策と売上の相関性を分析して、売上貢献度の高い広告媒体がどれかを特定するモデルを構築したいと思います。
ただ、単純に線形回帰モデルを構築するだけでは自分自身に納得がいかないので、複数のモデルを試し性能がいいモデルで最終的な分析を行えるようにしたいと思います。
データ
実データを利用しようと考えましたが、記事公開をするには調整事項が多くなるので、今回はKaggleで公開されている「Product Advertising Data」を利用します。
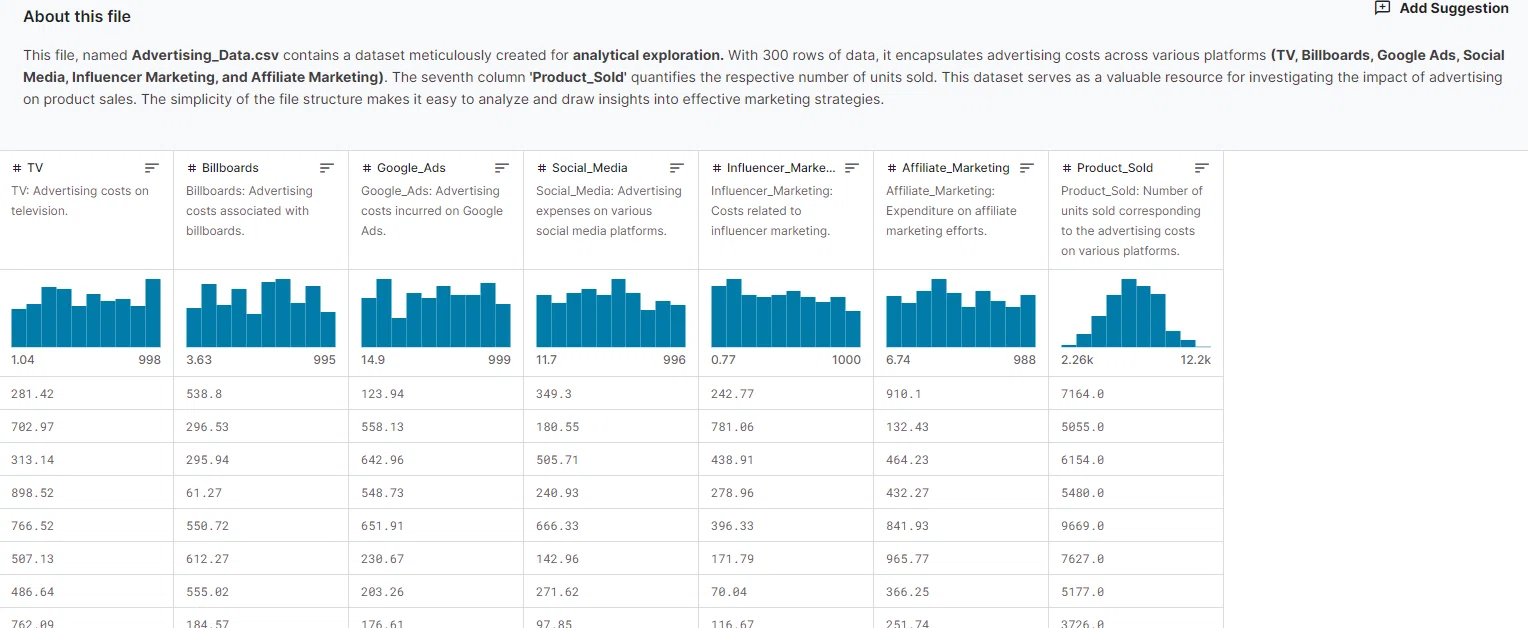
こちらのデータは「テレビ、OOH、Google広告、ソーシャルメディア、インフルエン、アフィリエイト」の6つの広告施策のコスト(説明変数)と「販売価格」(目的変数)から成り立っているシンプルなデータです。
実装
実行環境
Kaggleの公開データを利用するので、今回はKaggle Notebookで実装していきます。
公開データのDatasetからNotebookを作成するとデータ展開用の下記コードが用意されているのでそのまま実行します。
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
※コメントは割愛
分析ステップ
下記のステップで進めていきます。
- データの読み込みと確認
- データの前処理
- データの分割
- モデルの定義
- モデルのトレーニングと性能評価
- 最適なモデルで売上貢献度を分析
Step1: データの読み込みと確認
まずファイルを読み込みデータを確認します。
# データの読み込み
file_path = '/kaggle/input/product-advertising-data/Advertising_Data.csv'
data = pd.read_csv(file_path)
# データの確認
data.head(), data.info()

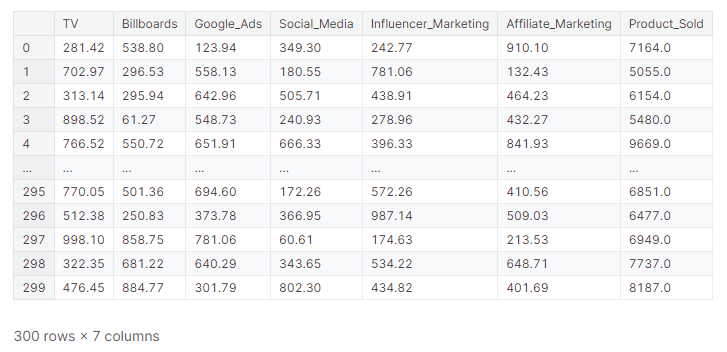
前述の通り7カラム(6つの広告施策(説明変数)と1つの売上(目的変数)から成り立つ)×300レコードあります。
日付などの時系列情報はありません。
機械学習では「データの前処理」が重要ですので、読み込んだデータから必要な前処理を行っていきます。
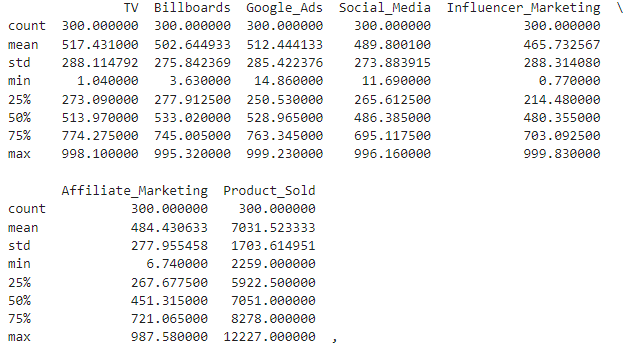
まず、データの大枠を把握するため記述統計量を見ていきます。
data.describe()
Step2: データの前処理
今回のデータでは主に4つの観点で確認し、前処理の必要性を判断します。
欠損値の確認
全部で300行のレコードに対して、すべてのカラムでcount:300なので欠損値はありません。
外れ値の確認
こちらは記述統計量だけでは判断が難しいので箱ひげ図を使って外れ値の有無を確認します。
箱ひげ図を作るのにseabornライブラリを利用します。
import matplotlib.pyplot as plt
import seaborn as sns
# 各説明変数の分布を確認
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
sns.boxplot(y=data['TV'], ax=axes[0, 0])
axes[0, 0].set_title('TV')
sns.boxplot(y=data['Billboards'], ax=axes[0, 1])
axes[0, 1].set_title('Billboards')
sns.boxplot(y=data['Google_Ads'], ax=axes[0, 2])
axes[0, 2].set_title('Google_Ads')
sns.boxplot(y=data['Social_Media'], ax=axes[1, 0])
axes[1, 0].set_title('Social_Media')
sns.boxplot(y=data['Influencer_Marketing'], ax=axes[1, 1])
axes[1, 1].set_title('Influencer_Marketing')
sns.boxplot(y=data['Affiliate_Marketing'], ax=axes[1, 2])
axes[1, 2].set_title('Affiliate_Marketing')
plt.tight_layout()
plt.show()
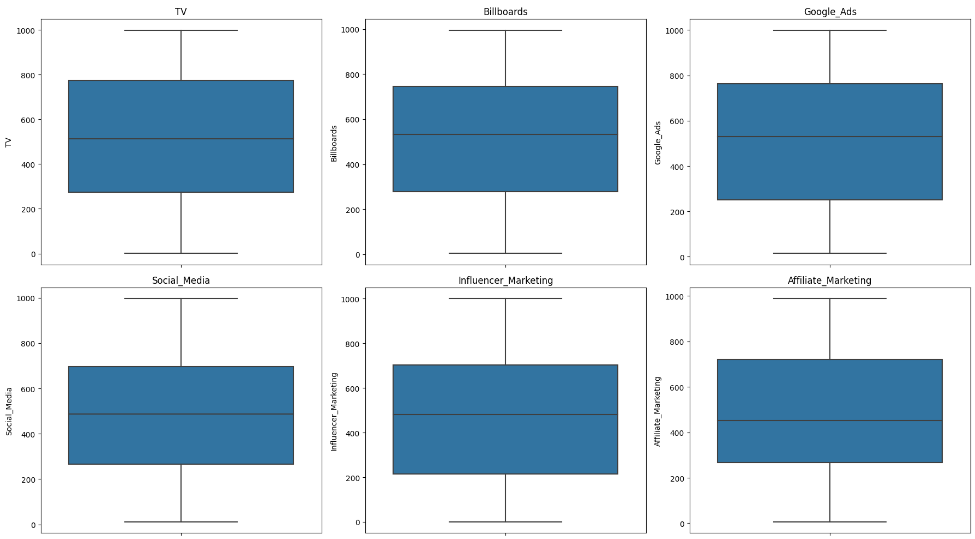
可視化したところ外れ値はないので、こちらも前処理不要で進めます。
カテゴライズデータの有無
今回は全て数値データなのでカテゴライズデータはないのでこちらもスルーします
データの範囲
また6つの説明変数については0~1000の間に収まるように見えますがスケール調整処理は念のため実装します。
データのスケール調整にはscikit-learnのStandardScalerを利用します。
from sklearn.preprocessing import StandardScaler
# 必要なカラムの抽出
X = data[['TV', 'Billboards', 'Google_Ads', 'Social_Media', 'Influencer_Marketing', 'Affiliate_Marketing']]
y = data['Product_Sold']
# データのスケーリング
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
Step3: データの分割
元のデータをトレーニング用データと検証用データに分けます。
データ分割方法としてホールドアウト法とクロスバリデーション(k分割公差検証)などいくつかありますが、今回はホールドアウト法で分割します。(トレーニング:0.8、テスト:0.2で分割)
from sklearn.model_selection import train_test_split
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
Step4: モデルの定義
今回は一度に複数の回帰モデルのトレーニングと性能評価を行います。
使う回帰モデルは下記の4つ
・線形回帰
・ラッソ回帰
・エッジ回帰
・ElasticNet回帰
必要なライブラリをインポートし、for文で連続した処理をするため4つのモデルインスタンスを辞書に格納します。
# モデルと性能評価指標ライブラリのインポート
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.metrics import mean_squared_error, r2_score
models = {
'Linear Regression': LinearRegression(),
'Ridge Regression': Ridge(),
'Lasso Regression': Lasso(),
'ElasticNet Regression': ElasticNet()
}
Step5: モデルのトレーニングと性能評価
各モデルをトレーニングし、それぞれ性能評価を行い、高性能のモデルを探っていきます。
性能評価には回帰タスクでの性能評価指標としてMSEと決定係数R^2の2つを用います。
それぞれの簡単な説明を記述しておきます。
MSE(MeanSpuaredError):残差の二乗の平均を表し、MSEが小さいほど性能が良い
決定係数R^2(Rの2乗):予測データと正解データがどのくらい一致しているかを示す指標。おおよそ0.8以上の数値であれば精度が良いと判断される
# 評価結果の格納用
results = {}
# 各モデルのトレーニングと評価
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
results[name] = {'MSE': mse, 'R2': r2}
results_df = pd.DataFrame(results).T
results_df
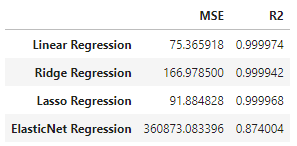
出力結果を見ると、MSEが小さく、かつR2が高いモデルは線形回帰モデル「Linear Regression」となり、対して「ElasticNet回帰」は他のモデルに比べて明らかに性能が低い結果となりました。
Step6: 最適なモデルで売上貢献度を分析
先ほどの結果から、線形回帰モデル「Linear Regression」が最適モデルということが分かったので、これを使って各説明変数の係数を取得し、売上貢献度を可視化します。
各説明変数の係数はmodel.coef_で取得します。
# 線形回帰モデルの再トレーニング
best_model = LinearRegression()
best_model.fit(X_train, y_train)
# 各説明変数の係数を取得
coefficients = pd.Series(best_model.coef_, index=X.columns)
# プロット
plt.figure(figsize=(10, 6))
coefficients.sort_values().plot(kind='barh')
plt.title('Sales contribution of ad medium')
plt.xlabel('Sales contribution')
plt.ylabel('Advertising')
plt.show()
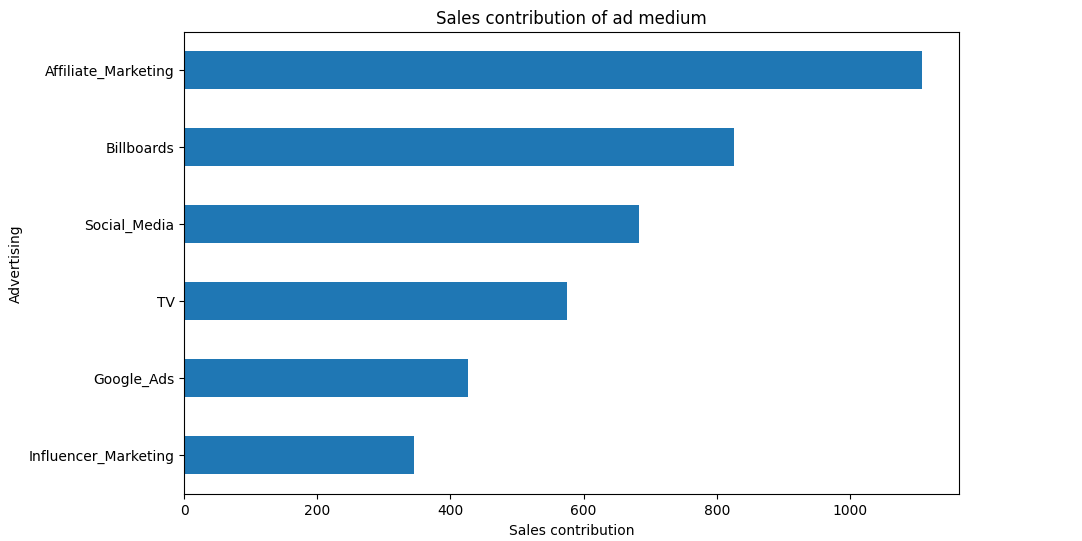
このグラフにより、どの広告施策が売上にどれだけ影響を与えているかが一目で分かります。特に Affiliate Marketing と Billboards の貢献度が高いことが視覚的に確認できます。
考察
広告運用サービスに身を置く立場としては、なんとなくTVCMやGoogle広告が貢献度高いだろうなという想定に反した結果が出たので驚きでした。
今回使ったのはサンプルデータなので意図してそういうデータを作られた背景もあるかもですが、各広告施策に対するバイアスを裏切った結果が出たことで、感覚値や印象で判断することのリスクを改め感じることができました。
今後について
今回チャレンジした広告貢献度の分析は、まだまだ不十分な内容で、広告貢献度の分析には「トレンド」「競合や市場などの外部要因」(業界によっては天候など)といったデータも加味しなければ正しい貢献度を導き出すことはできないと思っています。
ここ数年、マーケティング業界では「MMM(マーケティング・ミックス・モデリング)」という統計分析手法が注目されています。
上記のような外部データを加味するだけでなく、各広告施策の「ラグ効果」や「飽和効果」を導入した「AdStock」モデルも組込んだうえで、今回チャレンジした回帰モデルに渡すという、さらに複雑な内容の実装が必要そうです。
次はもう少し時間を使ってMMMモデルの構築と、実際の広告データでの貢献度評価に取り組んでみようと思います。
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。