はじめに
久々の投稿です。
以前よりもC++の力が(多少)身に付いたので、今回は"日本語であそぼ"と思います。
動詞のデータから五段活用を出力していきます。
五段活用って何?
活用語尾が五十音図の五つの段すべてにわたって変化します。このような動詞の活用のしかたを五段活用ごだんかつようと言います。
(引用: 動詞(4)五段活用・音便)
あれですあれ。
未然形、連用形、終止形、連体形、仮定形、命令形のやつです。
中学時代にやりました。懐かしいですよね。
コード
verb.cpp
#include <cstdio>
#include <string>
#include <array>
#include <vector>
#include <cstdint>
#include <cuchar>
#include <codecvt>
using std::u32string;
using std::vector;
using std::array;
using std::string;
using std::wstring;
using std::size_t;
using std::wstring_convert;
using std::codecvt_utf8_utf16;
using c16 = char16_t;
using c32 = char32_t;
using u8 = uint8_t;
using u16 = uint16_t;
using u32 = uint32_t;
using i32 = int32_t;
constexpr u8 VERB_GROUP_U = 1;
constexpr u8 VERB_GROUP_RU = 2;
constexpr u8 VERB_GROUP_SURU = 3;
constexpr u8 VERB_GROUP_KURU = 4;
constexpr u8 VERB_GROUP_KURU2 = 5;
constexpr u8 VERB_U = 1;
constexpr u8 VERB_KU = 2;
constexpr u8 VERB_SU = 3;
constexpr u8 VERB_TU = 4;
constexpr u8 VERB_NU = 5;
constexpr u8 VERB_HU = 6;
constexpr u8 VERB_MU = 7;
constexpr u8 VERB_YU = 8;
constexpr u8 VERB_RU = 9;
constexpr u8 VERB_WU = 10;
constexpr u8 VERB_GU = 11;
constexpr u8 VERB_ZU = 12;
constexpr u8 VERB_DU = 13;
constexpr u8 VERB_BU = 14;
constexpr u8 VERB_PU = 15;
constexpr u8 VERB_JU = 16;
constexpr u8 VERB_VU = 17;
constexpr u8 VERB_MODE_MIZEN = 1;
constexpr u8 VERB_MODE_RENYOU = 2;
constexpr u8 VERB_MODE_SYUUSHI = 3;
constexpr u8 VERB_MODE_RENTAI = 4;
constexpr u8 VERB_MODE_KATEI = 5;
constexpr u8 VERB_MODE_MEIREI = 6;
constexpr u8 VERB_MODE_MIZEN2 = 7;
class DouShi {
private:
u32string prototype = U"";
u8 group = 0;
u8 end = VERB_RU;
array<u32string, 8> mode_str = {};
u32string all_mode_str = U"";
public:
DouShi(const u32string& add_prototype, const u8 add_group, const u8 add_end = VERB_RU);
u32string mode(const u8 mode_id = VERB_MODE_SYUUSHI);
u32string allMode();
u32string allModeStr();
};
inline u32string DouShi::allModeStr()
{
return all_mode_str;
}
inline u32string DouShi::allMode()
{
u32string str = U"";
for (u8 i = 1; i < 8; i++) {
str += mode(i);
str += U" ";
}
return str;
}
inline DouShi::DouShi(const u32string& add_prototype, const u8 add_group, const u8 add_end)
{
prototype = add_prototype;
group = add_group;
end = add_end;
for (u8 i = 1; i < 8; i++) {
mode_str[i] = mode(i);
}
all_mode_str = allMode();
}
inline u32string DouShi::mode(const u8 mode_id)
{
//switch (mode_id)
//{
//case VERB_MODE_MIZEN:break;
//case VERB_MODE_RENYOU:break;
//case VERB_MODE_SYUUSHI:break;
//case VERB_MODE_RENTAI:break;
//case VERB_MODE_KATEI:break;
//case VERB_MODE_MEIREI:break;
//}
u32string str = prototype;
switch (group) {
case VERB_GROUP_KURU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'来'; break;
case VERB_MODE_RENYOU:str += U'来'; break;
case VERB_MODE_SYUUSHI:str += U"来る"; break;
case VERB_MODE_RENTAI:str += U"来る"; break;
case VERB_MODE_KATEI:str += U"来れ"; break;
case VERB_MODE_MEIREI:str += U"来い"; break;
case VERB_MODE_MIZEN2:str += U"来よ"; break;
}
break;
case VERB_GROUP_KURU2:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'こ'; break;
case VERB_MODE_RENYOU:str += U'き'; break;
case VERB_MODE_SYUUSHI:str += U"くる"; break;
case VERB_MODE_RENTAI:str += U"くる"; break;
case VERB_MODE_KATEI:str += U"くれ"; break;
case VERB_MODE_MEIREI:str += U"こい"; break;
case VERB_MODE_MIZEN2:str += U"こよ"; break;
}
break;
case VERB_GROUP_SURU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'し'; break;
case VERB_MODE_RENYOU:str += U'し'; break;
case VERB_MODE_SYUUSHI:str += U"する"; break;
case VERB_MODE_RENTAI:str += U"する"; break;
case VERB_MODE_KATEI:str += U"すれ"; break;
case VERB_MODE_MEIREI:str += U"しろ"; break;
case VERB_MODE_MIZEN2:str += U"しよ"; break;
}
break;
case VERB_GROUP_RU:
switch (mode_id)
{
case VERB_MODE_SYUUSHI:str += U'る'; break;
case VERB_MODE_RENTAI:str += U'る'; break;
case VERB_MODE_KATEI:str += U'れ'; break;
case VERB_MODE_MEIREI:str += U'ろ'; break;
case VERB_MODE_MIZEN2:str += U'よ'; break;
}
break;
case VERB_GROUP_U:
switch (end)
{
case VERB_U:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'あ'; break;
case VERB_MODE_RENYOU:str += U'い'; break;
case VERB_MODE_SYUUSHI:str += U'う'; break;
case VERB_MODE_RENTAI:str += U'う'; break;
case VERB_MODE_KATEI:str += U'え'; break;
case VERB_MODE_MEIREI:str += U'え'; break;
case VERB_MODE_MIZEN2:str += U'お'; break;
}break;
case VERB_KU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'か'; break;
case VERB_MODE_RENYOU:str += U'き'; break;
case VERB_MODE_SYUUSHI:str += U'く'; break;
case VERB_MODE_RENTAI:str += U'く'; break;
case VERB_MODE_KATEI:str += U'け'; break;
case VERB_MODE_MEIREI:str += U'け'; break;
case VERB_MODE_MIZEN2:str += U'こ'; break;
}break;
case VERB_SU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'さ'; break;
case VERB_MODE_RENYOU:str += U'し'; break;
case VERB_MODE_SYUUSHI:str += U'す'; break;
case VERB_MODE_RENTAI:str += U'す'; break;
case VERB_MODE_KATEI:str += U'せ'; break;
case VERB_MODE_MEIREI:str += U'せ'; break;
case VERB_MODE_MIZEN2:str += U'そ'; break;
}break;
case VERB_TU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'た'; break;
case VERB_MODE_RENYOU:str += U'ち'; break;
case VERB_MODE_SYUUSHI:str += U'つ'; break;
case VERB_MODE_RENTAI:str += U'つ'; break;
case VERB_MODE_KATEI:str += U'て'; break;
case VERB_MODE_MEIREI:str += U'て'; break;
case VERB_MODE_MIZEN2:str += U'と'; break;
}break;
case VERB_NU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'な'; break;
case VERB_MODE_RENYOU:str += U'に'; break;
case VERB_MODE_SYUUSHI:str += U'ぬ'; break;
case VERB_MODE_RENTAI:str += U'ぬ'; break;
case VERB_MODE_KATEI:str += U'ね'; break;
case VERB_MODE_MEIREI:str += U'ね'; break;
case VERB_MODE_MIZEN2:str += U'の'; break;
}break;
case VERB_HU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'は'; break;
case VERB_MODE_RENYOU:str += U'ひ'; break;
case VERB_MODE_SYUUSHI:str += U'ふ'; break;
case VERB_MODE_RENTAI:str += U'ふ'; break;
case VERB_MODE_KATEI:str += U'へ'; break;
case VERB_MODE_MEIREI:str += U'へ'; break;
case VERB_MODE_MIZEN2:str += U'ほ'; break;
}break;
case VERB_MU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'ま'; break;
case VERB_MODE_RENYOU:str += U'み'; break;
case VERB_MODE_SYUUSHI:str += U'む'; break;
case VERB_MODE_RENTAI:str += U'む'; break;
case VERB_MODE_KATEI:str += U'め'; break;
case VERB_MODE_MEIREI:str += U'め'; break;
case VERB_MODE_MIZEN2:str += U'も'; break;
}break;
case VERB_YU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'や'; break;
case VERB_MODE_RENYOU:str += U'い'; break;
case VERB_MODE_SYUUSHI:str += U'ゆ'; break;
case VERB_MODE_RENTAI:str += U'ゆ'; break;
case VERB_MODE_KATEI:str += U'え'; break;
case VERB_MODE_MEIREI:str += U'え'; break;
case VERB_MODE_MIZEN2:str += U'よ'; break;
}break;
case VERB_RU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'ら'; break;
case VERB_MODE_RENYOU:str += U'り'; break;
case VERB_MODE_SYUUSHI:str += U'る'; break;
case VERB_MODE_RENTAI:str += U'る'; break;
case VERB_MODE_KATEI:str += U'れ'; break;
case VERB_MODE_MEIREI:str += U'れ'; break;
case VERB_MODE_MIZEN2:str += U'ろ'; break;
}break;
case VERB_WU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'わ'; break;
case VERB_MODE_RENYOU:str += U'い'; break;
case VERB_MODE_SYUUSHI:str += U'う'; break;
case VERB_MODE_RENTAI:str += U'う'; break;
case VERB_MODE_KATEI:str += U'え'; break;
case VERB_MODE_MEIREI:str += U'え'; break;
case VERB_MODE_MIZEN2:str += U'お'; break;
}break;
case VERB_GU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'が'; break;
case VERB_MODE_RENYOU:str += U'ぎ'; break;
case VERB_MODE_SYUUSHI:str += U'ぐ'; break;
case VERB_MODE_RENTAI:str += U'ぐ'; break;
case VERB_MODE_KATEI:str += U'げ'; break;
case VERB_MODE_MEIREI:str += U'げ'; break;
case VERB_MODE_MIZEN2:str += U'ご'; break;
}break;
case VERB_ZU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'ざ'; break;
case VERB_MODE_RENYOU:str += U'じ'; break;
case VERB_MODE_SYUUSHI:str += U'ず'; break;
case VERB_MODE_RENTAI:str += U'ず'; break;
case VERB_MODE_KATEI:str += U'ぜ'; break;
case VERB_MODE_MEIREI:str += U'ぜ'; break;
case VERB_MODE_MIZEN2:str += U'ぞ'; break;
}break;
case VERB_DU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'だ'; break;
case VERB_MODE_RENYOU:str += U'ぢ'; break;
case VERB_MODE_SYUUSHI:str += U'づ'; break;
case VERB_MODE_RENTAI:str += U'づ'; break;
case VERB_MODE_KATEI:str += U'で'; break;
case VERB_MODE_MEIREI:str += U'で'; break;
case VERB_MODE_MIZEN2:str += U'ど'; break;
}break;
case VERB_BU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'ば'; break;
case VERB_MODE_RENYOU:str += U'び'; break;
case VERB_MODE_SYUUSHI:str += U'ぶ'; break;
case VERB_MODE_RENTAI:str += U'ぶ'; break;
case VERB_MODE_KATEI:str += U'べ'; break;
case VERB_MODE_MEIREI:str += U'べ'; break;
case VERB_MODE_MIZEN2:str += U'ぼ'; break;
}break;
case VERB_PU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U'ぱ'; break;
case VERB_MODE_RENYOU:str += U'ぴ'; break;
case VERB_MODE_SYUUSHI:str += U'ぷ'; break;
case VERB_MODE_RENTAI:str += U'ぷ'; break;
case VERB_MODE_KATEI:str += U'ぺ'; break;
case VERB_MODE_MEIREI:str += U'ぺ'; break;
case VERB_MODE_MIZEN2:str += U'ぽ'; break;
}break;
case VERB_JU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U"じゃ"; break;
case VERB_MODE_RENYOU:str += U"じぃ"; break;
case VERB_MODE_SYUUSHI:str += U"じゅ"; break;
case VERB_MODE_RENTAI:str += U"じゅ"; break;
case VERB_MODE_KATEI:str += U"じぇ"; break;
case VERB_MODE_MEIREI:str += U"じぇ"; break;
case VERB_MODE_MIZEN2:str += U"じょ"; break;
}break;
case VERB_VU:
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U"ヴぁ"; break;
case VERB_MODE_RENYOU:str += U"ヴぃ"; break;
case VERB_MODE_SYUUSHI:str += U"ヴ"; break;
case VERB_MODE_RENTAI:str += U"ヴ"; break;
case VERB_MODE_KATEI:str += U"ヴぇ"; break;
case VERB_MODE_MEIREI:str += U"ヴぇ"; break;
case VERB_MODE_MIZEN2:str += U"ヴぉ"; break;
}break;
}
break;
}
switch (mode_id)
{
case VERB_MODE_MIZEN:str += U"ない"; break;
case VERB_MODE_RENYOU:str += U"ます"; break;
case VERB_MODE_RENTAI:str += U"とき"; break;
case VERB_MODE_KATEI:str += U"ば"; break;
case VERB_MODE_MIZEN2:str += U"う"; break;
}
return str;
}
inline string wide_to_shiftjis(const wstring& src)
{
size_t conv_ed = 0;
vector<char> str(src.size() * sizeof(wchar_t) + 1, '\0');
::_wcstombs_s_l(&conv_ed, str.data(), str.size(), src.data(), _TRUNCATE, ::_create_locale(LC_ALL, "jpn"));
return string(str.begin(), str.end());
}
inline wstring utf8_to_wide(const string& src)
{
wstring_convert<codecvt_utf8_utf16<wchar_t>> conv;
return conv.from_bytes(src);
}
inline string utf8_to_shiftjis(const string& src)
{
return wide_to_shiftjis(utf8_to_wide(src));
}
void addDouShi(vector<DouShi>& douShi, const u32string& add_prototype, const u8 add_group, const u8 add_end = VERB_RU)
{
DouShi add_douShi(add_prototype, add_group, add_end);
douShi.emplace_back(add_douShi);
return;
}
int main()
{
vector<DouShi> douShi;
addDouShi(douShi, U"働", VERB_GROUP_U, VERB_KU);
addDouShi(douShi, U"休", VERB_GROUP_U, VERB_MU);
addDouShi(douShi, U"食べ", VERB_GROUP_RU);
addDouShi(douShi, U"寝", VERB_GROUP_RU);
addDouShi(douShi, U"起き", VERB_GROUP_RU);
addDouShi(douShi, U"見", VERB_GROUP_RU);
addDouShi(douShi, U"あげ", VERB_GROUP_RU);
addDouShi(douShi, U"わか", VERB_GROUP_U, VERB_RU);
addDouShi(douShi, U"ググ", VERB_GROUP_U, VERB_RU);
addDouShi(douShi, U"マミ", VERB_GROUP_U, VERB_RU);
addDouShi(douShi, U"ディス", VERB_GROUP_U, VERB_RU);
addDouShi(douShi, U"", VERB_GROUP_SURU);
addDouShi(douShi, U"", VERB_GROUP_KURU);
addDouShi(douShi, U"", VERB_GROUP_KURU2);
addDouShi(douShi, U"勉強", VERB_GROUP_SURU);
addDouShi(douShi, U"切", VERB_GROUP_U, VERB_RU);
string u8str = "";
u32string u32str = U"";
mbstate_t st = {};
char out[5] = {};
i32 rc;
for (DouShi i : douShi) {
u32str = i.allModeStr();
for (i32 j = 0; j < INT32_MAX; j++) {
if (u32str[j] == 0) break;
for (i32 k = 0; k < 4; k++) out[k] = 0;
st = {};
rc = c32rtomb(out, u32str[j], &st);
if (rc > 0) u8str += out;
}
//printf("%s\n", u8str.c_str());
printf("%s\n", utf8_to_shiftjis(u8str).c_str());
u8str = "";
}
printf("\n");
return 0;
}
結果
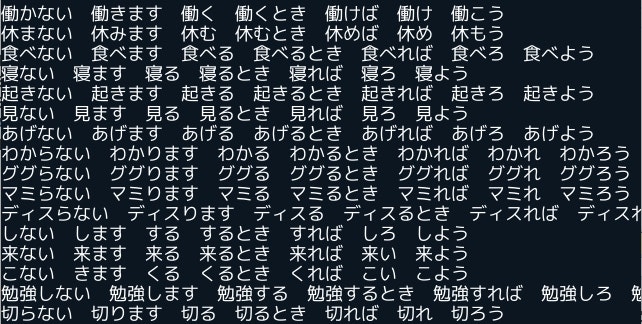
特に不自然なところもないし、いい感じに仕上がりました!
さいごに
最後までお読みいただきありがとうございました。
「いいね!」していただけると、とても励みになります。
"日本語文法 動詞の五段活用"いかがでしたでしょうか?
より良い方法がありましたらコメント頂けると幸いです。
"日本語文法 動詞の五段活用"でした。
ソースコードのライセンス
These codes are licensed under CC0.

ソースコードは自由に使用してください。