目次
はじめに
この記事は 限界開発鯖 Advent Calendar 2022 - 21日目の記事です。
11月30日にOpenAIから会話形式でやり取りする言語モデルChatGPTがプレビュー公開されました。ChatGPTは同組織からリリースされたGPTに対して、出力された文章を人間がフィードバックして報酬を与える強化学習を取り入れてより自然な文章を生成することができるようになりました。
今回はそのChatGPTの元になったGPTを用いて文章生成ボットを作成しました。
実行環境
- Windows 11 21H2
- Python 3.10.8
- transformers 4.25.1
- sentencepiece 0.1.97
- torch 1.13.0+cu117
- py-cord 2.2.2
GPTで文を生成
今回はHugging Faceからrinna/japanese-gpt2-mediumを利用します。Transformerは自然言語処理を初め様々なディープラーニングモデルが公開されています。Transformerと、バックエンドとしてPyTorchやTensorFlowをインストールすることで動作します。
import sys
from transformers import T5Tokenizer, AutoModelForCausalLM
def main():
text = sys.argv[1] # コマンドライン引数から生成文の書き出し文を取得
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium").cuda()
input_ids = tokenizer.encode(text, return_tensors="pt").cuda()[:, :-1]
output_ids = model.generate(
input_ids,
do_sample=True, # サーチにサンプリングを利用するか
num_beams=5, # ビームサーチの深さ
max_new_tokens=500, # 生成するトークン数の上限
repetition_penalty=5.0, # 文章がループすることに対するペナルティ
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
remove_invalid_values=True # 生成メソッドのクラッシュを防ぐ
)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=False)
print(output_text)
if __name__ == "__main__":
main()
このコードで出力された文章をいくつか見てみました。
おはようございます。今日の天気をお知らせします。晴れのち曇り、気温は23°Cです。今日も一日頑張っていきましょう!pic.twitter.com/vxwyqk9dzh
Discordボット化
今回はPycordでDiscordのBotとして利用してみます。Bot化するために今回はPycordを利用しました。
nlp.cog.py
from discord.commands import SlashCommandGroup
from discord.ext import commands
from transformers import T5Tokenizer, AutoModelForCausalLM
class NLPCog(commands.Cog):
slash = SlashCommandGroup('vnlp', guild_ids=[GUILD_ID1, GUILD_ID2])
def __init__(self, bot):
self.bot = bot
self.tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
self.model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium").cuda()
@slash.command()
async def generate(self, ctx: commands.Context, text: str) -> None:
'''文章生成'''
if len(text) == 0:
await ctx.send("生成する初めのテキストを入力してね")
return
await ctx.defer()
input_ids = self.tokenizer.encode(text, return_tensors="pt").cuda()[:, :-1]
output_ids = self.model.generate(
input_ids,
do_sample=True,
num_beams=5,
max_new_tokens=500,
repetition_penalty=5.0,
eos_token_id=self.tokenizer.eos_token_id,
pad_token_id=self.tokenizer.pad_token_id,
remove_invalid_values=True
)
output_text = self.tokenizer.decode(output_ids[0], skip_special_tokens=False)
await ctx.respond(output_text)
nlp_cog.pyをインポートして実際に実行するコードは以下の通りです。
main.py
import discord
import yaml
from cogs import (
NLPCog,
HogeCog
)
def main():
bot = discord.Bot()
@bot.event
async def on_ready():
print(f"{bot.user}としてログインしました!")
@bot.slash_command(guild_ids=[GUILD_ID1, GUILD_ID2])
async def ping(ctx):
await ctx.respond(f"pong {round(bot.latency, 2)}ms")
bot.add_cog(NLPCog(bot))
bot.add_cog(HogeCog(bot))
with open('config.yml', 'r') as f:
cfg = yaml.safe_load(f)
bot.run(cfg['TOKEN'])
if __name__ == '__main__':
main()
出力結果
今回は試しに「家系ラーメンとは、」を引数にしてその続きの文を生成させてみました。その結果は以下の通りです。
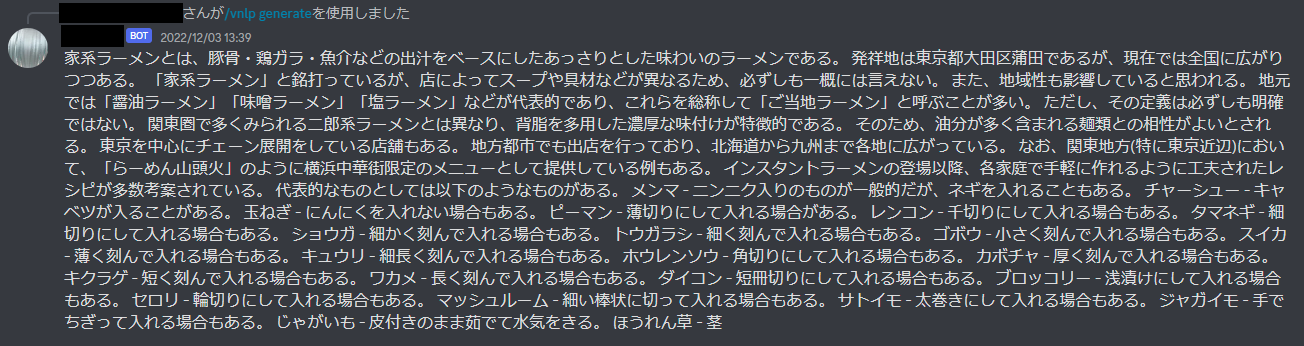
合っているようで合っていないですね。文の後半ではとにかくいろんな具材をラーメンに入れたがりますね...
まとめ
今回はGPTを使った文章生成Botを作成してみました。使用する言語モデルを変更したり、入力文を少し変えることで出力のバリエーションはかなり変わります。ここが言語モデルの難しさであり面白さでもあると思っています。