概要
Visual StudioとPythonでWebスクレイピングを入門してみる を発展させて、
1分毎にYahooリアルタイム検索を取得してファイルに保存してみます。
今回の学習ネタは、以下です。
- 定期実行する
- ファイル保存する
以下のライブラリを使います。
Schedule 1.2.1
1.定期実行
Scheduleライブラリをインストールする
検索フィールドに「Schedule」を入力してパッケージのインストール手順 を実施する
Yahooリアルタイム検索取得クラスを作成する
PythonApplication1.py
import requests
from bs4 import BeautifulSoup
import schedule
import time
class RealtimeSearch:
def run(self):
# 1分ごとに実行するジョブを登録する
schedule.every(1).minute.do(self.search)
# 無限ループで登録したジョブを実行する
while True:
schedule.run_pending()
time.sleep(1)
def search(self):
url = "https://search.yahoo.co.jp/realtime"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
words = [item.text for item in soup.select('article > h1')]
for item in words:
print(item)
r = RealtimeSearch()
r.run()
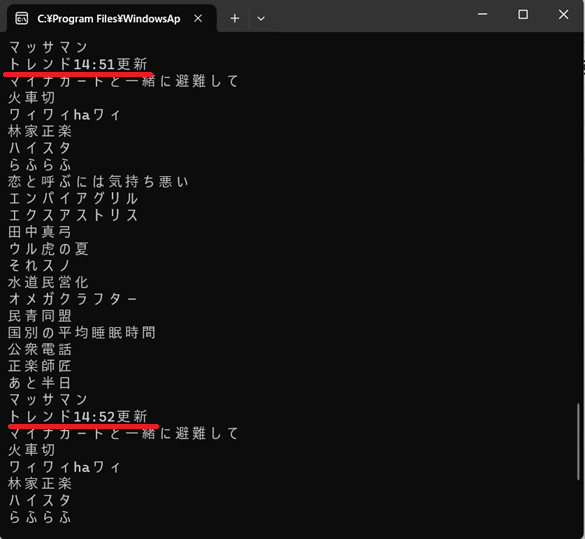
実行すると、1分ごとにYahooリアルタイム検索を取得してキーワードをコンソールに表示します。
2. ファイル保存する
ファイル保存メソッドを追加する
Yahooリアルタイム検索取得クラスを改造します。
PythonApplication1.py
import requests
from bs4 import BeautifulSoup
import schedule
import time
import datetime
from os.path import join
class RealtimeSearch:
def __init__(self, words):
self.words = []
def run(self, output_path):
# 1分ごとに実行するジョブを登録する
schedule.every(1).minute.do(self.search)
schedule.every(1).minute.do(self.save, file_path=output_path)
# 無限ループで登録したジョブを実行する
while True:
schedule.run_pending()
time.sleep(1)
def search(self):
url = "https://search.yahoo.co.jp/realtime"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
self.words = [item.text for item in soup.select('article > h1')]
for item in self.words:
print(item)
def save(self, file_path):
# YYYYMMDDhhmmss.txtのファイル名を生成する
now = datetime.datetime.now()
d = '{:%Y%m%d%H%M%S}'.format(now)
file_path = join(file_path, "{0}.txt".format(d))
# ファイルにリストを書き込む
with open(file_path, mode='w') as f:
f.write('\n'.join(self.words)) # 改行コードを付与する
words = []
r = RealtimeSearch(words)
r.run("C:/work")
以下のような流れです。
①.wordsというインスタンス変数を用意する
def __init__(self, words):
self.words = []
words = []
r = RealtimeSearch(words)
②.Yahooリアルタイム検索取得結果をwordsにセットする
self.words = [item.text for item in soup.select('article > h1')]
③.wordsをファイルに書き出す
f.write('\n'.join(self.words)) # 改行コードを付与する
実行すると、1分ごとにファイルを作成し、Yahooリアルタイム検索取得結果を書き込みます。

ファイルの中身

参考URL
Python 3.11.7 ドキュメント
schedule 1.2.1
テキストファイルへ書き込む
[解決!Python]日付や時刻をYYMMDDhhmmssなどの形式に書式化するには