前回の投稿でpython-docxを利用してdocxを作る事ができるようになりました。今回はこれの応用としてdiffの結果を出すというのをやってみました。これまた備忘の意味も込めて晒させていただきます。ファイルの差分情報の管理などを考える方にとって少しでも参考になれば幸いです。
動作環境
Cygwin上でdiffを取る前提のシステムなんです(笑) なので、以下の環境で確認しました。
- Cygwin(32bit)/Windows10 上
- python2.7
- python_docx-0.8.6-py2.7
python-docxのインストールなどは、python_docxの記事のこことかも参考にしてもらえるかも。
diffでどんな事をするか
今回対象解析とするdiffの使い方ですが、以下限定ですスミマセン。
- -uコマンドを使って差分を取る事
- メッセージが英語である事
基本的には「diff -r -u3 <対象1> <対象2>」で使う事を前提にしています。ただuの後の数字を変更したり、-rではなくファイル単独での比較でも恐らく動くはずです。また、メッセージが日本語の場合は「export LANG=en_US」として一時的に英語にする必要があります。
実際にやるとこういう差分が出ます(これはopensslのコードを一部いじって出したものです)
diff -r -u3 async_old/arch/async_win.c async_new/arch/async_win.c
--- async_old/arch/async_win.c 2017-07-07 08:19:02.000000000 +0900
+++ async_new/arch/async_win.c 2017-07-09 22:58:36.556937300 +0900
@@ -47,7 +47,12 @@
return 1;
}
-VOID CALLBACK async_start_func_win(PVOID unused)
+VOID CALLBACK async_start_func_win2(PVOID unused)
+{
+ async_start_func();
+}
+
+VOID CALLBACK async_start_func_win3(PVOID unused)
{
async_start_func();
}
Only in async_new/: tst.c
このフォーマットの差分情報を元に以下のような簡単な解析を今回は行います。
- 差分のあるファイルとその行数を一覧にしてcsvファイルにします。
- どっちかにしかないファイルも一覧にして同じcsvファイルにします。
- 各ファイルの差分情報をdoxに出力します。差分の箇所には色をつけます(オプション)
構成
今回は以下の3つのpythonファイルを用意して実装しました。
- python-docxを使ってdocxの操作をするSimpleDocxServiceクラス(ここにコードがあります)
- diffファイルの解析を行うParseDiffクラス(上記SimpleDocxServiceクラスを利用します)
- ParseDiffクラスを使ったdiff解析アプリ
この内、python-docxの操作は既に記事化していますので、残り2つをここで紹介させて戴きます。
実際のコード
diffファイルの解析を行うParseDiffクラス
まずはdiffファイルを解析する、事実上のメインであるParseDiffクラスのコードです。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from docx_simple_service import SimpleDocxService
class ParseDiff:
def __init__(self, src_codename, diff_name, cvs_name):
self.FILE_LIST_PATH_INDEX = 0
self.FILE_LIST_COUNT_INDEX = 1
self.src_codename = src_codename
self.input_diffname = diff_name
self.cvs_name = cvs_name
self.file_list = []
self.only_list = []
self.latect_diff_cnt = 0
self.docx = None
self.output_docxname = None
self.print_message = True #メッセージ出す出さない調整をここで出来ます。
def set_docx_param(self, docx_name, font_name, font_size, title, title_img):
self.output_docxname = docx_name
self.docx = SimpleDocxService()
self.docx.set_normal_font(font_name, font_size)
self.docx.add_head(title, 0)
if title_img != None:
self.docx.add_picture(title_img, 3.0)
def adjust_return_code(self, text):
# テキストファイルのデータをそのままaddすると改行が
# 面倒なことになるので、それを削除
text = text.replace("\n", "")
text = text.replace("\r", "")
return text
def adjust_filetext(self, text):
# wordに出す場合は、unicodeにする必要があるのでその処理。
# csvのみの際はエンコーディングはあまり関係ないのでそのまま。
if self.output_docxname != None:
text = self.docx.get_unicode_text(text, self.src_codename)
text = self.adjust_return_code(text)
return text
def mark_diff_count(self):
#差分行数のカウントを、差分情報リストのデータとしてセット
#差分行数のカウントは逐次してます。
#次のファイルに処理が移るか、全ての処理が終わった際に
#ここを呼び出して、差分行数を確定させます。
index = len(self.file_list) - 1
if index >= 0:
self.file_list[index][self.FILE_LIST_COUNT_INDEX] = self.latect_diff_cnt
self.latect_diff_cnt = 0
def check_word(self, text, word):
#textの先頭からwordの文字列があるかどうか
if text.find(word) == 0:
return True
else:
return False
def diff_command(self, text):
#テキストを調べ、diffコマンドのテキストが先頭にあるか調べます。
#戻値は diffコマンドのテキストだったかどうか
#diffコマンドのテキストは特に処理せずスルーする
return self.check_word(text, "diff -r")
def only_message(self, text):
#テキストを調べ、Only が先頭にあるか調べます。
#戻値は Only の処理をしたかどうか。
# onlyのメッセージは
# Only in PATH: FILENAME
# 上記のメッセージから PATH/FILENAME を作って only_listに加える
ONLY_IN = "Only in "
PATH_END = ": "
if self.check_word(text, ONLY_IN) == False:
return
# path文字列を抽出
start = len(ONLY_IN)
end = text.find(PATH_END, start+1)
if end < 0:
return # 通常ここは来ない
path = text[start:end]
# ファイルネームを求める
start = end + 1
filename = text[start:]
filename = filename.replace("\n", "") #改行を削除
# onlyリストに加える
self.only_list.append(path + " " + filename)
return True
def filename_minus(self, text):
#テキストを調べ、---が先頭にあるか調べます。
#戻値は --- の処理をしたかどうか。
# ---のフォーマット例
# --- async_old/async_err.c¥t017-07-07 08:19:02.000000000 +0900
# そもそも --- かどうか
MINUS_TOP_MESSAGE = "--- "
start = text.find(MINUS_TOP_MESSAGE)
if start != 0:
return False
# パス名の最後の位置を取得(上記フォーマット参照)
end = text.find("\t")
if end < 0:
return False
# 以下、--- path が見つかった場合の処理。
# ここがファイル毎の処理の先頭となります。
#前ファイルの差分行数がここで確定しますので、更新します。
self.mark_diff_count()
# 差分ファイルリスト追加し、ファイル名の情報を記載
name = text[len(MINUS_TOP_MESSAGE):end]
list = [name, 0]
self.file_list.append(list)
if self.print_message:
print "..." + name
# docxの指定がなければ、特に処理しない。
if self.output_docxname == None:
return True
# docxにその情報を書き込みます。テキストは色付き
self.docx.add_head(u"ーーーーーーーーーーーーーーーーーーーーーーーーーーーーー", 1)
self.docx.open_text();
text = self.adjust_filetext(text)
self.docx.add_text_color(text, 0,0,255)
self.docx.close_text();
return True
def filename_plus(self, text):
#テキストを調べ、+++が先頭にあるか調べます。
#戻値は +++ の処理をしたかどうか。
if self.check_word(text, "+++ ") == False:
return False
# docxの指定がなければ、特に処理しない。
if self.output_docxname == None:
return True
# docxに色付きで書き込みます。
self.docx.open_text();
text = self.adjust_filetext(text)
self.docx.add_text_color(text, 255,0,0)
self.docx.close_text();
return True
def do_diff_text(self, text):
#差分情報の処理はここで行います。
#必要ならエンコーディングの処理、実態無ければスルー
text = self.adjust_filetext(text)
if len(text) == 0:
return
# 差分がある場合は色分けとカウントを行う
red = False
blue = False
if text[0] == "+":
self.latect_diff_cnt += 1
red = True
elif text[0] == "-":
blue = True
self.latect_diff_cnt += 1
# docxの指定がなければカウントのみなのでここまで
if self.output_docxname == None:
return
# docxの指定があればテキストを追加
self.docx.open_text();
if red:
self.docx.add_text_color(text, 255,0,0)
elif blue:
self.docx.add_text_color(text, 0,0,255)
else:
self.docx.add_text(text)
self.docx.close_text();
def parse_line(self, text):
#一行ごとに解析します。
if self.diff_command(text):
return # diffコマンドの記述は記録対象外なのでスルー
if self.only_message(text):
return # onlyメッセージの処理
if self.filename_minus(text):
# "--- path1"の記述に関する処理
return
if self.filename_plus(text):
# "+++ path1"の記述に関する処理
return
#上記以外は差分情報として書き込む。
self.do_diff_text(text)
def make_cvs(self):
# 差分ファイル情報をcsvにします。
# 差分情報の書き込み
cvs_fp = open(self.cvs_name, "w")
cvs_fp.write(u"diff path, lines, \r\n")
for file_obj in self.file_list:
if self.print_message:
print "flle:" , file_obj
cvs_text = file_obj[self.FILE_LIST_PATH_INDEX] + "," + \
str(file_obj[self.FILE_LIST_COUNT_INDEX]) + ",\r\n"
cvs_fp.write(cvs_text)
# only情報、sortしてから書き込みまず。
self.only_list.sort()
cvs_fp.write(u"only path,\r\n")
for only in self.only_list:
if self.print_message:
print "only:" , only
cvs_fp.write(only + ",\r\n")
cvs_fp.close();
def parse(self):
# diff解析のメイン
# ファイルから一行ずつ読みだして、解析
diff_fp = open(self.input_diffname, "r")
while True:
line = diff_fp.readline()
if len(line) <= 0:
break;
self.parse_line(line)
# 最後のファイルの差分情報がここで確定しますので更新します。
self.mark_diff_count()
diff_fp.close()
# docx出力指定があればセーブ
if self.output_docxname != None:
self.docx.save(self.output_docxname)
# CSVを作成します。
self.make_cvs()
いつも通り汚いコードで恐縮です。見ていただける奇特な方向けに簡単な説明を以下させていただきます。
まずは _init_とset_docx_paramで基本的なパラメータを設定しています。ParseDiffクラスのメンバの簡単な仕様を以下に。
| メンバ | 内容 |
|---|---|
| src_codename | 文字コード("shift-jis"とか) |
| input_diffname | diffした結果があるテキストファイルのパス |
| cvs_name | 出力するCSVのパス |
| file_list | 差分情報、[パス][差分行数]で1データ。これのリスト |
| only_list | どっちかにだけあるファイルのパスのリスト |
| latect_diff_cnt | 現在処理しているファイルの差分カウント |
| output_docxname | 出力するdocxのパス、Noneならばdocxは作らない |
| docx | SimpleDocxServiceクラス |
アプリケーション側はこういうコードを書くことを想定しています。
- ParseDiffクラス生成
- doxも出すならset_docx_paramを呼び出す
- parseで解析(あとはParseDiffが処理します)
という流れなので、parse関数から見てもらうと流れが分かるのではないかと思います(コードが汚すぎて大変だとは思いますが滝汗)
アプリケーション
アプリケーション側はparse呼ぶだけなので比較的簡単です。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
#
# diff --strip-trailing-cr -r -u3 path1 path2 した結果を基に解析します。
#
import sys
# from docx_simple_service import SimpleDoxService
from parse_diff import ParseDiff
if __name__ == "__main__":
if len(sys.argv) < 3:
print "You need docx. -> parse_diff.py diff_name csv_name docx_name"
print "You need csv only -> parse_diff.py diff_name csv_name"
sys.exit(1)
docx_name = None
if len(sys.argv) > 3:
docx_name = sys.argv[3]
diff = ParseDiff("shift-jis", sys.argv[1], sys.argv[2])
image = "report_top.png"
diff.set_docx_param(
docx_name, # ファイル名
"Courier New", # フォント名
8, # フォントサイズ
u"差分情報", # タイトル
image # 冒頭の画
)
diff.parse()
print "complete."
引数は以下を設定しました。
- CSVだけならdiffのパスとCSVのパス
- docxも出すなら、更にdocxのパス
文字コードは今回shift-jis固定にしています(私の中でのユースケースがほぼWinddowsで利用するソースコードだったので申し訳ないです)。後画像ファイルも固定です。この部分を動的に変更したいようでしたら、引数に足すとか、あるいは別途設定ファイルを作成するなどの解決方法があるかと思います。
実際に使ってみる
前提など
上記のコードを実行する際の推奨条件は以下の通りです。
- cygwin上で実行すること
- 3つのpythonが同じフォルダにあること
- SimpleDocxServiceクラスのファイル名はdocx_simple_service.pyであること
- ParseDiffクラスのファイル名はparse_diff.pyであること
- アプリケーションのファイル名はmake_diff_report.pyであること
- report_top.pngという画像ファイルを上記pythonファイルと同じフォルダに置くこと
今回Windows上のソースコードをCygwinでdiff取って解析するという私の事情からこういう推奨条件とさせていただきました。ファイル名については、importの記述を変えれば当然ですが変更可能です。また以降の説明で make_diff_reportとある部分も読み替える必要があります。
あと画像ファイルも必要です。本記事では前回同様、以下のプロ生ちゃんの画像を使いました。

ちなみにプロ生ちゃんの素材は以下から取得し、サイズや文字入れの加工をしています。
http://pronama.azurewebsites.net/pronama/
また当然ではありますが、ライセンスもありますので留意してください。
使い方
まずはCygwin上で差分情報を適当なテキストファイルにしてください。以下のような操作で行います。export はそもそもメッセージが英語であれば不要ですし、一回やれば後は不要です。
export LANG=en_US
diff -r -u3 対象フォルダ1 対象フォルダ2 > diff.txt
そうしますと、diff.txtに差分情報が入りますのでエディタで軽く見て上に書いたような差分があるか見てみます。で、目的のデータがありそうでしたら今回のpythonで解析します。
今回はCSVだけ出す方法とdocxも出す方法とを用意しました。差分が多くなると、docxの処理には時間がかかるためです。単に統計データが欲しいだけならばcsvのみで処理した方が速いと分かりましたのでこのようにしています。
CSVだけを出すのでしたらこんな感じ。
python make_diff_report.py diff.txt diff.csv
diff.csvというファイルが出来ます。これをエクセルで見るとこういう感じで統計データが出てきます(少しエクセル画面で加工しています)
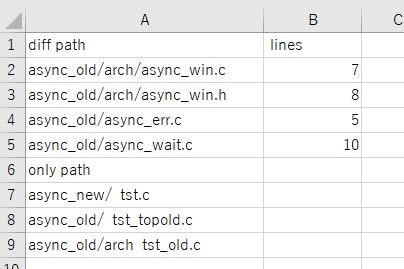
このように差分ファイルとその行数の一覧、あとはどっちかにしかないファイルの一覧が出ます。
次にdocxも出したい場合は以下のようにします。
python make_diff_report.py diff.txt diff.csv diff.docx
diff.csvに加えてdiff.docxも生成されます。ワードで開くとこんな感じです。
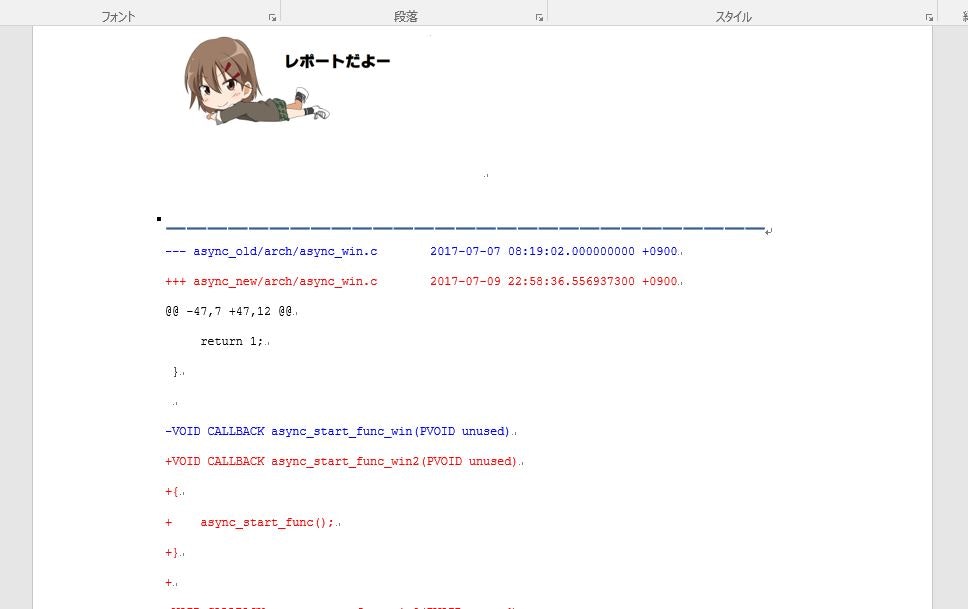
という感じで解析が出来ました。ちなみに私の場合はおおむねはCSVのみで統計情報を出して、いくつかのファイルに関してはdocxで出して、後でワードから加工するような使い方をしています。
ライセンス
以下使わせて戴きました。素晴らしいソフトウェアを提供して下さり、ありがとうございます。
- (一応書きます…)上記のコードはパブリックドメインとします。著作権を主張するほどのコードではないっつーことで。ただ当然ですが使用した際の損害は誰も請け負ってくれません。そこだけ注意で。
- Python自体はPSF (Python Software Foundation)ライセンスです。
- ↑の情報はWikipediaのPythonがソースです。
- python-docxのライセンスは以下に記載があります。MITなようですね。
https://github.com/python-openxml/python-docx/blob/master/LICENSE - プロ生ちゃんの画像は「プロ生ちゃん利用ガイドライン」に従った利用が必要ですので、ご注意ください。
以上です。