背景
データチームメンバーと技を磨こうとしていて、オンライン学習のコンテンツを検討しました。Udemy、Coursera、Codecademy、DataCamp、Udacityなどのオープンソースを見たところ、Udacityの Data Scientist Nanodegree は評判が一番良さそうですので、それを決めました。
チームにとってのメリット
- チームビルディング:同じプロジェクト中心に進められ、一体感が強くなりますし、チームでやるならば、効率が向上できるし、孤独感の解消もできると感じています。
- 実際のプロジェクトベースで進みますので、 (一からPipelineを構築したり、 レコメンドエンジンのアプリケーション構築までやりますとか)、業務で出てきた課題には参考になります。
- データサイエンスを体系的に学べます(教師あり/なし学習、深層学習、レコメンドエンジン、データサイエンスのプロセスなど)。
- ビジネスへの応用まで学べます (CRISP-DM Processなど)。
- 新人研修へのFBに活用できます(今後社内教育のためもあります)。
会社にとってのメリット
- それぞれ実際のプロジェクトを通して、ハンズオンのような実戦から知見を得られます。(世の中、企業の実データ)
- 業務: 整備しているLRS(Learning Record System) & 他のプロダクトの運用に繋がるかと考えられます。
- 対内: 習得したものを、社内勉強会として還元(データチーム以外のメンバーにも)
- 対外: 会社のPRとしても使えます。 (対外発信、記事、採用)
Udacity - Data Scientist Nanodegree の紹介
進め方
- いろいろ実践的なプロジェクトを完成するため、動画など通して学んだ知識を活用し、成果物を提出しレビューしていただく流れです。例えば、IBM Watson Studio Platform の実データを利用し、レコメンドシステムを構築します。
- 価格とコスト
- 999 USD x 2 学期
- Term 1: 3 months (130 hrs) → 約 週10時間
- Term 2: 4 months (170 Hours) → 約 週10時間
- 各プロジェクト成果物の提出に締め切りがありますけど、各学期(term)の最終終了日までにすべての成果物を提出すれば結構です(レビュー&修正を含める)。ただし、各プロジェクトの締切に間に合わないと、どんどん負債が溜まっていくので、すべての締切までに提出するのはおすすめです。
- 材料
- 動画、メンタル(コーチ)、slackチャネル、プロジェクトレビュー
- 動画の風景は下記のような感じです

内容
Term1 (第一学期 約三ヶ月間)
3つのカリキュラムがあります。
-
教師あり学習 (Supervised Learning)
- Project: デモグラフィックデータを利用し、前処理して、ユーザーの貢献するドナーを予測するモデルを構築します。主要特徴量のディスカッションも含まれています。(Regression / Decision Tree / Naive Bayes / SVM / Evaluation など)
-
深層学習 (Deep Learning)
- Project:画像データを元に、画像の分類器モデルを構築します。(Neural Network / Keras / PyTorch など)
-
教師なし学習 (Unsupervised Learning)
- Project:顧客のセグメンテーションを作り、潜在顧客の分析を行います。(Clustering / PCA など)
Term2 (第二学期 約四ヶ月間)
-
Introduction to Data Science
- Project: データサイエンスのプロセスを通して、一通りデータ分析をして、ブログを書きます。(CRISP-DMプロセス / Medium ブログ)
-
Software Engineering
- Project: 構築したダッシュボードをウエブで公開します。(Flask / Plotly / Bootstrap など)
-
Data Engineering
- Project: メッセージの自然言語処理モデルを構築し、メッセージをクラスタリングします。(ETL Pipeline / NLP Pipeline / Machine Learning Pipeline など)
-
Experimental Design & Recommendations
- Project: レコメンドシステムを構築します。(Experiment Design / AB Test / Matrix Factorization / IBM Watson など)
-
Data Scientist Capstone
- Project:自分でプロジェクトを立ち上げて、課題をデータサイエンスのプロセスで解決し、一連のアウトプットをレポートとして作成します。(論理思考 / 問題を明確 / データ処理 / モデル構築 ... など)
補足カリキュラム
Term1とTerm2のコンテンツに加えて、関連の基礎知識も提供されています。
- Python for Data Analysis (Scripting / NumPy / Pandas などの説明&演習)
- SQL (Join / Aggregation / Subquery / Data Cleaning など)
- Data Visualization (可視化。単変数、多変数、ケーススタディ)
- Command Line Essentials (コマンドの使い方)
- Git & Github
- Linear Algebra (線形代数)
- Practical Statistics (実践知の統計学)
- Convolutional Neural Networks
- Spark
スケージュール感.所感
- 予定時間を週別で割くと、一週間あたり10時間がかかると想定していました。業務時間内で確保するのは難しいので、週末や休みの日で進めるパターンが多いです。幸い、メンバー同士と助け合い、問題点や不明な部分はお互に相談できるし、進捗も共有していて、いい感じの緊張感を持って進められるのは良かったと思います。
- Udacityの動画品質が高く、すごく細かいところまでアニメーションとして説明があるので、抽象的な部分もわかりやすくオススメだと思います。
- 一方、各カリキュラムに講師が異なり、教え方と教材の形式、スタイル結構バラツキもありますので、慣れる時間少しかかります。
- 各プロジェクトは、実際にある企業の持っているデータを利用し、プロジェクトを進めるので、実戦の感じもあります。
- プロジェクトは、Jupyter Notebookなど利用して進めています↓
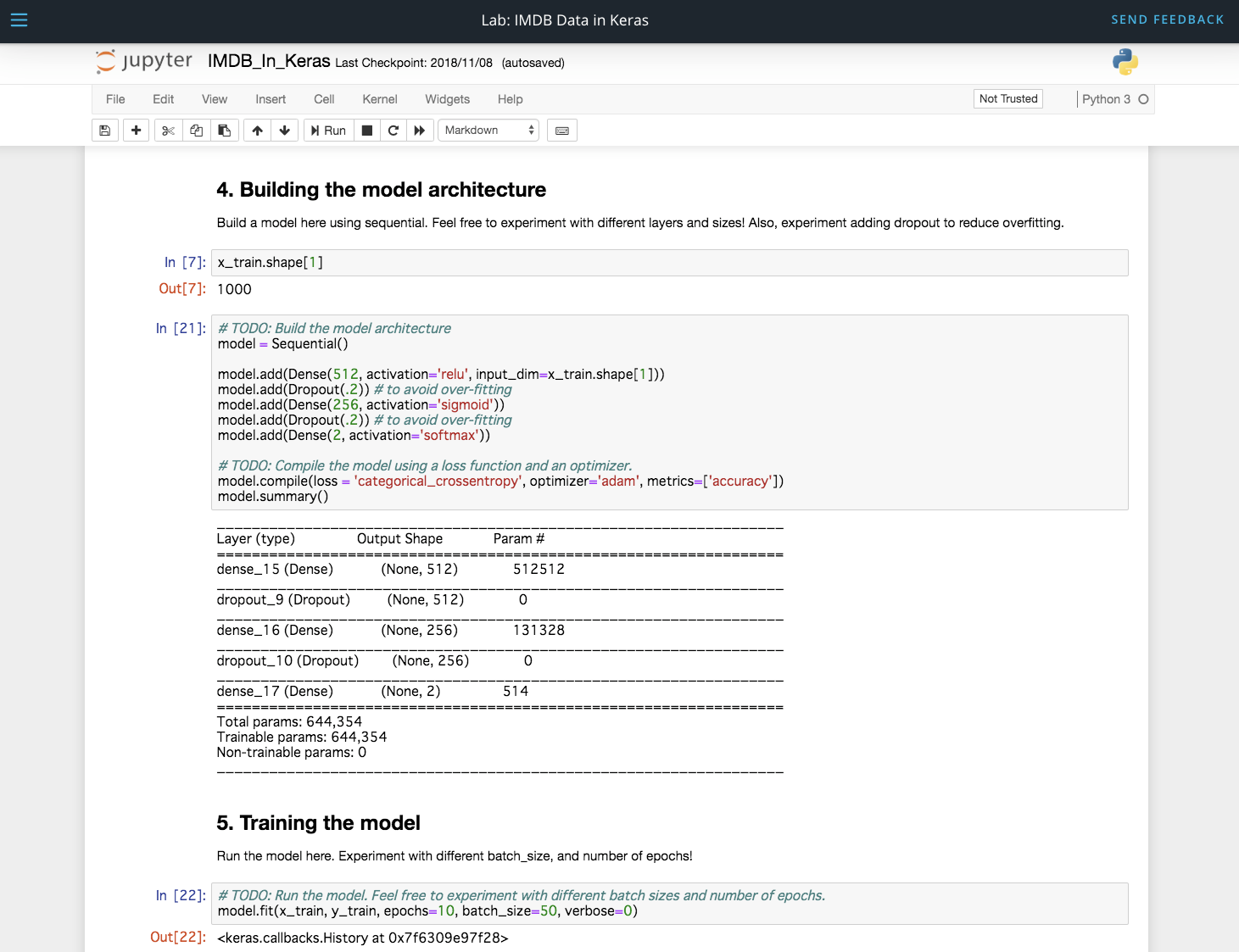
- プロジェクトは、Jupyter Notebookなど利用して進めています↓
弊社に取り組みそうなアイデア
弊社では、「グロービス学び放題」などのサービスを提供していて、動画でビジネス知識を習得したり、職場で足りないスキルをキャッチアップしたり、フレームワークから実践知まで一通り個々の能力を強化するイメージです。Udacityで学習したものに基づいて、はじめに下記の3つが考えられるかと思っています。
- 顧客セグメントの強化:現行のセグメントは、Top-Downのプロセスが主流になっていて、今後Bottom-Upの部分もやっていきたく、見えていない要素を活用していきます。セグメントに応じて、効率的効果的に施策を打てるようにします。
- レコメンドシステムの強化:レコメンドエンジンにおける粒度と精度を、両方共ブラッシュアップします。
- 自然言語処理:コースコメント、フィードバックなどから特徴量を抽出し、顧客の体験を向上します。
最後に
Udacity Data Scientist Nanodegree は、ハードル少し高いと思いますけど、日常生活の一部となっていて、学習の習慣化や頭のトレーニングにも繋がっていると実感しています。一方、自分のタイムマネジメントが弱い部分と、データサイエンスの分野は更に勉強しなきゃという危機感も都度出てきています。
また、今の時代は、やはり実際の学校に行かなくても、オンラインで学習できる体験もすごく良くて、結局自己管理が一番重要な要素じゃないかと感じています。
せっかくこの機会を頂いているので、勉強になった知識を通じて、会社のサービスの拡大と改善、または顧客の成功に支援できるように、生かしていきたいと思っています。また、1 + 1 > 2 という念で、データチームだけではなく、まず知識を社内で浸透させ、日常からデータサイエンスの意識(数字、データドリブン、論理思考など)をして、みんなと一緒に進めていけばと思っています。