前回までのあらすじ
ついにPythonなWebフレームワークのDjangoの開発環境をコンテナで作成することに成功したコンテナ初心者。Pythonの環境構築で常につまづいてきて億劫になっていたことが解消され、ついに機械学習用の環境構築に乗り出す。
Qiita: 3.docker-composeを使用したコンテナでの開発環境セットアップ(Django)
やること
今回はついにPythonと本格的に戦うために環境を整えていきます。
実施背景
今回わたしがPythonで機械学習をすることにしたのは、機械学習で食っていこうみたいなことのためではありません。自作のWebサービスに機械学習を埋め込むためのアプローチを知りたいというのはありますが、Pythonの言語学習と数式をコードにできるようにするためです。
前者、言語学習というのは、Django、つまりWebフレームワークでいくらかPythonのコードを書いていたのですが、ノリがLinuxのconfigファイルをちょいちょいっと書き直すレベルでしか触れていないのでは?という懸念が出てきたためです。
実際ある関係でPythonでコーディングテストを受けてみたらテスト受けてる最中に「へーこんな便利な機能があるんか......」となりながらトライアンドエラーを重ねてしまい、あげく簡単な問題を落としてしまいました。問題が解けても、もともとCで配列だのリストだの触ってはいたのでCっぽく書いてしまう、つまりPythonである必要がない書き方しちゃっているなと感じたりもしました。とりあえずそのことに気付いた時には再度調べてかなりシンプルなコードに直せたので、次はすでに知っておきたいなあとも思ったわけです。
後者、数式をコードにできるようにする、というのも、機械学習で計算式を読んでいたとき、もともと高専で工学での使い捨ての計算式、つまりアルゴリズムだの信号処理だの化学式の計算だのをやってはいても、実装レベルではどうやりゃこの便利な省略形の式が書けるかわからねえ、となっていたのを思い出したためです。
結局その時はインフラエンジニアとしてのプロジェクトから上がったばかりでプログラミングに一切の自信がなかったので、Azure Machine Learningというサービスで機械学習アルゴリズムのモジュールはAzureにまかせ、計算式を理解してからひたすらデータを加工(よく言えば特徴量エンジニアリング、悪く言えば泥臭い特徴量づけをExcelシートのif文使いまくって遂行)し、実用にこぎつけてしまいました。
しかしいまはCakePHPやDjangoをやっていて、効率的な処理を書けるようになりたいなあと思い始め、どうせなら計算式を組み合わせられたらいろんなプログラミングコードの貧弱ボキャブラリも解消できそうな気がしたので、とりあえずオライリーのPython 機械学習本を買いまくって構築できるようにしてしまおうと思ったわけです。データの特徴量づけも抽出も含めてやることになるので、プログラミングの知見もつみやすい、というのもあります。
今回の内容
以上、Pythonを機械学習という題材で覚えてプログラミングのボキャブラリを豊かにするため、環境セットアップをやっていきます。
それにあたって環境を組む時、そしてプログラミングするときはPythonならIDEのPyCharmがおすすめだという記事をよくみました。そして、機械学習の入門ならJupyter notebookがいいというのもたくさんみました。
しかしわたくし、WebアプリフレームワークのプログラミングをviとAtomで全て構築してきてしまったこともあり、Web画面上でプログラミングコードを書く気力がなく、かといってIDEは高専時代Eclipseに環境構築時、およびコーディング時に苦しめられすぎてトラウマもあります。そういうわけで使いこなせてviとAtomといったエディタユーザーな私には、両者は便利ではあっても軽すぎる、あるいは重すぎるのです。
また、IDEのPyCharmの場合はコンテナ上の実行環境に接続するには有償版が必要です。初年度は年額23000円ほど、月額にして2000円を耐えねばなりません。本格的な開発に移行せざるを得なくなるまではしばらく様子見をすることとします。
というわけで、Atomでほぼ完結できるようにする手法として、Hydrogenというパッケージを使用してJupyter notebook環境をAtomで表示する環境を整えます。そして、例のごとくコンテナを使用して機械学習環境をひっぱってきて、それとHydrogenを繋いでしまいます。
この手法のいいところは、VMのコンテナ環境でローカルの環境をほぼ確実に汚さないこと、リモートのマシンでも実現しうる拡張性があること、何よりも無料でいい感じに仕上がることにあります。無料なぶん手間暇かけて作る必要があるので、作ることそのものを楽しめる方におすすめしたい環境です。ちなみに私もまたこういう環境構築系はプラモデルを組むみたいでけっこう好きなタイプです。
前提条件
たびたびになりますが、事前に前回の記事と同一もしくはそれに準ずる環境、すなわちdocker-composeを使用可能な環境の準備をお願いします。
私の書いてきたこの三つの記事は参考になると思います。思えばコンテナの話だけでだいぶ書いてきましたね......
Qiita: 1.VirtualBox + Vagrant + DockerによるOSに縛られないコンテナ環境セットアップ
Qiita: 2.docker-composeを使用したコンテナでの開発環境セットアップ(CakePHP3)
Qiita: 3.docker-composeを使用したコンテナでの開発環境セットアップ(Django)
今回の使用環境
- macOS Mojave 10.14.5
- Atom 1.37
- Hydrogen 2.10.3
- VirtualBox 6.0.4
- Vagrant 2.2.4
- CentOS Linux release 7.6.1810 (Core)
- Docker 18.09.6
- docker-compose 1.24.0
実施する内容
- Dockerファイルの配置とビルド
- docker-compose up
- Hydrogenのインストール
- Hydrogenの設定
- Hydrogenでのコンテナへの接続
1. Dockerファイルの配置とビルド
今回は以下の記事を書いてくれた方のDocker-composeファイルを使用します。
Qiita: 「ゼロから作るDeep Learning ❷」の環境を、Docker+Jupyter Notebook+PyCharmでさくっとつくる
こちらがGitHubです。
今回はDocker VM上の/vagrant ディレクトリにgit cloneします。GitHub上でClone or Download と書かれているボタンをクリックすると、Clone with HTTPSにURLが書かれているのでそれをコピーしてこんな感じで入力しました。
$ cd /vagrant
$ git clone https://github.com/tomoyamachi/deep-learning-from-scratch-2.git
Cloning into 'deep-learning-from-scratch-2'...
remote: Enumerating objects: 404, done.
remote: Total 404 (delta 0), reused 0 (delta 0), pack-reused 404
Receiving objects: 100% (404/404), 7.55 MiB | 2.36 MiB/s, done.
Resolving deltas: 100% (226/226), done.
Checking connectivity... done.
うまくいったようなので確認してみます。
$ ls
deep-learning-from-scratch-2
いますね。とりあえずこれでファイルの用意は完了です。
次にビルドのためにできあがったディレクトリの中に入ります。ここで、最近先輩から教わったのですが、ディレクトリについては今回の場合は「de」まで打ってTabキー押すとディレクトリ名が補完されます。いままで知らずにlsから名前を必死にコピってました......
$ cd deep-learning-from-scratch-2/
そして、su rootしてビルドを実行します。コンピューターが働いてくれるのをだらだらと見つめます。
$ su root
# docker build -t deeplearning .
<中略>
Successfully tagged deeplearning:latest
出来上がったようです。
2. docker-compose up
では起動してみましょう。
# docker-compose up
<中略>
deeplearning_1 | http://(d54a1da4b33f or 127.0.0.1):8888/?token=55eb0e9ec8097911e7a7d0038f55be72b7c91177603249fc
こんな感じになるので以下のURLにアクセスしてみます。VagrantのVMなので、私は以下のURLにWebブラウザでアクセスします。
http://192.168.33.10:8888/
するとこんな感じのWeb画面が表示されます。これが、Jupyter notebookです。
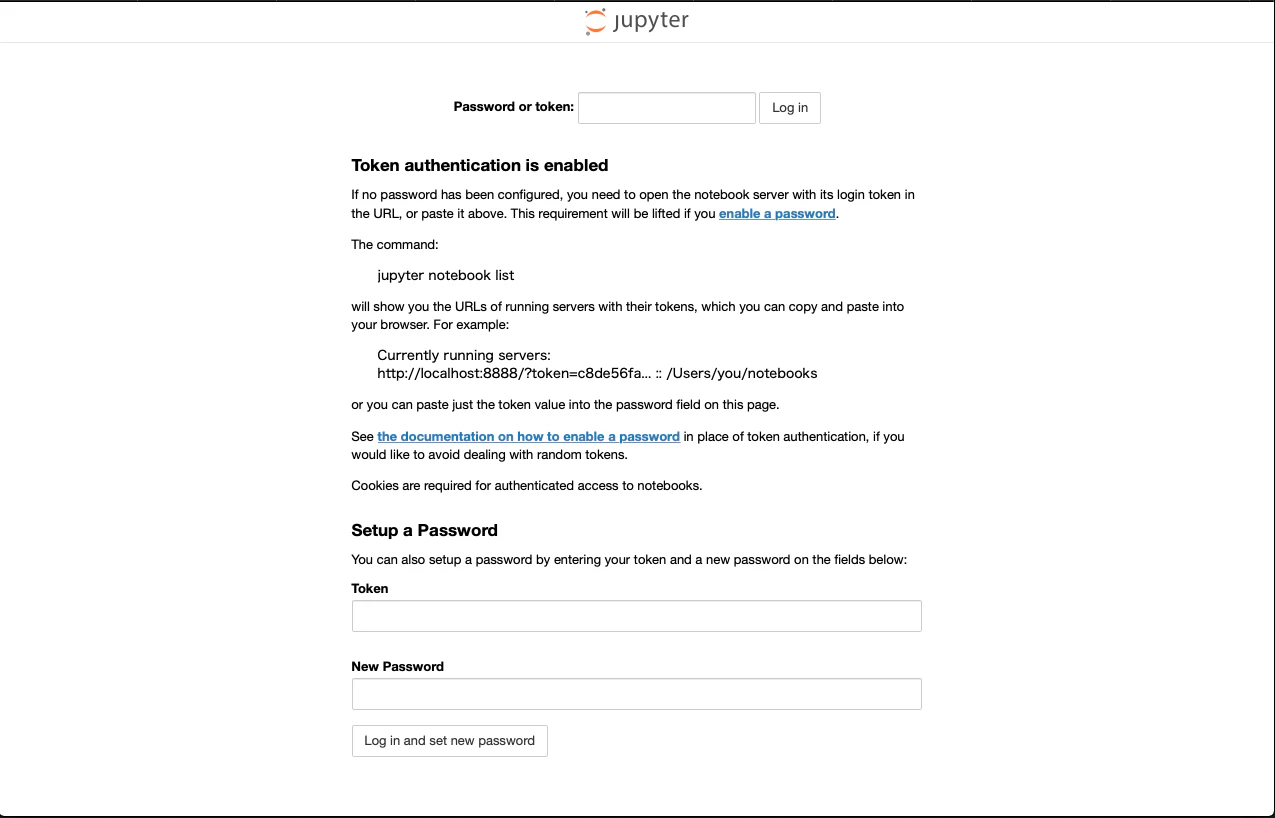
tokenはそれとなく探してみるとこんなところにあるファイルにtoken:で書いてありました。
deep-learning-from-scratch-2/python/.local/share/jupyter/runtime/nbserver-6.json
それを先ほどの一番上のフォームの入力欄に貼り付けると、こんな感じにログイン後の画面になります。実際これでPythonの実行環境はこのWebアプリ上でやれますが、今回はAtomでこれと同等のものをつくっていきます。
3. Hydrogenのインストール
はじめにAtomをインストールしてもらいます。URLを押してダウンロードを押すだけの簡単なお仕事です。
その後、Atomを開いてSettingsを開き、installと書かれている場所で「hydrogen」と入力します。すると100万ダウンロード近くされているやつが出てくるのでそいつをダウンロードします。Atomはこういう感じで自力でPackageをつけていきます。
4. Hydrogenの設定
HydrogenのSettingsボタンを押し、設定をつけていきます。
まず設定の確認のため、別のターミナルエミュレータを起動してコンテナの中に入ります。
[ローカルマシン]$ vagrant ssh
[Vagrant VM]$ su root
# cd /vagrant
# cd deep-learning-from-scratch-2/
# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------
deep-learning-from-scr tini -g -- start- Up 0.0.0.0:8888->8888/tcp
atch-2_deeplearning_1 notebook.sh
# docker exec -it deep-learning-from-scratch-2_deeplearning_1 bash
入れたら以下のコマンドを実行して設定をチェックします。
$ jupyter kernelspec list --json
以下のような結果が出てくるとおもうのですべてコピーし、HydrogenのSettingにあるStartup Codeに貼り付けます。
{
"kernelspecs": {
"python3": {
"resource_dir": "/opt/conda/share/jupyter/kernels/python3",
"spec": {
"argv": [
"/opt/conda/bin/python",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"env": {},
"display_name": "Python 3",
"language": "python",
"interrupt_mode": "signal",
"metadata": {}
}
}
}
}
--(2019/7/14 追記と編集)--
tokenを固定するには以下のコマンドを実行してconfigファイルを作る必要がありました。これやらないとなんどもtokenの設定をコンテナ起動毎に書き換える可能性が出てきます。というか書き換えたらうまく通りましたがなんどもやるものではないと思うので以下の手法で変化しないようにしてしまいました。もしかしたらtokenのチェックは時限式?
[Docker-VM]# docker exec -it deep-learning-from-scratch-2_deeplearning_1 bash
[container]$ jupyter notebook --generate-config
[container]$ jupyter notebook --generate-config
/home/jovyan/.jupyter/jupyter_notebook_config.py
実際に出来上がったjupyter_notebook_config.pyをみにいくと、コメントアウトされたpyコードが広がっています。その340行目をコメントアウトしてtokenを設定してしまいます。
c.NotebookApp.token = '<generated>'
ここではわかりやすく設定例を書いていますがtokenは私のは書き換えています。
c.NotebookApp.token = 'something'
つぎに、Kernel Gatewaysには以下のように入力します。tokenのところは先ほどJupyter Notebookでログインするときにいれたものを入力します。
[
{
"name": "docker",
"options": {
"baseUrl": "http://192.168.33.10:8888/",
"token": "something"
}
}
]
--(追記と編集ここまで)--
これで設定が完了したと思います。
5. Hydrogenでのコンテナへの接続
ではやるにさしあたって、ローカルマシン上にためしにtest.pyなるものをつくっておきます。これを開いた状態で、Packagesに入っているHydrogenのConnect to Remote Kernelを選択します。するとKernel Gatewaysで書いたnameが表示され、次にNew Sessionを選択します。最後にPython3を押せば、これで接続は完了です。
では試しにこんな感じの計算を書いてみます。
2+2
Ctrl+Enterで一行のみの処理を実行します。
結果はこんな感じです。ちゃんと計算されているようですね。ちなみにこの4のところを押すとクリップボードにコピーしてくれます。

4
つぎにPrintでもやってみましょう。
print("2+2=5")
ちゃんと結果が表示されてきます。

2+2=5
ここから先は、実際にPythonコードをガリガリ打っていけばよさそうです。
おわりに
今回はdocker-composeとAtomとHydrogenを組み合わせて環境の構築を実施しました。ここまでくればAtomでもPythonの学習には困らなさげです。あとはDjangoで新しい処理を考えるときにもロジックチェックくらいには使えると思うので、またいい感じの使い方が見つかったら書いていきます。あとは機械学習でのアルゴリズムの実装とかも。
いやはや、コンテナはじめて二、三週間程度ですがここまでPython環境構築が楽だとなんでも興味のあるうちに手が出せてうれしいもんですね......