はじめに
この記事は、私がセキュリティ関係でUnixシェルを扱おうとしたときにうまく理解できず学習しなおしたその過程で生まれました。
確かに私は普段UbuntuのVMを開発環境にして、Pythonを使ってDjangoアプリ、TypeScriptを使ってAngularアプリを書きます。あとはUbuntuやCentOSの上にDockerを載せてコンテナ中心にサーバー運用もします。なのでそれらを可能とするために常々Unixシェルに向かってコマンドを入力しています。
しかしvimやgit含め、ほとんどそれぞれのCLIツールの使い方に終始するだけでよく、パイプやリダイレクトすらもログファイルを確認したりする程度でしか利用してきませんでした。おまけにシェルスクリプトを書かずともすでにあるソフトをひとつひとつうまく組み合わせればシェルスクリプトを自前で書かずともどうにかなってきてしまいました。
するとどうなるかというと、Pythonなどのプログラムを普段からしていてもシェルスクリプトがすぐ読めなかったり書けなかったりという事象が発生しました。具体的にいうと「bashによるサイバーセキュリティ」という面白そうな本があって読んでみた時に、シェルスクリプトの内容はおろか、一行一行のコマンドの意味すらわからないみたいな悲しい状況となっていました。
そこでシェルスクリプトの基本リファレンスという本を買って読んでみたところある程度理解が進んだのですが、どうにも普段練習で書くことが多いPythonの変数とUnixシェルにおける変数との繋がりが見えず、腑に落ちない状況が続いていました。
それで色々考えた結果、そもそも自分がプログラムの記憶領域という全体像から理解を構築し直せば繋がりが見えそうだ、という少々直感的と言えない気づきに至りました。ここから多少シェルスクリプトの苦手意識が減ってきたように感じられたので、その備忘録として残したいと思います。
今回は以下の3点に内容をまとめました。
- 記憶領域となるファイルへの操作(パイプ、リダイレクト)
- Unix哲学
- Unixシェルスクリプトでよく利用される記述方法
「1. 記憶領域となるファイルへの操作(パイプ、リダイレクト)」では、この記事でのタイトル通り、ファイルや変数などの記憶領域に対してのおおまかな整理をしたあとに、変数ではなくファイルをシンプルに加工するためにそれぞれのコマンドを使い、パイプを中心に組み合わせて一行でも使えるプログラミングとして成立させます。また、リダイレクトによるファイルへの出力も扱います。これらの内容は標準出力に結果を出力するあらゆるUnixコマンドにおいて応用ができます。
「2. Unix哲学」では、パイプを含めつくりあげられてきたUnixシェルを題材に、Unix哲学を非常に単純化した、「シンプルなデータをシンプルに加工し、それらを組み合わせる」という内容について述べ、このUnix全体のアーキテクチャにおいて発生する難点やトレードオフの話を数冊のUnix哲学の本なるものを読んできた私なりに記述します。一見Unixシェルと関連のなさそうな話ですが、Unixの全体像をどう捉えてよいか悩んでいる方々への参考にはなるかと思います。
「3. Unixシェルスクリプトでよく利用される記述方法」では、上記の脱線のあとに、Unixシェルにおける初歩的ながら意味のわかりづらい変数やリストを紹介し、やがてif文を組み合わせて数行の小さなプログラムが書けるようになるところを目指します。非常に単純な内容ではありますが、少なくとも今後シェルスクリプトの記事や本を読んだときに確実に扱うであろうものを中心に取り上げていきます。また、即興でコマンドを打つ開発や検証のときにも利用いただけるものかと思われます。
対象読者
以前書いた以下の記事の知識から発展させたりそのまま流用した話をするため、もしかしたらこちらをお読みいただくと理解が促進されるかもしれません。
ただ、はじめに、で読んですでにお察しの通り、普段からUnixシェル含むUnixの開発環境を利用していることを前提として書かれています。そして私のようにほとんどシェルスクリプトを書く機会がなく、Unixの哲学を特に知ることなく利用しているUnix開発者・管理者には多少有益な情報をご提供できるのではないかとは思っております
初学者の方はぜひUbuntuなどのLinuxディストリビュージョンを、お手元のPCにVMとして構築していただくか、MacbookやiMacのターミナルを開いていただき、そのなかで基本的な操作を理解していただけると今回の記事は分かりやすくなると思います。
なお、普段からシェルスクリプトを書いていたり、Unixのアーキテクチャに関して一家言をすでに持てている方にはあまりお役に立てないかもしれません。
また、普段のネット上での技術記事では求められていないUnixにおける哲学(以後はUnixのデザインとも呼びます)にも言及するため、非常に長い文章を読むこととなります。
本当は私もこの長い文章を書かずにどうにかしたかったのですが、まだUnix関連は膨大な情報源を誇るもののそのユーザーが爆発的に増えており、読者対象を絞ることが常ですから、初心者向けのもの、高度に専門的なもの、Unix哲学に関する読み物が多い状況です。
これらの中間の、すべてをつなぐ知識をこの記事では目指します。
利用するUnixシェルについて
今回はUnixシェルということで、普通ならbashで行くところでしょう。ですが、私が普段パソコンとして利用しているのはiMacですぐ試しやすいことから、bashを拡張したzshで触った時の結果を中心に書いていきます。おそらくUbuntuなどのLinuxのbashでも同じ結果が出てくるようになっていると思います。
なおWindowsの場合には、無理にWSLなどを導入するまでもなく、GitをインストールしたときについてくるGit BASHというbashエミュレータによっておおよそのコマンドが動かせます。
テキストエディタについて
今回はUnix開発者・運用者を対象にしているため、お好みのエディタをご利用いただければと思います。私は今回は簡易なものはvim、数行書くものはVScodeを利用しました。どうでもよい話ですがこの記事を書くときもVScodeです。
1. 記憶領域となるファイルへの操作(パイプ、リダイレクト)
プロセスとカーネルとシステムコール
記憶領域の話に入る前に、そもそもの現代のプログラムの動作環境となるプロセスやその基盤となるカーネルやシステムコールの話です。
プロセスとは、LinuxやUNIXなどのOSもといカーネルというプログラムが作り出す仮想的な計算機を指します。それらは外からみていると、仮想的なCPUやメモリが割り当てられているように見えます。CPUについてはさておき、事実としてプロセスにはメモリというものが割り当てられています。
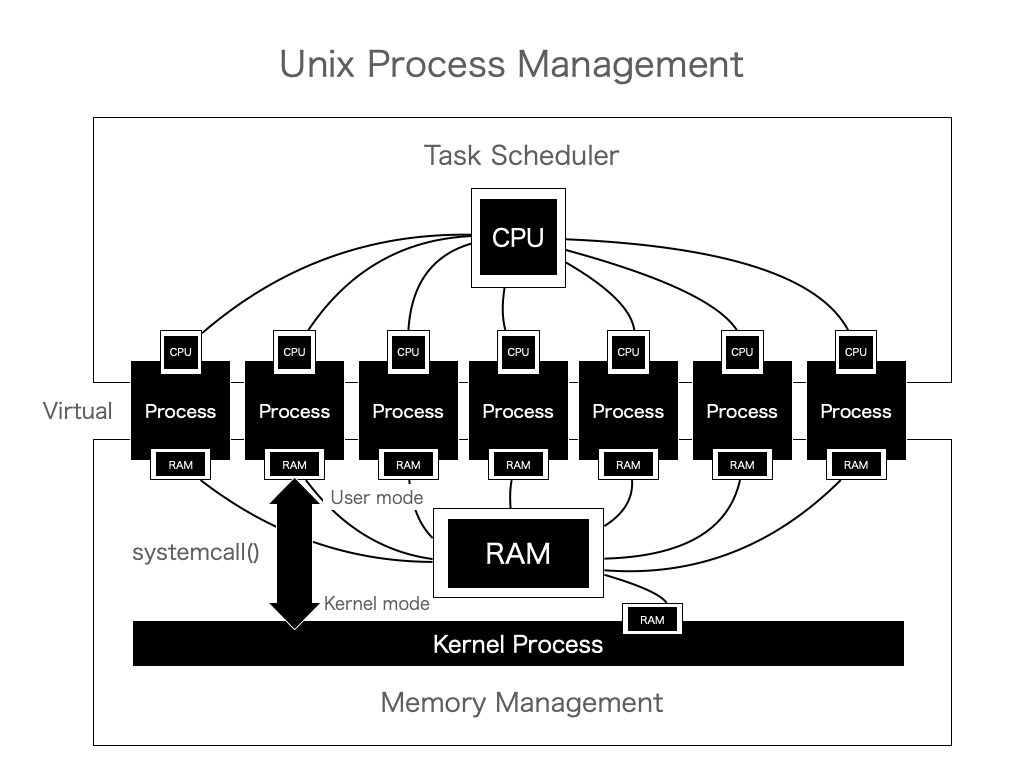
実際のUnixにおいては実メモリにちゃんと書き込まれていますが、番地が書き変わることによって他のプロセスやカーネルのメモリにアクセスが困難なようになっています。
プロセスは、ネットワーク通信したいときやファイルの読み書きをしたいといった、非常に危険な処理を関数のようなフォーマットでOSの中枢、Unixでいうところのカーネルに対して呼び出します。これはシステムコールと呼ばれ、カーネルはその情報を受け取った時のみ危険な処理を実行するようになっています。具体的にはUnixは通常のプロセスとカーネルのふたつのモードが厳密に分けられており、同時にメモリまで分けられています。これによりカーネルが意図しない危険なシステムコールを止める改修が実施しやすい設計になっています。
ソフトウェアの扱う記憶領域の種類
私のようにいくつものシステム開発・運用のためにいろんなコードを書かざるを得ない現代のプログラマーたちは、プログラムコード内でさまざまな記憶領域を取り扱っています。その記憶領域は非常に大まかに分けて二種類あると考えています。
- 変数
- ファイル
変数
変数はプログラム実行されプロセスとなったときにその内部にのみ存在する、揮発的な記憶領域です。
ここでの変数の定義には配列やリストや辞書、それらを束ねた構造体変数やオブジェクトのインスタンスが該当します。
つまりプロセスが終了すれば、変数は消えることとなり、永続化できません。同時に、他のプロセスに変数の値を渡すことは原則できないことととなります。これを回避するには、複数のプロセスを統括するひとつのプロセスを準備し、それぞれに値を渡していくというやりかたになるでしょう。それは後々書くシェルスクリプトでの変数の使い方に近いです。または共有メモリなどで無理やりプロセス同士で繋いだ変数のやりとりをするか、マルチスレッドによって擬似的に複数のプロセスがいるようにみなすしかありません。しかしこれでも実行結果を画面に表示しないと結果を残すことができません。
ファイル
そこで、変数の結果を永続化させる記憶領域としてOSもといカーネルが提供するファイルが利用できます。実行結果を変数に書き込んだあと、変数からファイルに書き出すことをすれば、プロセスが終了してもファイルの中身を確認することで記憶領域を永続化させられます。
ここでのファイルの定義には、以下のように一般的なテキストファイル、バイナリファイルが該当します。ここでUnixの場合は標準入出力やパイプ、ソケット、デバイスなども該当するようにファイルシステムがつくられています。Unixのこのデザインが、「Unixではすべてのオブジェクトがファイル」と言われる理由となります。
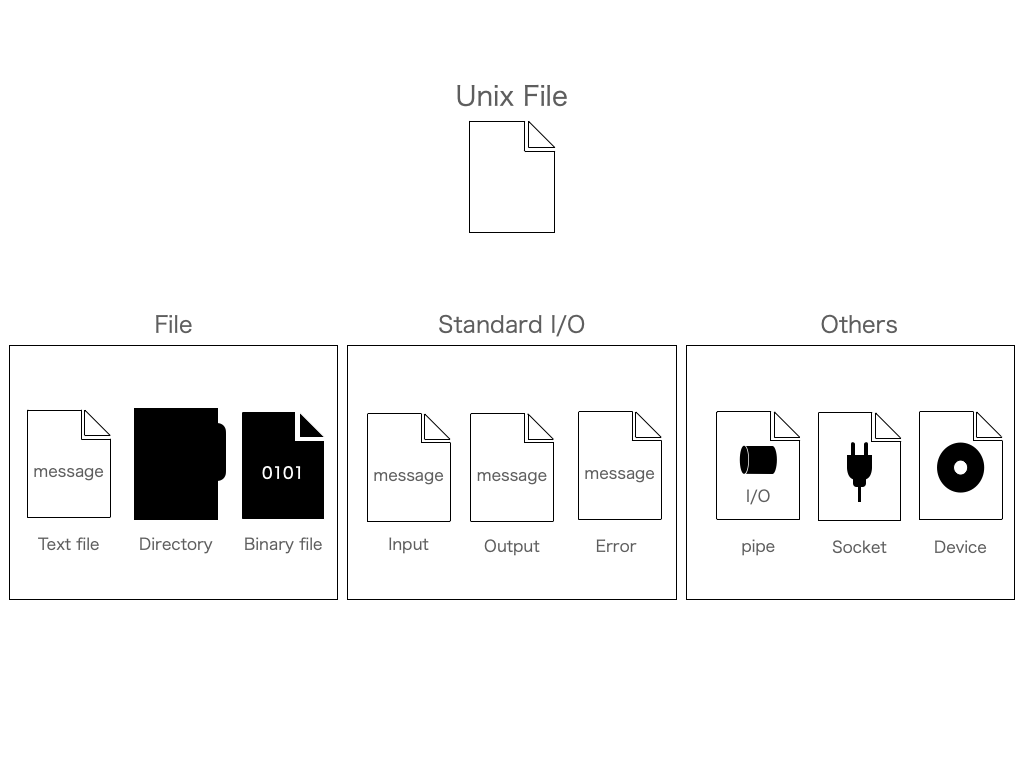
この広範囲なUnixのファイルに対するデザインは、他のプロセスからも読み込みを行うことが可能としています。これがプロセス間通信(InterProcess Communication)に相当します。
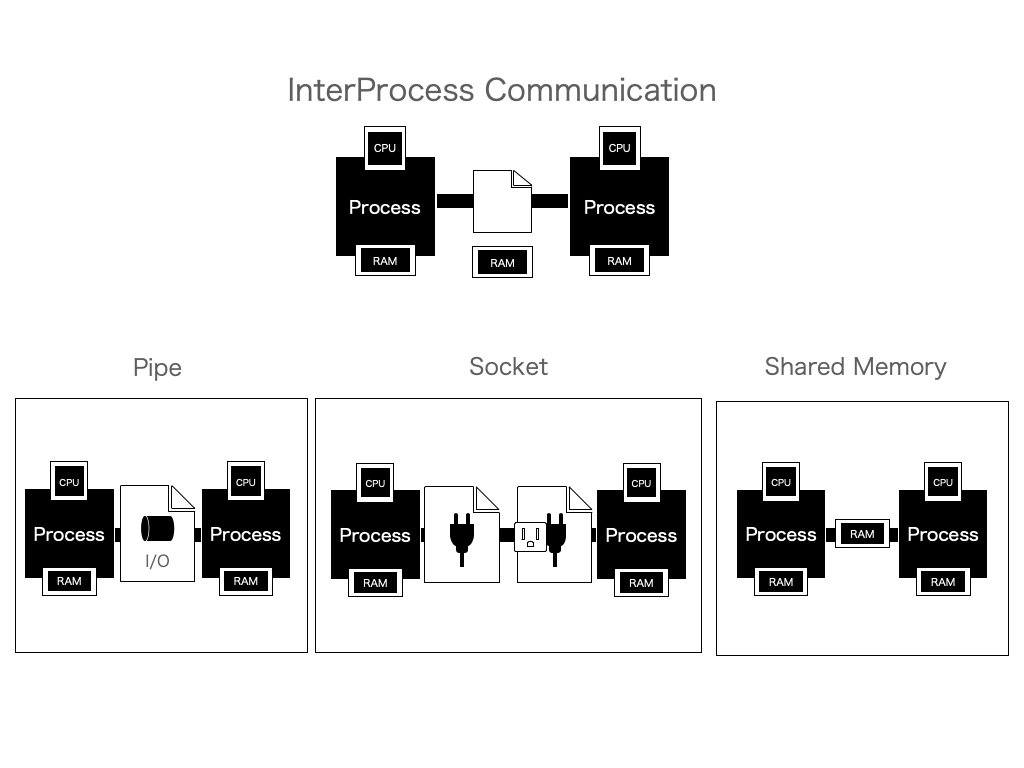
共有メモリ(Shared Memory)はファイルではなく剥き出しのRAM上の変数を一部共有するやりかたで例外的ですが、変数を複数の一時ファイルを利用するという発想でみてみると比較的近い概念です。
ソケットはsocket()をはじめとするいくつかのシステムコールを利用して生成されるファイルと言えます。このファイルに対してデータを読み書きする、というデザインをすることで、比較的容易にプロセス間での通信を可能にします。プロセス間どころかコンピュータ間でもこの方法で記述できるので、現在はこのソケットがネットワークプログラミングにおいてはほぼ唯一の選択肢となっています。
今回特に利用するのは、パイプというものです。これは一時ファイルをさらに使いやすくしたものです。
パイプとは
パイプという特殊なファイルをカーネルに近いシステムコールの仕様から大まかに記述すれば、入力専用のファイル記述子(ディスクリプタ)でデータを書き込んでおくと、出力専用のファイル記述子で読み出せばデータを取得できる、というものとなります。
直感的には一時ファイルでよいと言えますし、場合によっては一時ファイルで実行せざるを得ない内容もあるかもしれません。しかしこのパイプが優れているのは、カーネルがこの機能を提供してくれているという観点で、特に実行が失敗したとしてもファイルが残ることがありません。なのでユーザー側が一時ファイルに関する諸々の手続きを考慮しなくてよく、扱いが非常に簡単です。
Unixシェルはこのパイプをより簡単に扱うことを可能としています。それが、コマンドとコマンドの間の|で、パイプラインの文字に相当します。
先ほどのシステムコールの話と一致させると、左側コマンドで|を確認すると標準出力ではなくパイプの入力専用のファイル記述子でデータを書き込んでくれて、右側のコマンドは|を確認するとパイプの出力専用のファイル記述子からデータを読み込んでおいてくれます。
なお、WindowsのコマンドプロンプトやPowershellにおいてもこのUnixシェルの仕様を参考にパイプを利用できるようになっているようです。
パイプの操作
早速このパイプをコマンドで操作してみます。
その前に事前作業として、以下のように任意のディレクトリを作成しておいて、空のディレクトリ内で実施することをおすすめします。
mkdir unixshell
cd unixshell
以下のような記述のあるファイル、test.txtを作成します。末尾には改行も加えておきます。
unix
mac
linux
さきほどの図の表現に合わせた記述の仕方をすれば、このtest.txtを標準出力という特殊なファイルに書き込むことでCLI上に表示させることとします。今回本来のコマンドの使い方とはやや違うcatコマンドにより実現させます。catは本来それぞれのファイルを連結するためのコマンドです。
% cat test.txt
unix
mac
linux
ちなみにcatコマンドに何も入力しないと、標準入力から入力を求められます(実際特に何も入力を要求する文字はでてきませんが)。入力すると、標準出力が出てきます。ファイルの終端を示すEOFが入るまで続きますのでCtrl+DでEOFを送り終了します。
% cat
hoge #標準入力からの入力を要求
hoge #標準出力
# Ctrl+D で終了
以上のことからcatは標準入力からファイルを読み込んでいると言えます。そこで、パイプによってcatの結果をcatの入力に渡すこととします。
このcatコマンドとパイプラインをはさみます。すると先ほどとは異なり標準入力からの入力を求められることなくファイルの中身が見えました。このことから標準入力へパイプを通じて結果が渡され、そのまま出力されたことがわかります。
% cat test.txt | cat
unix
mac
linux
ただcat同士で繋ぐなんて、普通はしません。正直私も初めてやりました。皆さんが普段しているのは以下のようにgrepを利用する方法だと思います。結果はご想像通り、unixという文字列の行だけがフィルタリングされ出力されています。
% cat test.txt | grep unix
unix
なお余談ですがgrepは以下のように引数を入れればわざわざcatコマンドを挟むことは必要ありません。
% grep unix test.txt
unix
普段ログファイルを確認するなどのときは、たぶん以下のようにtailだけを打つと思います。今回は三行しかないのですべて出てきてしまっていますが。
% tail test.txt
unix
mac
linux
このファイルではそうでもないですが、fluentdなどで収集するjsonのログの場合は、一行が膨大ですべてを一瞬で読めません。なのでgrepを組み合わせて利用することがあるかもしれません。
tail test.txt | grep unix
unix
リダイレクトの操作
リダイレクトはパイプラインの代わりに>や<を入れることで実行することができます。例えば、catコマンドの本来の使い方をしてみます。結果は以下のようにふたつのファイルが連結(conCATenate)されます。
% cat test.txt test.txt
unix
mac
linux
unix
mac
linux
この結果は暗黙的に標準出力に書かれてしまいますので、ファイルに書き込めるようにします。以下のように>で繋ぎます。
% cat test.txt test.txt > cattest.txt
雑ですがcatでファイルの中身を標準出力に送って表示します。するとさきほどcatをリダイレクトしなかった場合と同様の結果が表示されます。
% cat cattest.txt
unix
mac
linux
unix
mac
linux
ちなみに>は完全に上書き保存してしまいますが、ログファイルのように追記したい場合もあります。そのときは>>を利用することで簡単なログファイルとして生成することができます。
echo "false: testfile is not exits" >> errortest.log
以下は三回上記echoコマンドをやった例です。
% cat errortest.log
false: testfile is not exits
false: testfile is not exits
false: testfile is not exits
ではこの>を反対の<で利用するとなるとどうなるかというと、例えばgrepコマンドで利用できると思います。以下のようにファイルの中身の情報をgrepコマンドに直接読み込ませることもできます。
% grep unix < cattest.txt
unix
unix
以下のコマンドと結果は同じですが、<があるぶん少々わかりやすくなっているかもしれません。
% grep unix cattest.txt
unix
unix
私はリダイレクトの<のほうはPostgreSQLの論理バックアップのsql文をpsql経由で流し込むときに利用したりしています。
2. Unix哲学
最も単純なUnix哲学: シンプルなデータをシンプルに加工し、それらを組み合わせる。
Unix哲学というと、「The Art of UNIX Programming」や「UNIXという考え方」というそれぞれ良い本に様々な良いことが記述されていますが、それらをひどく単純化させていうと、以下の言葉に収束すると思われます。
シンプルなデータをシンプルに加工し、それらを組み合わせる。
基本的にUnixのデータも処理も単純明快なものがほとんどを占めています。先ほどコマンドで実行した以下のコマンドの結果などはまさしくこの単純なUnix哲学に収束します。
tail test.txt | grep unix
unix
Unix哲学の難点: 組み合わせは時として人を混乱させる
一見すると素晴らしく見えるUnix哲学ですが、難点も多いです。まず初学者を混乱させやすいのです。
さきほどのコマンドがUnix初学者(かつての私)のような不慣れな人が見たときに動揺させるのは、何を示しているのかわからず、それぞれの対応が入出力からは容易に類推できないために、自分の理解を超えた複雑さに見えるからです。私自身ひとに教えてる時間以外は忘れがちなのですが、それぞれのコマンドの意味が十分に理解できていて、はじめて結果を推測できるのです。
また混乱させるのは初学者ばかりではなく、Unixに馴染んだ人でも直感的でない話があります。
特に代表的かと思われるのは、Unixカーネルとして利用するべきアーキテクチャはモノリシックカーネルかマイクロカーネルか、という問題です。Unix哲学の原則でいくと分割された機能を持ち、必要に応じてユーザープロセスのように起動するマイクロカーネルがよいと直感的に思うかもしれませんが、現実は異なります。原初のUNIXも、現在最もUnixの中心となっているLinuxも全ての機能をひとつのカーネルプロセスで含有するモノリシックカーネルです。
マイクロカーネルがいないというわけではないのですが、マイクロカーネルはカーネル内の情報のやりとりのためにプロセス間通信をしなければならず、そのインターフェース(一般にAPIとされるもの)の問題も同時にメンテナンスしなければならず、思い切って下位互換を切ったときのリスクが非常に大きいなど、プログラマーに優しくない問題を抱えています。マイクロカーネルの代表例は、実はUnixではあまりおらず、Windows NT系です。「LINUXシステムプログラミング」によれば執筆当時のLinuxのシステムコール数はおよそ300ですが、Windows NT系は数千に上るとされています。
Unix哲学の難点: シンプルなデータ加工の組み合わせ(機能の分割)が初学者に理解を促すとは限らない
モノリシックカーネルといえども、Linuxも初期のUNIXもコードにおけるモジュール化には積極的だと思います。Linuxカーネルメンテナーのなかにはおそらくこのモジュール化に血道を上げている人もいるかもしれません。しかしこのモジュール化もそれぞれの機能を理解できた上でないとなぜ分割しているのか、それぞれがどのように統合されているのかを初学者が何も知識もないまま把握しようとしても困難なことがほとんどです。
このモジュール化は現在はUnixのコードだけの問題ではなく、Reactを起点につくられたTypeScriptのアプリやRailsのDB中心のアプリなどの初学者が真っ先にやるであろうものにすら常に出てくる問題で、このあたりが初学者の学習の意志を粉々にさせるまでそう難しくないという悲しい理由のひとつかもしれません。Unix黎明期から続く現代のプログラミングは、ほかの学問と同様に、発展すればするほどによほどの執念または楽しみがない限り続けることを難しくしていくものです。
このようにUnixやプログラミングがわからないとされるのは、ほとんどの場合が組み合わせた時に生じるものだったりするものですが、モノリシックカーネルの話と同様に、その組み合わせによる複雑さを回避しようとした時に起きるものだったりもします。
Unix哲学を利用しない場合の難点: 複雑さを回避しようとすると新たな複雑さに遭遇する
組み合わせによる複雑さの回避というのは、「UNIXという考え方」ではlsコマンドのsortコマンドのような整列を暗黙的に実施することすらlsコマンドのコードメンテナンスを困難にするアンチパターンと書いているほどではあったかと思いますが、実際常にsortコマンドでパイプで記述して利用しなければならないのは現代の私からすると面倒ではあります。ただし、私自身lsコマンドのメンテナンスをする立場ではないからこそこういうことが書ける状況です。
また、パイプラインでコマンドを組み合わせずともUnixコマンド群のコマンドのオプションを使えば最近はほとんどどうにかなることも増えていますし、gitやパッケージ管理システム(apt, yum, pip, npm....)あげくdockerなどのコマンドがますます強力になってきています。実際私自身がこの強力なCLIツールによってかなりの仕事を日々手助けされています。
しかしこの強力さが、コードのメンテナンスだけでなく、manコマンドや公式ドキュメントの確認を常に必要とさせる状況をつくりだしますし、プログラマーに常に技術を学習することを前提にさせています。コマンドのオプションが何を示しているのかよくわからないとか、古き良きUnixを知っているからといって現代のプログラマーと同等以上の動きができるとも限らない、という問題にどうしても常に衝突してしまいがちなのです。
Unixのアーキテクチャそのものが文化であり、複雑さのトレードオフの上で成立している
極め付けのUnix哲学の問題は、Unix全体の省略語は操作対象の変数やファイルなどを十分に理解している前提で書かれていることがほとんどで、つまりUnixユーザーはUnixをUnix開発者と同等に理解していることを前提としています。
最近はLinuxをはじめとして劇的な最適化の結果、カーネルメンテナー以外は分からない部分も増えてはいるでしょうが、今から約40年前のUnix v6時代のインターフェースのレベルでの理解かそれに準ずるUnix利用経験はあって当然、くらいのノリはまだ残っているようですし、実際私自身もそういった本(特に「はじめてのOSコードリーディング ~UNIX V6で学ぶカーネルのしくみ」、「システムコール基本リファレンス」、「ふつうのLinuxプログラミング」)を買うまではわからないことが非常に多かったのを記憶しています。
このようにソフトウェアの複雑さには、その解決法となるソフトウェアデザインが発見されたりしない限りは常に経済学で言うところのトレードオフに縛られることとなります。現代の広義のソフトウェア・アーキテクトとは、このトレードオフを十二分に理解し、時に斬新かつ実用的で価値あるデザインをもって実装していくプログラマーが実施する、驚くほど実践的な仕事なのかもしれません。
3. Unixシェルスクリプトでよく利用される記述方法
&&リストや||リストを使って簡易な条件分岐によるコマンドを実行する
脱線はここまでにして、Unix特有の&&リストや||リストという概念を扱っていきます。これらは簡単な条件分岐コマンドを実行することができます。ただし、真が偽かのいずれかの処理しか動かすことができません。
&&リスト
&&リストははさまれた直前のコマンドの結果が真だった場合に次のコマンドが実行されます。例えば、以下のような今回利用したコマンドがあったとします。結果はunixというテキストを見つけて抽出してくれるようになっています。
% grep unix test.txt
unix
このunixと出る結果を真とみなし、この真という結果が出たときにechoコマンドで「true」と表示されるように&&リストを利用します。すると以下のようにunixという結果のあとにtrueと表示されます。
% grep unix test.txt && echo "true"
unix
true
逆にgrepコマンドで存在しない「hoge」を入力した場合は、以下のように何も出力されることなく終了します。これは偽であったためgrepの結果が出力されず、echoが実行されなかったためです。
% grep hoge test.txt && echo "true"
%
||リスト
||ははさまれた直前のコマンドの結果が偽だった場合に次のコマンドが実行されます。例えば、以下のように書き換えることでgrepの結果が出力されないままにechoが実行されます。
% grep hoge test.txt || echo "false"
false
真偽の判定を確認できる終了ステータスの変数$?
さきほどの&&リストや||リストが内部的に終了ステータスのパラメータ、つまり変数を確認しており、以下のように$?を表示することによって結果を確認することができます。以下のように真のときは0を示します。
% grep unix test.txt
unix
% echo $?
0
一方で偽の場合には0以外を指します。
% grep hoge test.txt
% echo $?
1
ただし、あくまで直前の結果のみしか確認できないため、さきほどの||リストでの結果ではechoのコマンドの真の結果が上書きされて出てしまいます。
% grep hoge test.txt || echo "false"
false
% echo $?
0
ただ、この終了ステータスに関してはシェルスクリプトを書く前に実際にコマンドとして動作させて確認したほうが賢明だとみられます。それはどんなプログラミングでも言えることかもしれませんが。
シェルスクリプトにおける変数の利用方法
普段Pythonの対話型インタプリタでの試行錯誤に慣れている人ほど、また多少アセンブリ言語でのレジスタ値やら被演算子(オペランド)やらをぼんやり覚えている人ほど(つまり少なくとも私は)、それらが災いしてシェルスクリプトにおける変数の利用の仕方はわかりづらいです。先ほどの終了ステータスのように、呼び出すときは$を必要としているのです。
% echo $?
0
その一方で、変数として代入しておく場合には以下のように$は必要ありません。
% val="hoge fuga"
逆に$を入れようとするとコマンドとして認識されてしまいます。
% $val="hoge fuga"
zsh: command not found: hoge fuga=hoge fuga
そしてほとんどechoでないと直感的に変数の値が確認できません。
% echo $val
hoge fuga
Pythonに慣れていると脊髄反射で以下のように入力しがちです。そしてコマンドとして認識されてしまい変数に値を入れられません。
% $val
zsh: command not found: hoge fuga
ただ、シェルスクリプトは今までのコマンドからも明らかなように、一行で書くぶんにはほとんど変数を必要としません。それらはすべてパイプやリダイレクトを利用すれば、やりとりされるテキストファイルを一つの大きな変数のように利用することができるからです。例えば以下のリダイレクトのコマンドはその証です。
% grep unix < cattest.txt
unix
unix
それでも変数を利用しなければならないのは、こうしたワンライナーでのシェルスクリプトでは問題を解決できないときです。たとえばシェルスクリプトを書き、cronなどのジョブスケジューラに登録して定期的に実行するときなどです。
こうなると自動になりますから、その実行の可否を判定しなければならないものもいくつか出てくるはずです。システム運用においては、例えば連携する特定のバッチ用データファイルの存在確認や、直近のDBバックアップファイルの大きさの確認、ディスクの使用率の計算などです。
これらの運用を複合的に行うためには、一連のフィルタリングのようなひとつの大きな変数的ファイルだけでなく、そのほかの情報も格納できる変数があったほうがよいです。
では実際にファイルの存在確認をし、その結果を標準出力ではなく変数に格納することを想定します。まずはみなさんに馴染みのあるlsコマンドです。
% ls
cattest.txt test.txt
このコマンドの結果を変数によって格納する場合は、以下のように$()で囲います。
% val=$(ls)
echoで$valの中身を確認すると、lsの結果が格納されています。これでワンライナーなひとつのファイルを加工(フィルタリング)していくスクリプトから脱却する方法が確立できたといえます。
% echo $val
cattest.txt
test.txt
余談ですがもちろん以下のようにパイプラインで囲われたコマンドも変数に格納することができます。
% val=$(ls | grep cattest.txt)
% echo $val
cattest.txt
変数を取り出してgrepに渡すにはファイル(標準出力)に書き出させるしかない
以下のコマンドでlsの結果が格納できたことがわかりました。
val=$(ls)
今度はこの$valの中にcattest.txtが存在するかどうか確認する方法となります。
ただし、以下のように変数をファイルのように扱ってデータを取り出すことはできません。
val=$(ls)
grep test $val
grep: cattest.txt
test.txt: No such file or directory
あまり美しくはありませんが、以下のように書くことでgrepをさせることができます。echoコマンドで$valの値を標準出力というファイルに書き出し、grepコマンドに標準入力として読ませ、cattestというフレーズを検索させるというものです。grepにおいては、変数といえどもファイルでデータを受け取ることを前提にしているようです。
% val=$(ls)
% echo $val | grep cattest.txt
cattest.txt
なお以下のようにgrepする検索ワードを変数で定義することはできます。
% word=cattest.txt
% echo $val | grep $word
cattest.txt
if文を構成するtestコマンド
if文のある構文を利用するとき、testコマンドを実行することになるという奇妙な仕様があります。それでこのtestコマンドがなんなのかと言うと、コマンド実行後、真だった場合は終了ステータスを0、偽だった場合は1を返すというシンプルなコマンドです。以下はその挙動を試したときの例です。まずはcheck変数にlsをgrepした結果を格納します。中身を見るとこれはcattest.txtです。
% val=$(ls)
% check=$(echo $val | grep cattest.txt)
% echo $check
cattest.txt
次にtestコマンドでcattest.txtと一致するかを確認します。その後終了ステータスを確認すると、真として0が格納されています。
% test $check = cattest.txt
% echo $?
0
逆にここでhogeと比較すれば偽として1が入ります。
% test $check = hoge
% echo $?
1
if文を実行する
if文を書く場合は、iftest.shなるファイル名で以下のように記述します。
[]で囲われた部分で、testコマンドが実行されます。その結果が真(0)の場合はthenのechoコマンドtrue, 偽(1)の場合はelseのechoコマンドに移動する、という仕組みになります。
val=$(ls)
check=$(echo $val | grep cattest.txt)
if [ $check = cattest.txt ]
then echo "true"
else echo "false"
fi
実行権限の付与の関係がありますが、今回は以下のコマンドによって省略しました。これにより、ついに条件分岐ができたといえます。
zsh iftest.sh #zshの場合
bash iftest.sh #bashの場合
ただ元も子もない話ですが&&や||でこの内容は一行でさらにわかりやすく表現ができます。
&&の場合は自分でコマンドで確認するときに便利です。
% ls | grep cattest.txt && echo true
cattest.txt
true
||の場合は定期的なバッチ実行にしておいといて異常があったとき専用のログファイルに追記させる、という仕様にしておくと便利です。
% ls | grep hoge || echo "false: testfile is not exits" >> errortest.log
% cat errortest.log
false: testfile is not exits
% ls | grep hoge || echo "false: testfile is not exits" >> errortest.log
% cat errortest.log
false: testfile is not exits
false: testfile is not exits
これらのUnixシェルを利用した応用方法
ここまで基礎的なファイルに対する処理を実施してきましたが、実際にすぐ使えるのはせいぜい/var/log/配下のシステム系ログファイルの確認や、自分のつくったシェルスクリプトの専用ログファイルの追記くらいかと思います。ただシステム管理でデータを収集する場合や開発ビルド専用機で別途自動化したいビルド・デプロイ用コマンドなどがあれば、これだけでも十分に強力です。
あとはシステム用のコマンドを適宜打ちながらフィルタリングをしてデータを地道に掘り当てるのみです。詳細なログファイルの場所やシステム用のコマンドについてはかなり多岐にわたる内容のためここでは扱えませんが、少なくとも私は今抱えているいくつかのUnixシェルを利用した本についてはどうにか読み進められそうな状況となったように感じます。
またシェルスクリプトによるfor文などのかなりプログラミングに寄った内容についてもここでは扱えませんでした。単純にまだ私の使い方だと繰り返し処理をさせたりする内容にまで踏み込めていないところがあります。詳細な使い方については、他の本や記事などをご参照ください。
おわりに
ますます強力になってきたLinuxのエコシステムですが、こうして掘り返して記事にしてもまだまだ知らないことが多いな、と感じました。それでもここまでですでに15000字に達しているのですが。ここまでお付き合いいただきありがとうございました。またUnix関連で覚えたことがあれば記事にしたいと考えています。
参考文献
Paul Troncone「実践 bashによるサイバーセキュリティ対策 ―セキュリティ技術者のためのシェルスクリプト活用術」
https://www.amazon.co.jp/dp/4873119057/ref=cm_sw_r_tw_dp_NQWDHF0QBG3QF5W6RYND?_encoding=UTF8&psc=1
山森 丈範 「[改訂第3版]シェルスクリプト基本リファレンス」
https://www.amazon.co.jp/dp/4774186945/ref=cm_sw_r_tw_dp_EFD8K7DNFFMPJAR7CWS6
エリック・スティ−ブン・レイモンド「The Art of Unix Programming」
https://www.amazon.co.jp/dp/B07PYTR159/ref=cm_sw_r_tw_dp_J1ST4VQ7CNQJND80MP11
Mike Gancarz「UNIXという考え方―その設計思想と哲学」
https://www.amazon.co.jp/dp/4274064069/ref=cm_sw_r_tw_dp_GEQYQ5QZH32Q35H80EE9
青柳 隆宏「はじめてのOSコードリーディング」
https://www.amazon.co.jp/dp/B0821XY1QJ/ref=cm_sw_r_tw_dp_CFM2JG589SGXY2JFPZ43
山森 丈範「Linuxシステムコール基本リファレンス」
https://www.amazon.co.jp/dp/4774195553/ref=cm_sw_r_tw_dp_QKW83MSPP8SCA7AB7AXF
Robert Love「Linuxシステムプログラミング」
https://www.amazon.co.jp/dp/4873113628/ref=cm_sw_r_tw_dp_89538ATF8A6H2KC27PY7