困ったことありませんか?
私は、毎日欠かさずコーヒーを淹れて飲むのが日課です。
ある日、コーヒー豆が少なくなっていたことに気づき、
ふと、こう思いました。

「コーヒー豆があとどのくらいあるか、可視化できたらよくね?」
ということで、最近学んだOpenCVの画像処理を用いて、
コーヒー豆の粒をカウントして、出力させてみました。
準備
正確にコーヒー豆の数量を把握したいので、
まずは、コピー用紙にぶちまけます。

いい感じにぶちまけたら、
画像処理の出力結果と実際のコーヒー豆の数を照合するために、
撮影した画像を印刷して、あらかじめカウントしておきます。

目標値は146粒です。
では、画像処理をしてカウントさせていきます。
画像処理の手順
下記の記事を参考に画像処理を進めていきました。
【Python】OpenCVでWatershedアルゴリズムと物体のセグメンテーション
ぼかし処理
コーヒー豆の画像は光の加減やコーヒー豆の表面の模様、
背景など細かい描画があります。
この、細かい描画はノイズになるため、ぼかして平滑化します。
import numpy as np
import cv2
import matplotlib.pyplot as plt
dir = "/Users/goooo/programming/test/"
def display(img,cmap=None):
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111)
ax.imshow(img,cmap=cmap)
coffee_img = cv2.imread(dir + "coffee.jpeg")
# 中央値フィルターを使ったぼかしの適用
coffee_blur = cv2.medianBlur(coffee_img ,7)
display(coffee_blur)
グレースケール
画像をモノクロに変換します。
グレースケールに変換することにより、
色の表現を真っ黒(0)から真っ白(255)の1チャンネルで表現されるため、
計算量を削減することができるらしい。
# グレースケールに変換
gray_coffee = cv2.cvtColor(coffee_blur,cv2.COLOR_BGR2GRAY)
display(gray_coffee,cmap='gray')
二値化
画像セグメンテーションの一番簡単な方法です。
0~255間の数値で指定した値を境に白(1)、それ以外を黒(0)に変換。
輪郭を検出しやすくするために、コーヒー豆を白、背景を黒で表現します。
# 2値化処理
# 画像の特徴的な部分、関心のある部分を抽出するように変換する処理
ret, coffee_thresh = cv2.threshold(gray_coffee,70,255,cv2.THRESH_BINARY_INV)
display(coffee_thresh,cmap='gray')
ここで検証
contours, hierarchy = cv2.findContours(coffee_thresh.copy(), cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
if hierarchy[0][i][3] == -1:
cv2.drawContours(coffee_img, contours, i, (255, 0, 0), 5)
display(coffee_img)
print(len(contours))
結果は、133粒
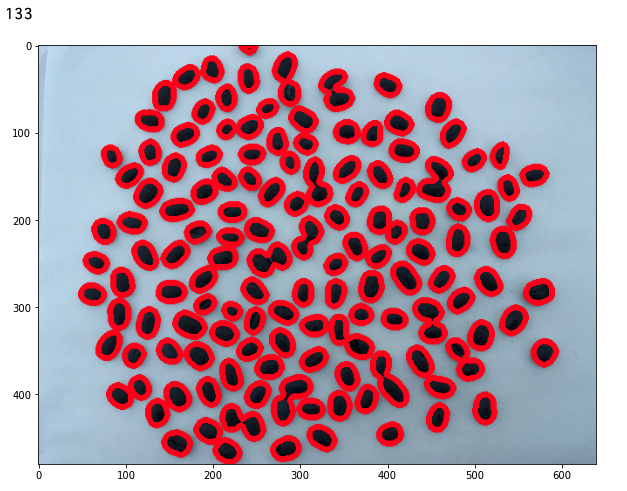
出力された画像を見てみると、
2粒のコーヒー豆を1粒と認識している箇所がいくつかあるため、
実物よりも少なく検出していたことがわかります。
なので、ここからさらに画像処理を施して、
輪郭検出の精度を上げていきます。
ノイズ除去
物体の輪郭(境界線)をきれいに取るために、モルフォロジー変換の処理を使って
オブジェクトの背景にある細かいノイズを除去します。
# ノイズ除去
# 場合によっては必要なし
kernel = np.ones((3,3),np.uint8)
opening_coffee = cv2.morphologyEx(coffee_thresh,cv2.MORPH_OPEN,kernel, iterations = 1)
display(opening_coffee,cmap='gray')
膨張処理
指定された局所領域の中で最大値のピクセル値に置き換えていくような処理です。
背景よりも物体の方がピクセル値が大きければ、
その物体の端の部分が膨らんでいくような感じになります。
# 膨張処理
coffee_bg = cv2.dilate(opening_coffee,kernel,iterations=3)
display(coffee_bg,cmap='gray')
白い部分がしっかり埋まっていれば、他が背景ということで把握できます。
前景抽出
二値画像でくっついている物体同士を分離したい場合などに使用する処理です。
距離変換で距離マップを作成し、距離に応じて二値化することで、
黒から遠いところは明るく、近いところは暗くなるというイメージになります。
この処理で、コーヒー豆だと確信できる領域を検出させます。
# 前景抽出
dist_transform = cv2.distanceTransform(opening_coffee,cv2.DIST_L2,5)
ret, sure_fg = cv2.threshold(dist_transform,0.5*dist_transform.max(),255,0)
display(dist_transform,cmap='gray')
display(sure_fg,cmap='gray')
再検証
先の検証時と同様に、輪郭を検出した数を出力します。
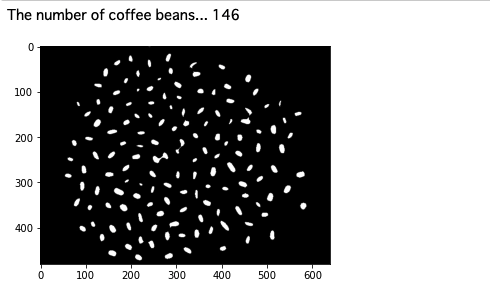
まあ、よいではないでしょうか。
微妙に分離できてないところがありますが、細かいことは気にしません![]()
・
パラメータを色々いじって、なんとか正解に近い値を出力できましたが、
前景抽出の距離変換した画像をthreshold()で二値化する際、
最大値のパラメータが検出結果に影響することがありました。
# 最大値10%~90%で検証
for num in np.arange(0.1, 1.0, 0.1):
ret, sure_fg = cv2.threshold(dist_transform,num*dist_transform.max(),255,0)
cv2.imwrite(dir + "sure_fg.jpeg", sure_fg)
img = cv2.imread(dir + "sure_fg.jpeg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 輪郭検出し、数を求める。
contours, _ = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 輪郭を構成する頂点数で誤検出を除く。
contours = list(filter(lambda cnt: len(cnt) > 30, contours))
count = len(contours)
print('{:.1f}'.format(num*100), "% >>>", "The number of coffee beans..." , count)

ラベルマーカー処理やWatershedアルゴリズムを適用
うまくいけば、コーヒー豆1粒1粒に輪郭がついてくれる予定でしたが、
若干くっついているのがあります。
が、細かいことは、気にしません。
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(coffee_bg,sure_fg)
ret, markers = cv2.connectedComponents(sure_fg)
markers = markers+1
markers[unknown==255] = 0
markers = cv2.watershed(coffee_img,markers)
display(markers)
contours, hierarchy = cv2.findContours(markers.copy(), cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
if hierarchy[0][i][3] == -1:
cv2.drawContours(coffee_img, contours, i, (255, 0, 0), 2)
display(coffee_img)

最後に
せっかくなので、検出したコーヒー豆のカウント数に応じて、
なんか表示させてみます。
コーヒー1杯に使われるコーヒー豆は、およそ90粒らしい。
なので、90粒以下の場合、こんな風に出力させました。
.
.
コーヒー飲む人からすると、
粒の数より、コーヒー豆の質量が大事なので、
今後、これを使うことはないでしょう。(なんで作ったん)
.
粒のカウントではなく、
欠点豆の判別や焙煎のムラを見るのに画像処理はいいかもしれませんね。
また、画像処理を学んで使えるようになったら挑戦してみます。