背景
Pythonでスクレイピングをやってみようと思い、
取り合えず地図画像でも集めてみようかな…ということで、
中部電力が公開している地図画像をスクレイピング。
しかし、何度やっても要素を取得してくれない。
import time
from selenium import webdriver
# IEを起動
# ドライバーの保管ディレクトリを記述
driver = webdriver.Ie("C:\\Users\\oooo\\Desktop\\Python\\IEDriverServer.exe")
# パワーグリッドにアクセス
driver.get("https://powergrid.chuden.co.jp/kisyo/")
time.sleep(5)
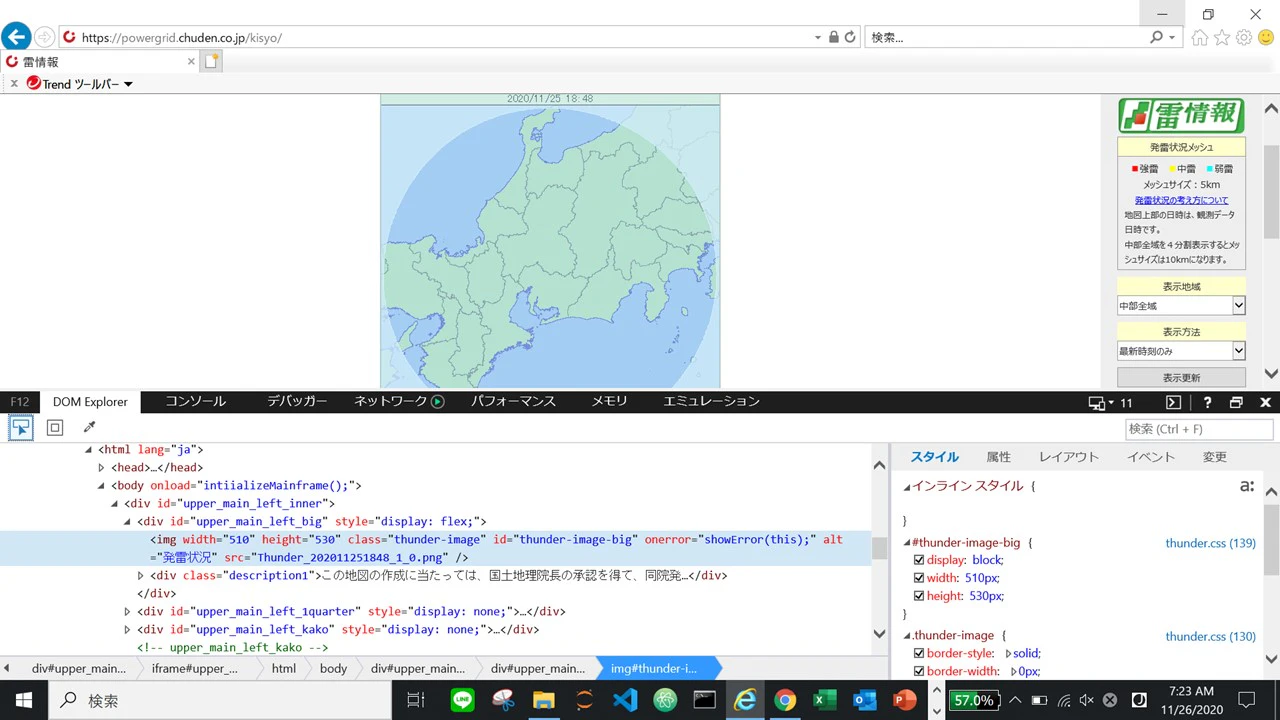
element = driver.find_element_by_css_selector("#thunder-image-big")
print(element)
>>>NoSuchElementException: Message: Unable to find element with css selector == #thunder-image-big
検証ツールを開いて地図画像の要素にあるclassやidなど該当しそうな属性を
指定して取得を試みるが、「そんなものはねぇよ」と突っぱねられます。
本当に何が原因なのかわからなかったので、teratailで質問をしたら
解決したので備忘としてこの記事を書きました。
環境
使用ブラウザ:IE11
OS:Microsoft Windows 10 Home
エディタ:Jupyter notebook
こうやったらできた(結論)
import time
from selenium import webdriver
import urllib.request
from datetime import datetime
# IEを起動
# ドライバーの保管ディレクトリを記述
driver = webdriver.Ie("C:\\Users\\oooo\\Desktop\\Python\\IEDriverServer.exe")
# パワーグリッドにアクセス
driver.get("https://powergrid.chuden.co.jp/kisyo/")
iframe = driver.find_element_by_id('upper_main_left_cont')
driver.switch_to.frame(iframe)
time.sleep(5)
element = driver.find_element_by_css_selector("#thunder-image-big").get_attribute("src")
# ファイル名を日付で保存
now = datetime.now()
urllib.request.urlretrieve(element, now.strftime('%Y%m%d_%H%M%S') + '.png')
解説
自分もまだまだ、よちよちPythonマンなので復習用に書いておきます。
モジュールをインポート
import time #時刻に関するさまざまな関数を提供
from selenium import webdriver #Webの自動テストのためのライブラリ
import urllib.request #URL を開いて読むためのモジュール
from datetime import datetime #日付や時刻を操作するためのクラスを提供
Pythonでライブラリの中のモジュールに含まれる
関数、クラスを利用するには、次のようにimportを記述し、
読み込んでから利用します。
import ライブラリ名/モジュール名
準備
Seleniumでは、PythonのコードからWEBブラウザを操作します。
操作するためには、WebDriverというものが必要になります。
下記のリンクからドライバーをインストールします。
http://selenium-release.storage.googleapis.com/index.html?path=3.9.0/

あとは、ブラウザやレジストリの設定がありますので、
こちらを参考に進めていきました。
![]() SeleniumでInternet Explorer11を動かす方法
SeleniumでInternet Explorer11を動かす方法
ブラウザの指定
driver = webdriver.Ie("C:\\Users\\oooo\\Desktop\\Python\\IEDriverServer.exe")
このようにwebdriverのIEインスタンスを作成することによって
ブラウザを操作することが可能になります。
webdriverはPATHが通ったディレクトリに配置されていないと
実行に失敗してしまうので注意してください。
例として、デスクトップの"Python"というフォルダ内に置いているので
上記のようにPATHを指定しています。
ページを開く
Seleniumのget関数を使用して、指定したページのFullPATHを記述します。
driver.get("https://powergrid.chuden.co.jp/kisyo/")
要素の指定
通常なら、find_element_by_~という関数で、適した属性
(xpath, id, cssSelecter, classNameなど)から要素を取得します。
参考記事: Selenium Python Bindings
.
しかし今回、取得したい地図画像は"iframe"という形で扱われていました。

iframeとは
別のWebページや画像などをあたかもページの要素の一つのように埋め込んで
一体的に表示することができるものです。
表示する内容はsrc属性でURLの形で指定されます。

よくある公式サイトにYouTubeの動画を表示させているあれも
iframeで構成されています。

なので、スクレイピングで画像取得できていなかったのは、
今まで要素を取得しようとしていた属性は、iframeを入れるための器であって
中身は空っぽだったからです。(間違っていたらご指摘願います)
iframeを操作できるようにする
iframeは別ウィンドウとして扱われるので、
switch_to.frameを使ってiframe側に切り替える操作をします。
iframe = driver.find_element_by_id('upper_main_left_cont') #対象のインラインフレームIDを取得
driver.switch_to.frame(iframe) #取得したインラインフレームにスイッチ
要素を取得
前の操作で、iframeを切り替えて要素の取得が出来ます。
element = driver.find_element_by_css_selector("#thunder-image-big").get_attribute("src")
例として、cssセレクタを指定することで要素を取得しています。
他にもname属性やid属性などで指定が可能です。
保存
保存するファイルのファイル名が被らないように、
要素を取得した時の日付をファイル名にして保存します。
now = datetime.now() #現在時刻を取得
urllib.request.urlretrieve(element, now.strftime('%Y%m%d_%H%M%S') + '.png')
.
urlretrieveは、ファイルをダウンロードし保存する際に使用します。
urllib.request.urlretrieve(URL, 保存先のファイル名)
.
例として、URLにあたる場所にelementという変数を置いていますが、
前述でelementの中にはdriver.find_element…で取得してきたimgURLが既に入っています。
element = driver.find_element_by_css_selector("#thunder-image-big").get_attribute("src")
print(element)
>>>https://powergrid.chuden.co.jp/kisyo/Thunder_202011281715_1_0.png
.
now.strftimeは現在時刻を字列への変換するメソッドです。
('%Y%m%d_%H%M%S')という記述は、書式化コードで
"西暦""何月""何日""何時""何分""何秒"と表示させます。
さらに、拡張子を'.png'に指定して保存します。

上手に保存ができました。