カオスエンジニアリングとは

NetflixではChaos Monkey、Gorilla、Kongなどのツールを構築することで、様々なシステム、ゾーン、さらにはリージョン全体がダウンした時に、サービスが存続可能であるように継続的にテストを行っています。
Netflixのカオスエンジニアリングの原則によると、カオスエンジニアリングの定義は以下のように記載されています。
~カオスエンジニアリングの定義~
プロダクション環境の過酷な状況に耐えられるというシステムの能力に自信を持つため、分散システムで実験するという規律
これだけ読むとよくわかりませんが、簡単にまとめると本番環境にて耐障害性テストを継続的に行うことでシステムのサービスレベルを引き上げて行きましょうという方法論のことですね。
Chaos MonkeyはSimian ArmyリポジトリでOSSで公開されています。Simian ArmyのツールにはChaos Monkeyだけではなく、以下ものが含まれています。
| 名前 | 機能 |
|---|---|
| Chaos Monkey | EC2をランダムに選び削除します |
| Chaos Gorilla | アベイラビリティゾーンを ランダムに選び削除します。 |
| Conformity Monkey | ベスト・プラクティスに従っていない インスタンスを削除します |
| Doctor Monkey | ヘルス・チェック (CPU など) を実行します |
| Janitor Monkey | 使用されていないリソースを 検索して削除します。 |
| Latency Monkey | クライアント・サーバー間の通信に 人工的に遅延を生じさせます |
| Security Monkey | 適切に構成されていないSecurityGroupなどの セキュリティーの脆弱性を検出します |
これら一連のツール群を使用し、テストを続けることで耐障害性に強いアーキテクチャを構築できますが、ツールを導入するだけでもなかなか骨が折れます。Simian Armyにはクイックスタートガイドも用意されていますが、今回はカオスエンジニアリングを体感するという目的でChaos Monkeyの簡易ツールであるChaos Lambdaを使ってみましょう。
Chaos Lambdaとは

Chaos LambdaはNetflixのカオスモンキーをLambdaによって実装した簡易ツールです。Chaos Lambdaは、いくつかのEC2を定期的に削除する機能を持ったLambda関数をデプロイします。Chaos Lambdaを使用することで、障害から正常に回復する堅牢で高可用性のシステムを構築するのに役立てることができます。
CloudWatchイベントによってスケジューリングされたタイミングでEC2インスタンスのTerminateがランダムに実行されます。Terminateの対象はタグやセキュリティグループ、オートスケーリンググループ名で指定できます。

Chaos Lambdaを使ってみる
1. CLIツールのインストール
まずはchaos-lambdaのCLIツールをインストールします。
$ npm install -g chaos-lambda
2. Lambdaに付与するIAMロールの作成
Chaos Lambda用のIAMロールを設定しておきます。
AWSのマネジメントコンソールからロールの作成を行います。
信頼されたエンティティはLambdaを選び
Chaos LambdaはEC2のdescribeやterminateを行うのでAmazonEC2FullAccessのIAMポリシーを付与しておきましょう。
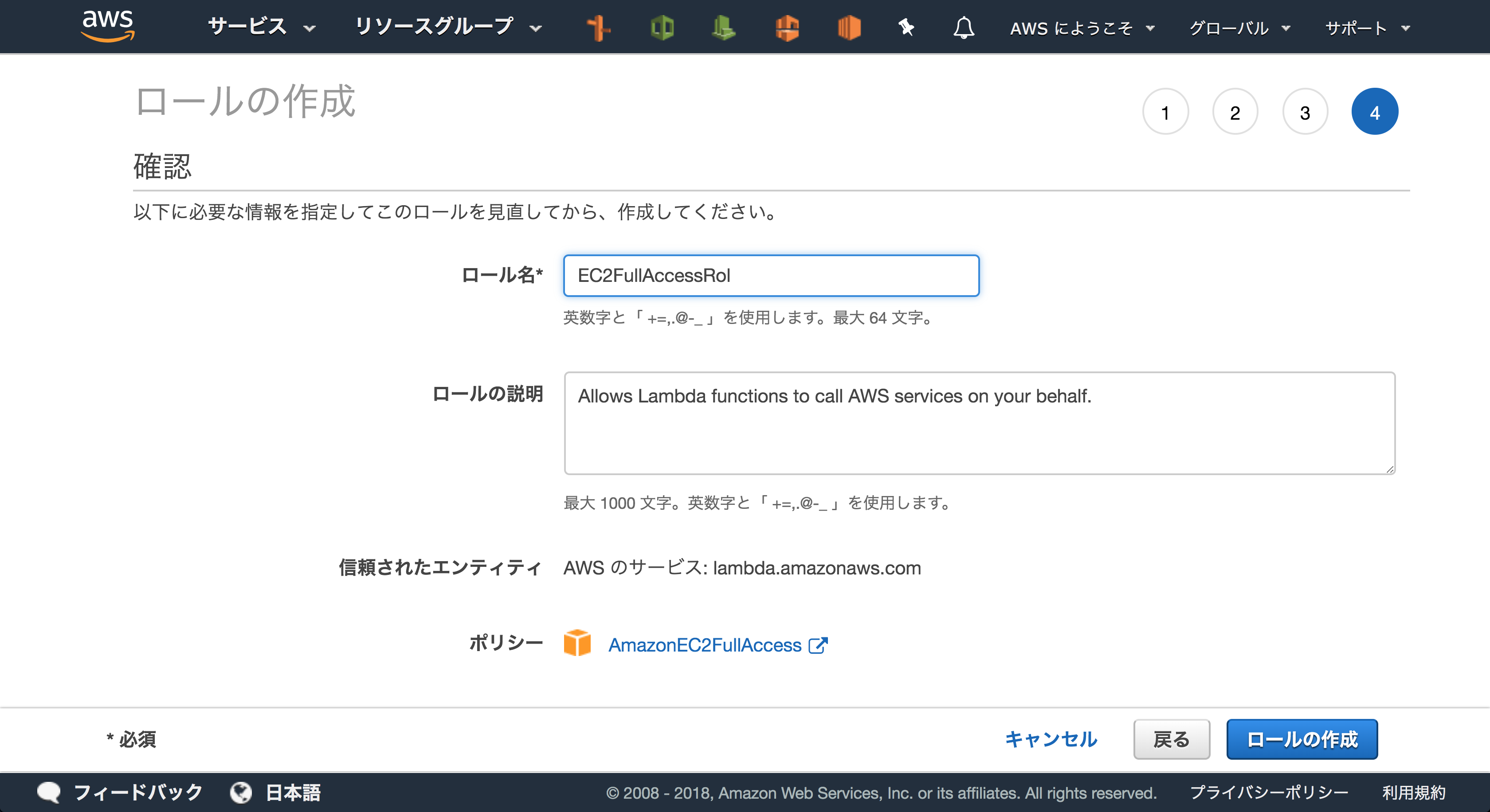
今回はEC2FullAccessRoleという名前でロールを作ることにします。
3. Lambdaをデプロイ
Chaos LambdaのLambdaファンクションをデプロイします。以下のようなコマンドでデプロイが可能です。AWS_PROFILEとAWS_REGIONを環境変数にセットしておくことでデプロイするAWSアカウント、リージョンを指定することができます。
$ chaos-lambda deploy -r $lambda-role-arn
今回はus-east-1のリージョンにデプロイします。リージョンを指定しないと、デフォルトでeu-west-1にデプロイされてしまいました。ちなみにeu-west-1は欧州 (アイルランド)です。
$ export AWS_REGION=us-east-1
$ chaos-lambda deploy -r arn:aws:iam::<AWS::AccountId>:role/EC2FullAccessRole
+ Chaos Lambda has been created
chaosLambdaという名前でデプロイされました。
正常にデプロイが完了するとchaos_lambda_config.jsonというファイルが作られます。
$ ls
chaos_lambda_config.json
$ cat chaos_lambda_config.json
{
"FunctionArn": "arn:aws:lambda:us-east-1:<AWS::AccountId>:function:chaosLambda",
"LambdaRoleArn": "arn:aws:iam::<AWS::AccountId>:role/EC2FullAccessRole"
}
この状態ですとまだスケジュールの設定も、terminateする対象のEC2インスタンスも指定されていないので安心してデプロイしてください。
↓ トリガーが設定されていない
↓ terminate対象のEC2インスタンスが指定されていない
4. terminalteの頻度と対象のEC2インスタンスの指定
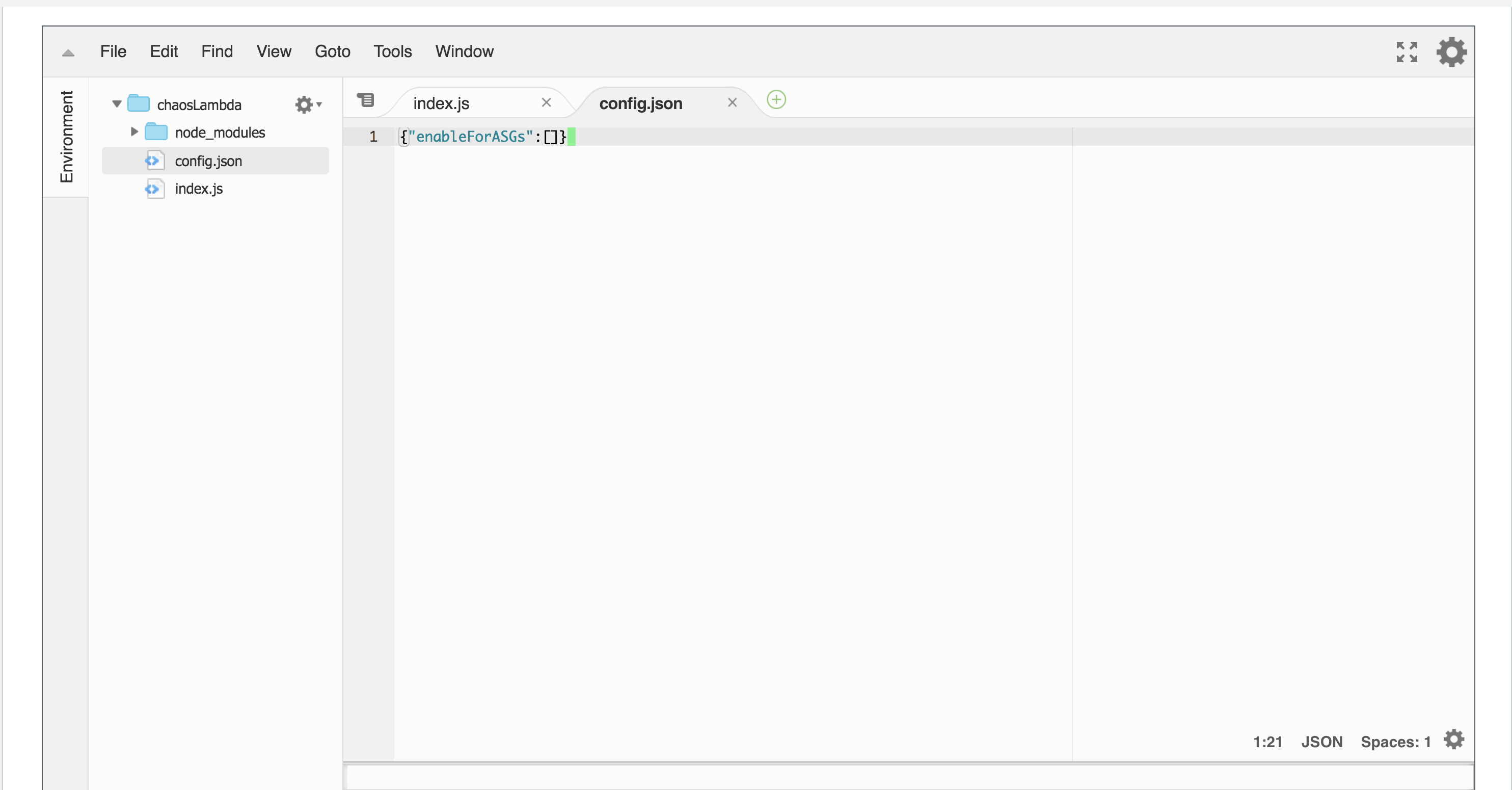
ここでようやくterminateの頻度と対象のEC2インスタンスを指定します。Chaosfile.jsonに以下のように記載しておきます。この場合10分ごとにweb-SpotInstanceWebServerGroup-AFL1107TTOVSというオートスケーリンググループから1台選びterminateします。そのほかの設定はこちらを参照してください。タグ名を指定したりSlackとWebhook連携ができるようです。
{
"interval": "10",
"enableForASGs": [
"web-SpotInstanceWebServerGroup-AFL1107TTOVS"
]
}
設定ファイルを作成したら以下のコマンドでデプロイします。
$ chaos-lambda deploy -c Chaosfile.json
CloudWatch Eventsが追加されています。
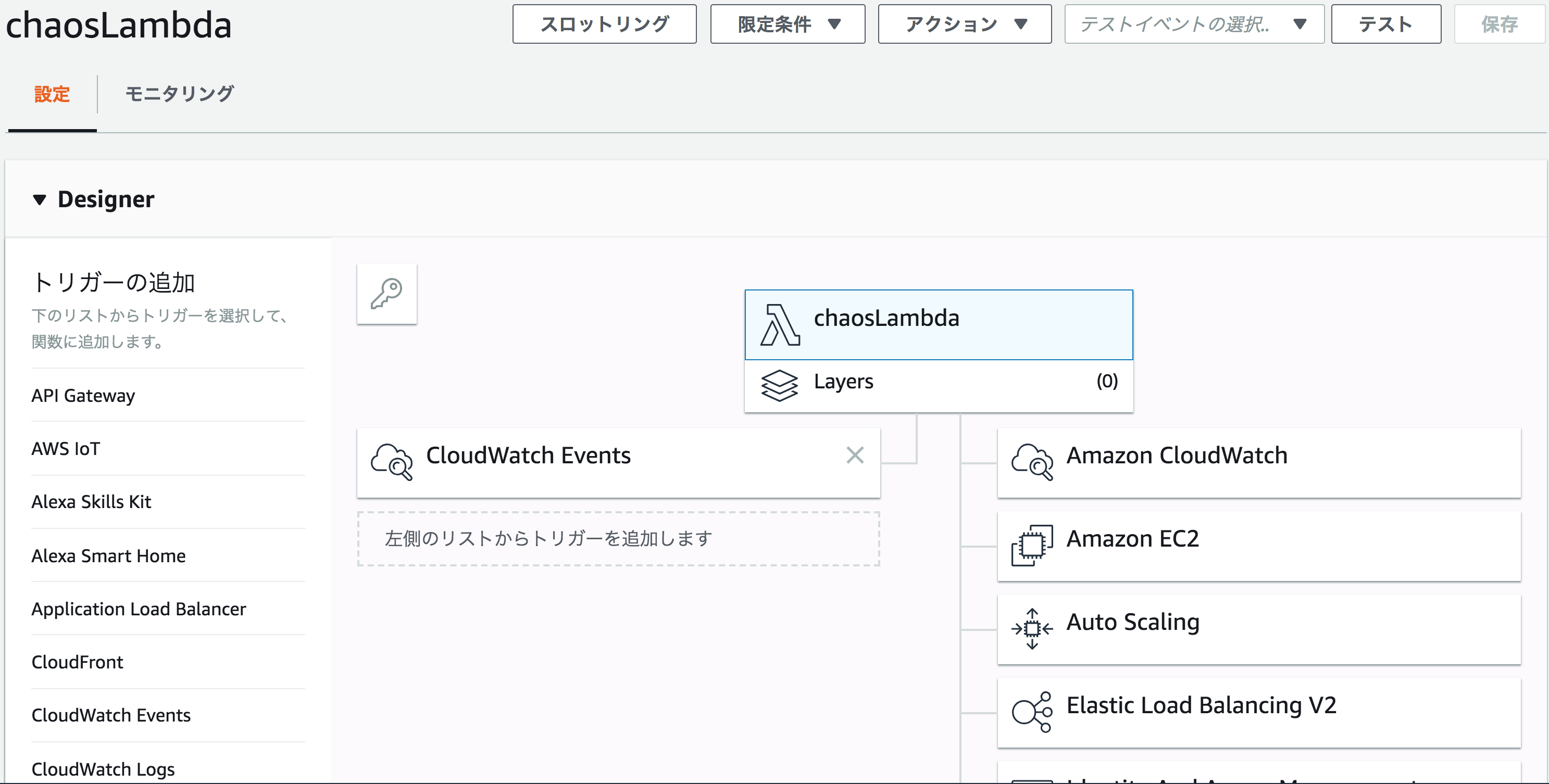
chaos_lambda_scheduleという名前でイベントが作られているようですね。
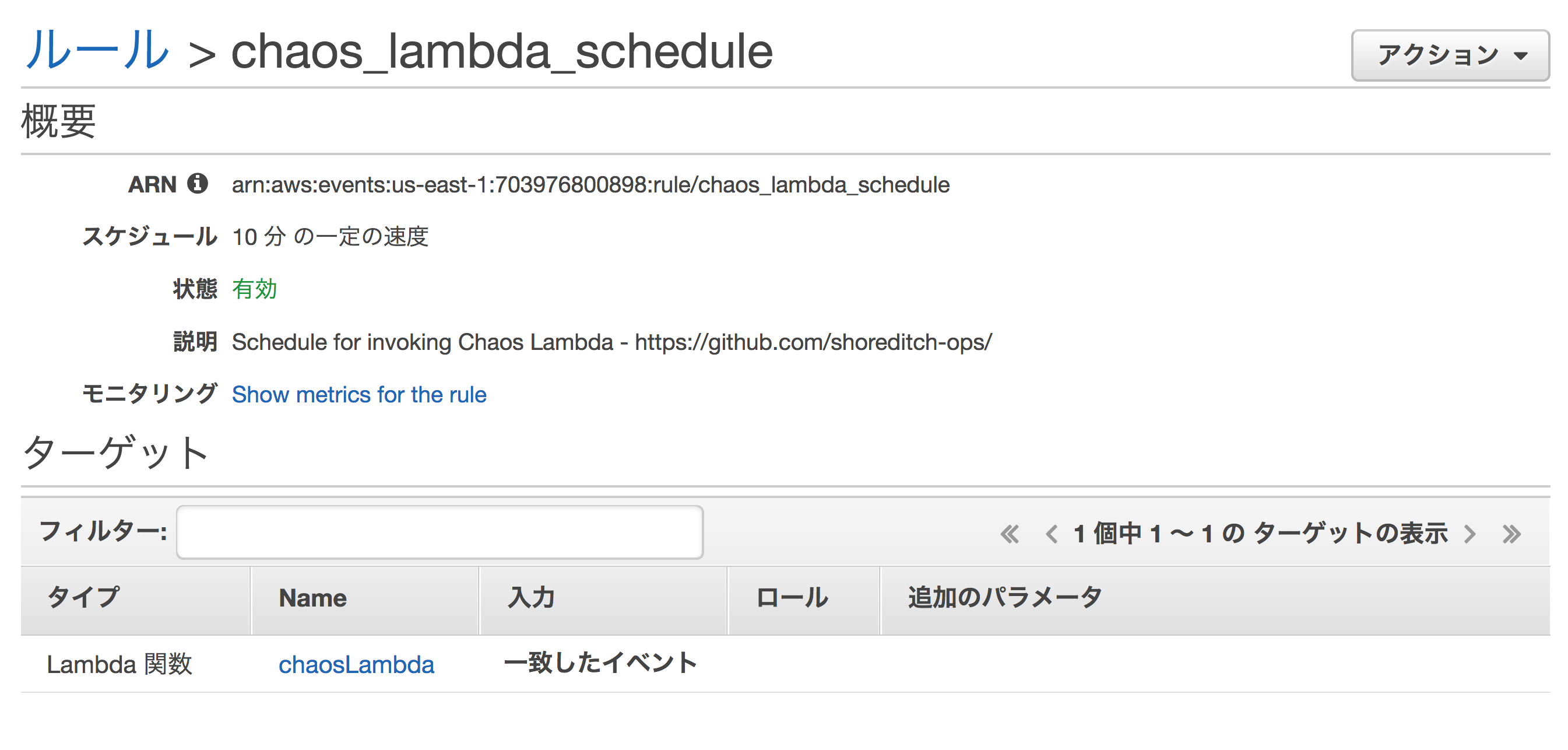
5. EC2の画面をみてみる
今回対象とするのはこちらの構成です。オートスケーリンググループ内で指定の台数のEC2が起動し、ロードバランサーに紐づけられています。ユーザはロードバランサーのURLにアクセスすることでEC2のNginxへ接続することができます。今回はEC2を2台の構成で検証してみましょう。
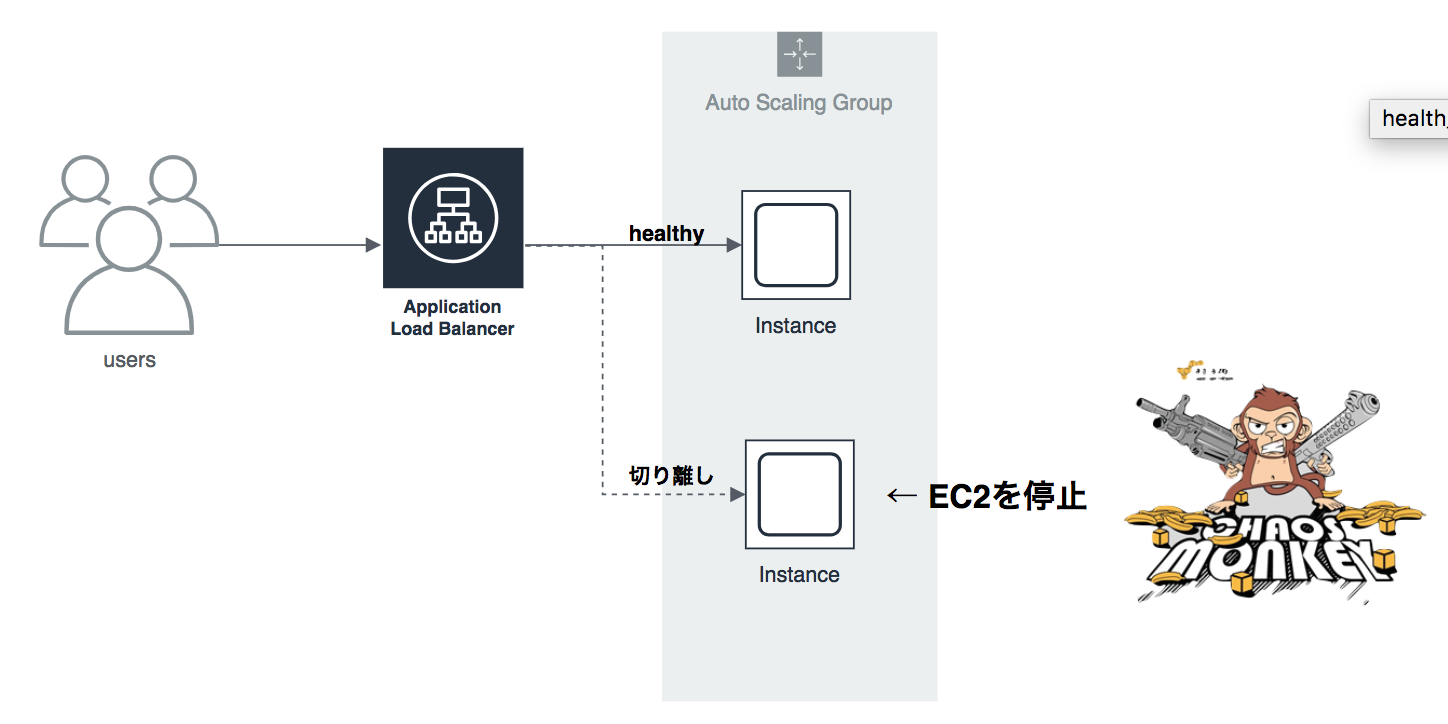
オートスケーリンググループの設定は常に2台のインスタンス数を保つように設定されています。
ロードバランサーのURLを叩くとNginxのindex.htmlを返すシンプルなアプリケーションを使用します。
しばらくするとEC2がterminateされ始めます。
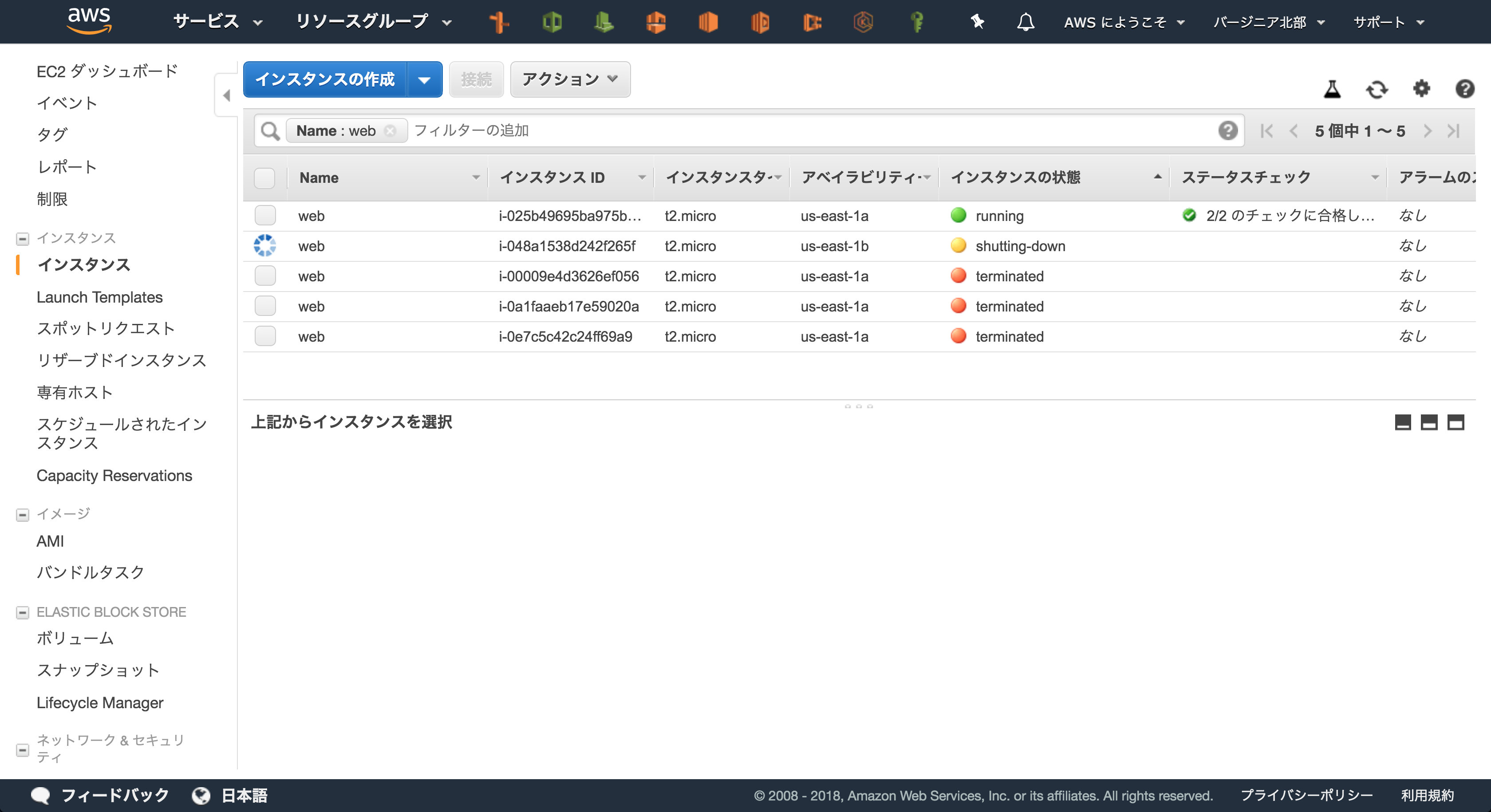
完全に削除されました。
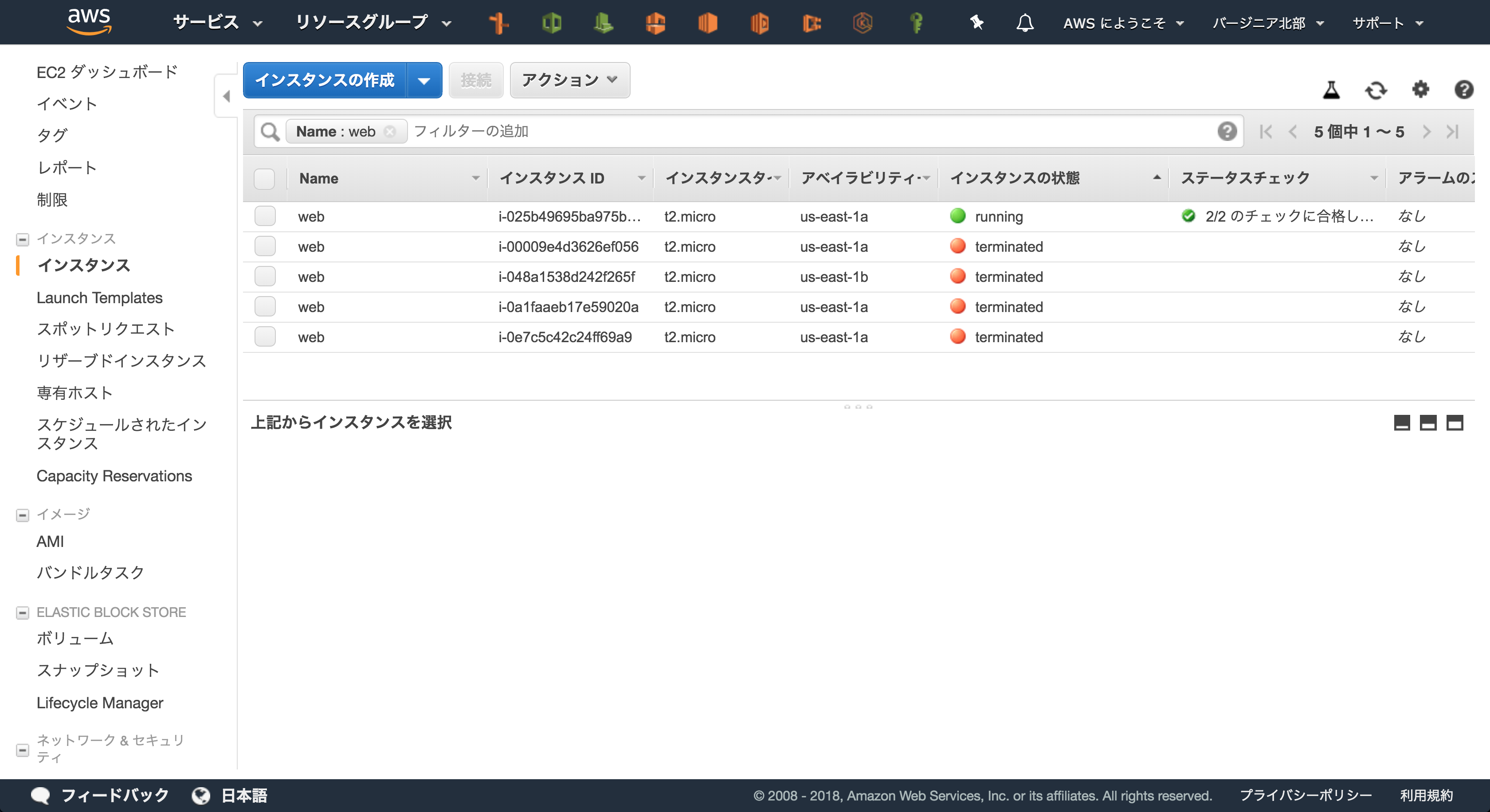
またしばらく待つとオートスケーリングの機能によって新しいインスタンスが立ち上がり始めます。
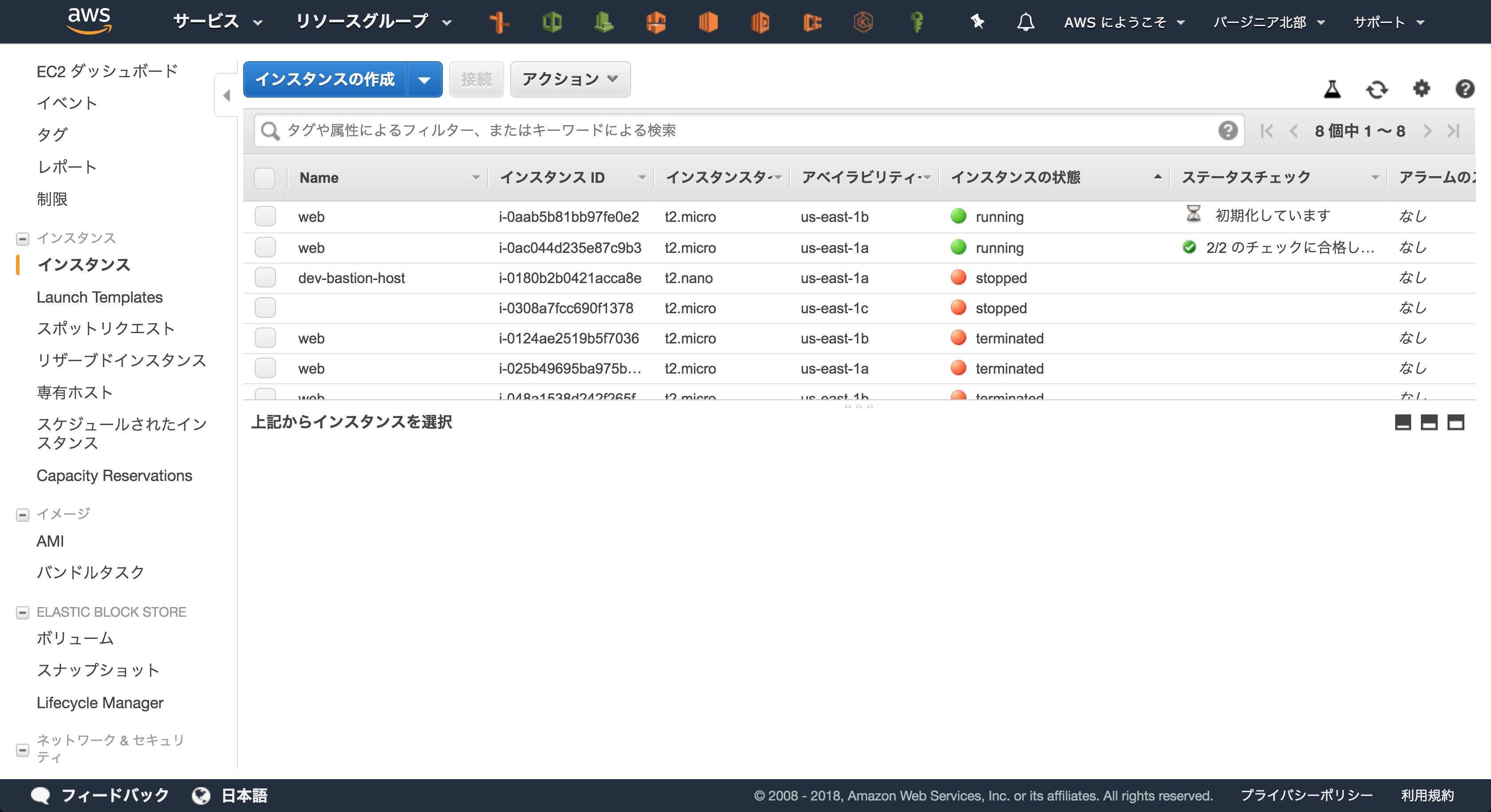
オートスケーリングの耐障害性を観測してみる
以下のスクリプトを使ってEC2が削除された時の挙動をみてみましょう。
ロードバランサーのエンドポイント(URL)にリクエストを送り、レスポンスコードと時間を計測します。
curler() {
echo "YYYY/mm/dd HH:MM:SS, http_code, time";
for i in `seq 0 100000`
do
echo -n `date +"%Y/%m/%d %H:%M:%S",` && \
echo -n " " && \
echo `curl -LI $1 -o /dev/null -w ' %{http_code}, %{time_total}\n' -s` ;
done
}
正常にEC2が起動されている間は200がレスポンスを返していることがわかります。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 17:54:08, 200, 0.458
2018/12/16 17:54:08, 200, 0.392
2018/12/16 17:54:09, 200, 0.409
2018/12/16 17:54:09, 200, 0.398
2018/12/16 17:54:10, 200, 0.402
2018/12/16 17:54:10, 200, 0.434
2018/12/16 17:54:10, 200, 0.498
2018/12/16 17:54:11, 200, 0.428
2018/12/16 17:54:11, 200, 0.424
2018/12/16 17:54:12, 200, 0.405
2018/12/16 17:54:12, 200, 0.419
2018/12/16 17:54:13, 200, 0.540
...
Chaos LambdaによってEC2がterminateされると
Chaos LambdaによってEC2が起動された時に運悪く、そのEC2にアクセスしているユーザがいた場合504エラーを返してしまうことになります。ただ、AWSのオートスケーリングは優秀ですね。即座にそのEC2にはトラフィックが流れなくなりますので次回以降のリクエストは正常にさばいていることがわかります。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 17:58:11, 200, 0.424
2018/12/16 17:58:11, 200, 0.401
2018/12/16 17:58:12, 200, 0.408
2018/12/16 17:58:12, 504, 10.384 # <-- EC2が削除された瞬間にアクセスした場合
2018/12/16 17:58:23, 200, 0.375
2018/12/16 17:58:23, 200, 0.407
2018/12/16 17:58:23, 200, 0.418
2018/12/16 17:58:24, 200, 0.393
2018/12/16 17:58:24, 200, 0.394
...
Nginxサービスが落ちたらどうか
EC2インスタンスが削除された場合はオートスケーリングの機能によって即座にトラフィックを流さなくすることがわかりました。では、何らかの理由(CPU負荷やメモリ不足)によってNginxのプロセスが動かなくなったらどうでしょうか。EC2は起動しているがNginx Serviceが止まっている状態です。では検証してみましょう。
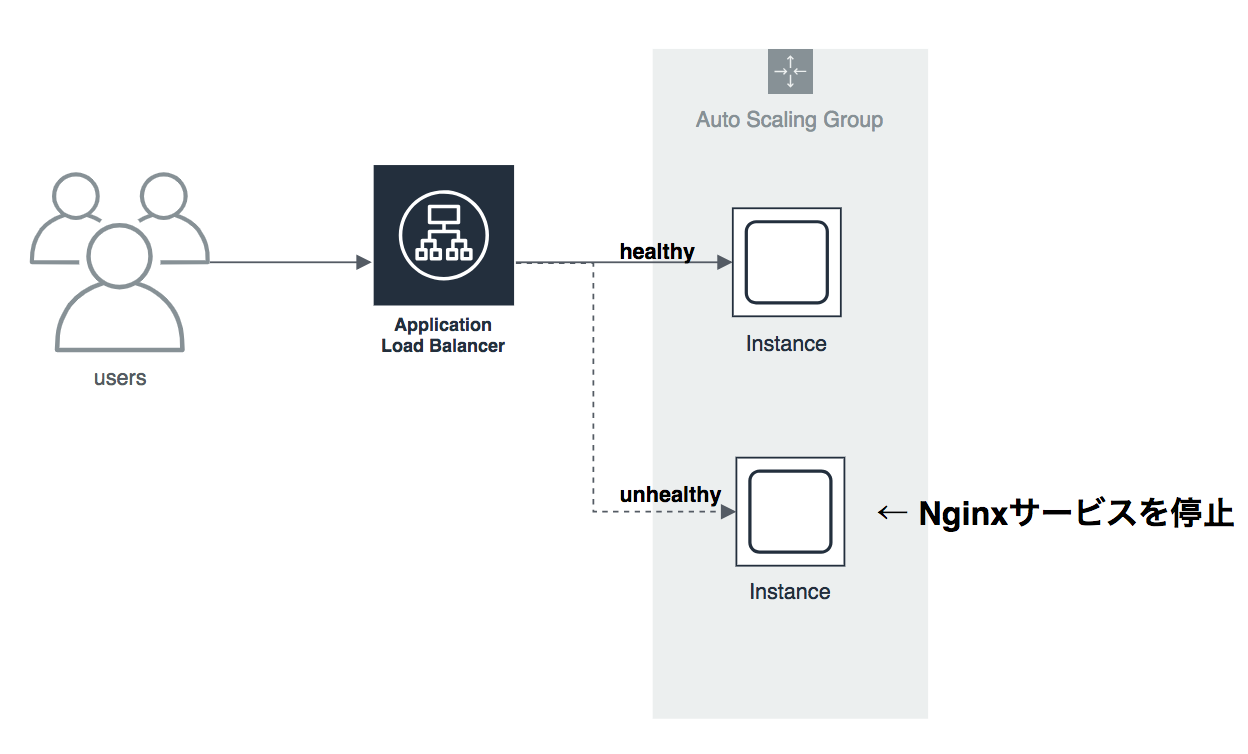
この場合はさすがにChaos Lambdaでは検証できないので無理やりEC2の中にsshで入ってNginxサービスを止めてみましょう。
[ec2-user@ip-10-192-31-22 ~]$ sudo service nginx stop
この場合だとロードバランサーのヘルスチェックで異常と判断されるまでリクエストをこのNginxが停止した状態のEC2に送り続けることになります。当然アクセスを計測してみても以下のような結果になりました。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 18:22:19, 200, 0.487
2018/12/16 18:22:20, 200, 0.430
2018/12/16 18:22:20, 200, 0.390
2018/12/16 18:22:21, 200, 0.405
2018/12/16 18:22:21, 200, 0.396
2018/12/16 18:22:21, 200, 0.412
2018/12/16 18:22:22, 200, 0.386
2018/12/16 18:22:22, 502, 0.435 # <---- ここで停止
2018/12/16 18:22:23, 200, 0.388
2018/12/16 18:22:23, 502, 0.379
2018/12/16 18:22:24, 502, 0.390
2018/12/16 18:22:24, 200, 0.386
============================================
~
~ 略 ~
~
============================================
2018/12/16 18:23:03, 502, 0.474
2018/12/16 18:23:04, 200, 0.505
2018/12/16 18:23:04, 502, 0.577
2018/12/16 18:23:05, 200, 0.531
2018/12/16 18:23:05, 502, 0.528
2018/12/16 18:23:06, 200, 0.586
2018/12/16 18:23:07, 200, 0.417
2018/12/16 18:23:07, 502, 0.415
2018/12/16 18:23:07, 502, 0.412
2018/12/16 18:23:08, 200, 0.732 # <---- 正常に復旧
2018/12/16 18:23:09, 200, 0.587
2018/12/16 18:23:09, 200, 0.580
2018/12/16 18:23:10, 200, 0.396
2018/12/16 18:23:10, 200, 0.366
2018/12/16 18:23:11, 200, 0.409
2018/12/16 18:23:11, 200, 0.416
2018/12/16 18:23:11, 200, 0.423
2018/12/16 18:23:12, 200, 0.427
2018/12/16 18:23:12, 200, 0.454
2018/12/16 18:23:13, 200, 0.430
2018/12/16 18:23:13, 200, 0.448
2018/12/16 18:23:14, 200, 0.407
2018/12/16 18:23:14, 200, 0.461
2018/12/16 18:23:15, 200, 0.425
2018/12/16 18:23:15, 200, 0.429
1分弱でアクセスを正常にさばくように復旧していることがわかります。ちなみにこれはロードバランサーのヘルスチェック機能によるもので、以下のように設定していました。
| 設定項目 | 値 |
|---|---|
| プロトコル | HTTP |
| パス | / |
| ポート | トラフィックポート |
| 正常のしきい値 | 5 |
| 非正常のしきい値 | 2 |
| タイムアウト | 5 |
| 間隔 | 30 |
| 成功コード | 200 |
30秒ごとにヘルスチェックを行い、非正常が2回連続すればそのインスタンスはUnhealthyと判断します。Unhealthyとなったインスタンスはロードバランサーのターゲットグループから切り離すという処理を行います。
逆に言えば1分間の間、リクエストを正常にさばけていないのでユーザはサービスが利用できないことになります。動画配信や公売サイトのようにユーザ満足度がすべてのWebサービスではこのようなサービスレベルでは致命的です。
ではどうするか?
ロードバランサーのヘルスチェック
まずはヘルスチェックの設定をチューニングしてみましょう。
ヘルスチェックを行う間隔を5秒、ヘルスチェックを失敗と見なすタイムアウトを2秒とします。
この設定の場合は 2秒以上レスポンスがない、あるいはレスポンスがあってもレスポンスコードが200以外であるヘルスチェックリクエストが2回続くとそのインスタンスは異常とみなし、ロードバランサーのターゲットグループから切り離します。
| 設定項目 | 値 |
|---|---|
| プロトコル | HTTP |
| パス | / |
| ポート | トラフィックポート |
| 正常のしきい値 | 5 |
| 非正常のしきい値 | 2 |
| タイムアウト | 5 → 2 |
| 間隔 | 30 → 5 |
| 成功コード | 200 |
さて、結果です。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 18:53:29, 200, 0.454
2018/12/16 18:53:29, 200, 0.447
2018/12/16 18:53:30, 200, 0.387
2018/12/16 18:53:30, 502, 0.391 # <--------- ここから停止
2018/12/16 18:53:30, 200, 0.400
2018/12/16 18:53:31, 502, 0.459
2018/12/16 18:53:31, 502, 0.409
2018/12/16 18:53:32, 200, 0.422
2018/12/16 18:53:32, 200, 0.452
2018/12/16 18:53:33, 502, 0.420
2018/12/16 18:53:33, 200, 0.489
2018/12/16 18:53:34, 502, 0.427
2018/12/16 18:53:34, 200, 0.447
2018/12/16 18:53:34, 502, 0.393
2018/12/16 18:53:35, 200, 0.403
2018/12/16 18:53:35, 502, 0.387
2018/12/16 18:53:36, 200, 0.427
2018/12/16 18:53:36, 502, 0.432
2018/12/16 18:53:37, 502, 0.406
2018/12/16 18:53:37, 200, 0.409
2018/12/16 18:53:37, 502, 0.464
2018/12/16 18:53:38, 200, 0.425
2018/12/16 18:53:38, 200, 0.403
2018/12/16 18:53:39, 502, 0.401
2018/12/16 18:53:39, 200, 0.447 # <--------- 正常に復旧
2018/12/16 18:53:40, 200, 0.453
期待通り10秒間で復旧するようになりました。今はオートスケーリンググループ2台のうち、1台のEC2に異常があった場合ですのでEC2に異常があってから復旧するまでリクエスト22回中11回の502エラーを出してしまいました。つまり10秒の間50%の確率でリクエストを正常にさばけていないことになります。このエラーの数も最小化したいので対策を練っていきましょう。
EC2の台数
EC2を2台から10台に増やしてみましょう。
この状態で1台のEC2のNginxサービスを停止すると以下のようになりました。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 19:06:14, 200, 0.381
2018/12/16 19:06:14, 502, 0.415 # <-- Nginxを停止
2018/12/16 19:06:14, 200, 0.377
2018/12/16 19:06:15, 502, 0.366
2018/12/16 19:06:15, 200, 0.381
2018/12/16 19:06:16, 200, 0.403
2018/12/16 19:06:16, 200, 0.450
2018/12/16 19:06:16, 200, 0.386
2018/12/16 19:06:17, 200, 0.410
2018/12/16 19:06:17, 200, 0.400
2018/12/16 19:06:18, 200, 0.432
2018/12/16 19:06:18, 200, 0.414
2018/12/16 19:06:19, 200, 0.411
2018/12/16 19:06:19, 200, 0.383
2018/12/16 19:06:19, 200, 0.369
2018/12/16 19:06:20, 200, 0.421
2018/12/16 19:06:20, 200, 0.386
2018/12/16 19:06:21, 200, 0.386
2018/12/16 19:06:21, 200, 0.445
2018/12/16 19:06:22, 200, 0.421
2018/12/16 19:06:22, 502, 0.425
2018/12/16 19:06:22, 200, 0.400
2018/12/16 19:06:23, 200, 0.403
2018/12/16 19:06:23, 200, 0.382
2018/12/16 19:06:24, 200, 0.421 # <-- EC2をターゲットグループから切り離す
2018/12/16 19:06:24, 200, 0.416
2018/12/16 19:06:24, 200, 0.849
2018/12/16 19:06:25, 200, 0.985
2018/12/16 19:06:26, 200, 0.745
2018/12/16 19:06:27, 200, 0.387
24回中3回エラーが発生しました。いいかえれば10秒の間12.5%の確率でリクエストを正常にさばけていないことになります。あとは理論的にはEC2の台数を増やせば、エラーとなる可能性を小さくすることができます。
それでも満足できない?
Chaos Lambdaを使ってAWSのオートスケーリング復旧時間をチューニングしてみました。
これ以上のサービスレベルを実現するにはAWSの提供しているELBのヘルスチェック機能では限界がありそうだということが見えてきました。ヘルスチェックはロードバランサーからEC2に対してhttpリクエストを送って検証します。最小の間隔が5秒×2回で異常と検知する仕組みになっていますので、最低でも10秒間は異常を検知できない期間ができてしまいます。
これを解消するためにはEC2の内部でNginxサービスを監視し、異常があれば即ロードバランサーに通知するような仕掛けを構築する必要があります。
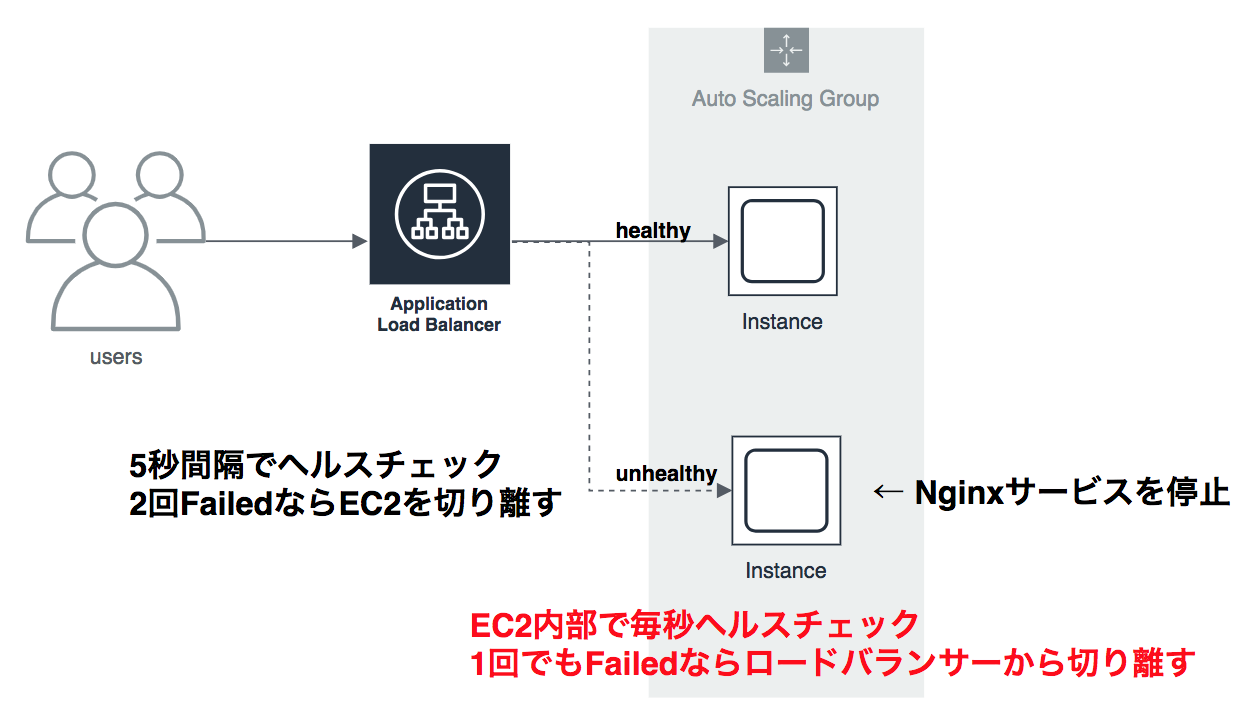
UserDataに以下のようなスクリプトを仕込んでおき、EC2起動時に実行されるようにしておきましょう。
Nginxのプロセス数を監視しておき、プロセス数が 0 となった場合EC2を削除する設定です。
# !/bin/bash
while :
do
# nginxのプロセス数をカウントする
count=`ps -ef | grep nginx | grep -v grep | wc -l`;
if [ $count = 0 ]; then
INSTANCE_ID=$(curl -s http://169.254.169.254/latest/meta-data/instance-id);
/usr/bin/aws ec2 terminate-instances --instance-ids $INSTANCE_ID;
fi
done
さて、この状態でNginxを停止してみましょう。結果以下のようになりました。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 21:01:42, 200, 0.615
2018/12/16 21:01:43, 200, 0.416
2018/12/16 21:01:43, 200, 0.524
2018/12/16 21:01:44, 502, 0.513 # <-- Nginxサービスを停止
2018/12/16 21:01:44, 502, 0.457
2018/12/16 21:01:45, 200, 0.447
2018/12/16 21:01:45, 502, 0.490
2018/12/16 21:01:46, 200, 0.448
2018/12/16 21:01:46, 502, 0.504
2018/12/16 21:01:47, 200, 0.608
2018/12/16 21:01:47, 200, 0.494
2018/12/16 21:01:48, 502, 0.464
2018/12/16 21:01:48, 200, 0.417
2018/12/16 21:01:49, 502, 0.406
2018/12/16 21:01:49, 200, 0.508
2018/12/16 21:01:50, 502, 0.545
2018/12/16 21:01:50, 200, 0.575 # <-- EC2の削除が開始されトラフィックが流れなくなる
2018/12/16 21:01:51, 200, 0.493
5~6秒後に異常なEC2にトラフィックが流れなくなりました。
これならなかなか使えそうです。
10台に増やして検証してみましょう。
$ curler http://dev-web-alb-1074822814.us-east-1.elb.amazonaws.com
YYYY/mm/dd HH:MM:SS, http_code, time
2018/12/16 21:13:59, 200, 0.386
2018/12/16 21:13:59, 200, 0.406
2018/12/16 21:14:00, 200, 0.425
2018/12/16 21:14:00, 200, 0.417
2018/12/16 21:14:01, 200, 0.408
2018/12/16 21:14:01, 200, 0.405
2018/12/16 21:14:01, 200, 0.407
2018/12/16 21:14:02, 200, 0.404
2018/12/16 21:14:02, 200, 0.382
2018/12/16 21:14:03, 200, 0.393
2018/12/16 21:14:03, 200, 0.391
2018/12/16 21:14:04, 200, 0.437
2018/12/16 21:14:04, 200, 0.390
2018/12/16 21:14:05, 502, 0.388 # <-- エラーとなったのはこの瞬間だけ
2018/12/16 21:14:05, 200, 0.435
2018/12/16 21:14:06, 200, 0.408
2018/12/16 21:14:06, 200, 0.504
2018/12/16 21:14:07, 200, 0.397
2018/12/16 21:14:07, 200, 0.430
2018/12/16 21:14:08, 200, 0.385
2018/12/16 21:14:08, 200, 0.411
2018/12/16 21:14:08, 200, 0.409
2018/12/16 21:14:09, 200, 0.437
2018/12/16 21:14:09, 200, 0.419
10秒の間に1回/24回エラーとなりました。エラーとなる確率を**12.5% → 4%**にまで落とすことができました。
さいごに
今回、ChaosLambdaをはじめとしてカオスエンジニアリングのテクニックをほんの少し体感してみました。
対象とするアプリケーションがNginxだけですから非常にシンプルに実装することができました。
マイクロサービスが主流のこの時代において、各サービスを復旧可能にする。さらには最大限サービスが利用可能な状態に保つ技術は、もはや必須かと思います。次回はカオスゴリラ、カオスコングにトライしてみることにします。