
現代の Web アプリケーションにおいて、キャッシュはもはや不可欠と言っていいくらい需要な技術でしょう。アプリケーションの負荷を軽減し、ユーザーへのレスポンスを高めます。
本記事では Node.js (Typescript) を使用したバックエンド API を実装する際に、どのようなキャッシュのテクニックが使えるか解説します。
※なお、説明の簡略化のためエラーハンドリングなどは省略しています。
Node.js を使用した非同期バッチパターンとキャッシュ機構
本章では以下の3つの実装パターンを比較し、Node.js を使用したキャッシュを実装していきます。
- キャッシュのないサンプルアプリケーション
- 非同期バッチ処理パターン
- キャッシュパターン
1. キャッシュのないサンプルアプリケーション
キャッシュの実装をする前に、簡単な Web API で提供されるアプリケーションを考えます。
例えば、チーム参加型の競技において個人の点数をチーム毎に集計するような機能を実装するとしましょう。
データベースには以下のように、名前、チーム名, 点数が含まれています。
このデータから点数を集計して返却しましょう。
export const data = [
{ name: "bob", team: "A", point: 30 },
{ name: "sam", team: "A", point: 83 },
{ name: "john", team: "B", point: 22 },
{ name: "mark", team: "B", point: 30 },
{ name: "tanaka", team: "C", point: 10 },
{ name: "steven", team: "C", point: 52 }
];
このアプリケーションはクエリパラメータにチーム名を指定すると、そのチームの合計点数を返却します。
import * as http from "http";
import * as url from "url";
import totalScore from "./totalScore";
http
.createServer(async (req, res) => {
const query = url.parse(req.url, true).query;
const sum = await totalScore(query.team);
res.writeHead(200);
res.end(`チーム${query.team}の合計点数は${sum}です。\n`);
})
.listen(8080, () => {
console.log("server is now listening htttp://localhost:8080");
});
キャッシュの効果を体感するために、わざと合計する処理に時間がかかるようにしておきます。今回は簡単な機能を実装していますが、実際の世界では複雑な計算をすることが多いでしょう。サーバサイドの処理で 5 秒かかってしまうアプリケーションは正直使い物になりませんね。キャッシュの仕組みを理解するには十分な題材です。
import { data } from "./data";
const sleep = msec => new Promise(resolve => setTimeout(resolve, msec));
const total = (team: string) => {
let sum = 0;
for (const item of data) {
if (item.team === team) sum += item.point;
}
return sum;
};
export default (team: string): Promise<number> => {
return new Promise(async (resolve, reject) => {
console.log(`チーム: ${team} の集計処理を開始します。`);
const sum = total(team);
// 無理やり時間がかかる処理に偽装する
await sleep(5000);
console.log(`チーム: ${team} の集計処理が完了しました。`);
resolve(sum);
});
};
それでは実際に動作を確認してみましょう。以下では、3つのクライアントがサーバに対してリクエストを送っています。それぞれ独立して処理が実行されていることが確認できます。

さて、ここまでの処理の流れを整理しておきましょう。複数のクライアントからの処理はそれぞれ独立して実行されています。つまりクライアント A からのリクエストもクライアント B からのリクエストも同様に 5 秒ずつかかっているのです。

2. 非同期バッチ処理パターン
それではキャッシュを導入する前に、まずは Node.js 特有の非同期処理に目をつけて非同期バッチパターンを実装してみましょう。
同じ API に対して複数の非同期処理の呼び出しがある場合、呼び出される処理をバッチ処理としてしまおうという発想です。非同期処理が終わらないうちにもう一度同じ非同期処理を呼び出すなら、新しいリクエストを作成するのではなく、すでに実行中のバッチの処理結果を返すような仕組みです。
処理の流れは以下のようになります。

この方法は極めてシンプルでありながら、アプリケーションの負荷を抑えつつキャッシュ機構を使う必要がありません。さて、実際に実装の流れを確認していきましょう。まずは Batch を呼び出す Handler の実装方法を考えます。
API が呼び出された時に、すでに実行中の処理があれば、コールバック関数をキューに追加します。このコールバック関数はチームの点数の集計結果を返します。非同期処理が完了した時点で、キューに保存された全てのコールバック関数を呼び出します。この結果、同じリクエストを送ってきた全てのクライアントに対して一斉にレスポンスを返却できます。
import totalScore from "./totalScore";
const queues = {};
export default async (team: string, callback) => {
// 他のリクエストによってすでにキューに入っている場合は、自身のリクエストも同じキューに入れるだけ
if (queues[team]) return queues[team].push(callback);
queues[team] = [callback];
const score = await totalScore(team);
// キューに入っている全ての callback 関数に計算結果を渡す
queues[team].forEach(cb => cb(null, score));
// キューのクリア
queues[team] = null;
};
Batch の Handler を実装したので、リクエストを受けつける箇所からの呼び出し方も少し変えなければいけません。大した変更ではありませんね。
import * as http from "http";
import * as url from "url";
import totalScoreBatchHandler from "./totalScoreBatchHandler";
http
.createServer(async (req, res) => {
const query = url.parse(req.url, true).query;
totalScoreBatchHandler(query.team, (err, sum) => {
res.writeHead(200);
res.end(`チーム${query.team}の合計点数は${sum}です。\n`);
});
})
.listen(8080, () => {
console.log("server is now listening htttp://localhost:8080");
});
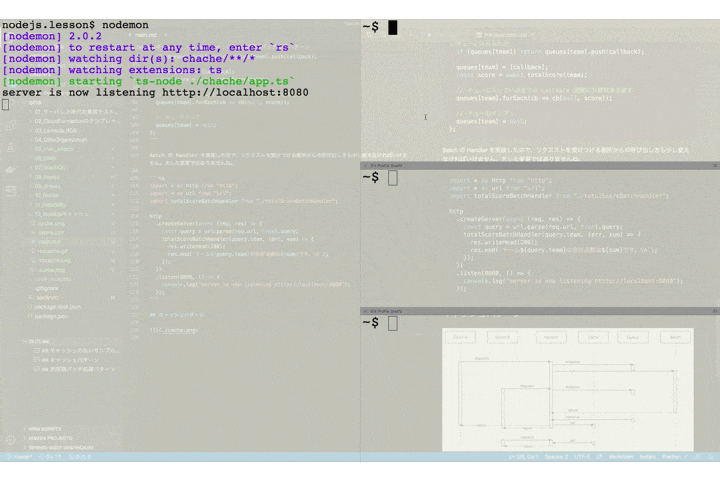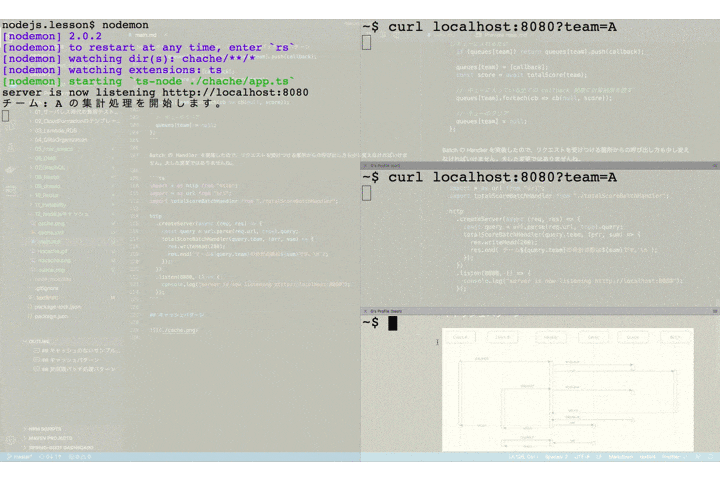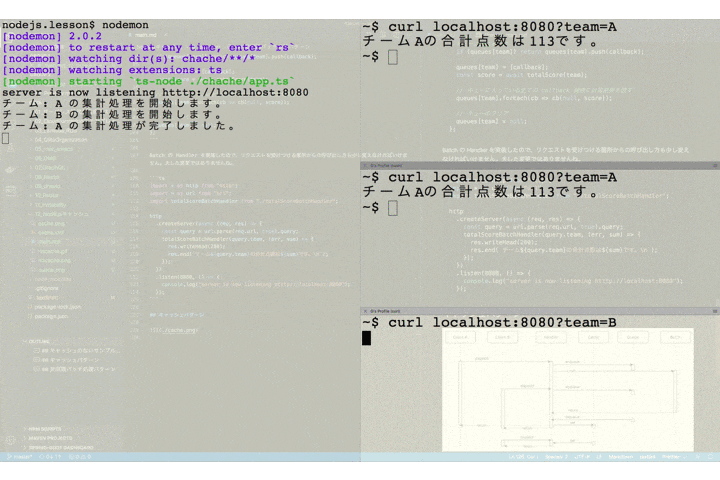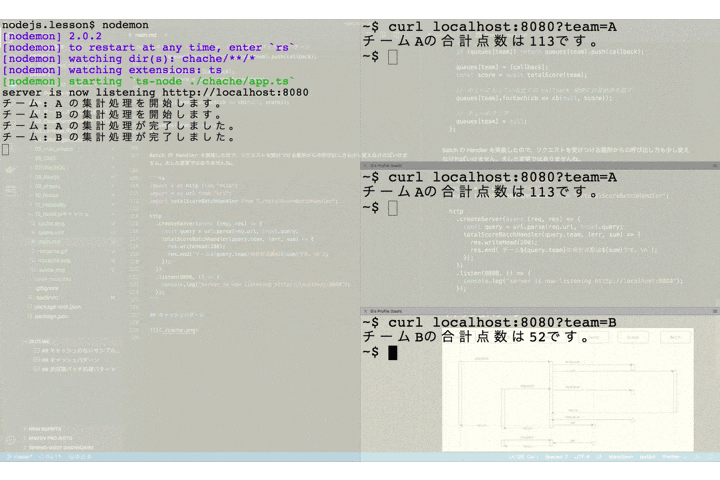
アプリケーションの振る舞いを確認してみましょう。ここで、2つのクライアントはチーム A をクエリパラメータに指定し、1つのクライアントはチーム B をクエリパラメータに指定していることに注目して下さい。
チーム A を指定したリクエストが送られたあとで、2番目のクライアントが同じくチーム A を指定してリクエストを送っています。サーバのログには集計バッチ処理の開始と終了を出力するようにしていますが、チーム A の集計処理開始のログは1つしか出ていません。これは2番目のリクエストによる新たなバッチは起動されず、キューにコールバック関数が保存されるだけとなっているためです。
そして、1、2 番目のリクエストは(ほぼ)同時に 2 つのクライアントにレスポンスが返却されています。
3. キャッシュパターン
さあ、キャッシュを導入していきましょう。非同期バッチ処理パターンだけでも強力なテクニックでしたが、キャッシュを導入することでよりアプリケーションの負荷を減らし、スループットを向上させます。
非同期バッチ処理パターンよりも考え方は簡単かもしれません。処理が終わったものをキャッシュに有効期限つきで保存するだけです。
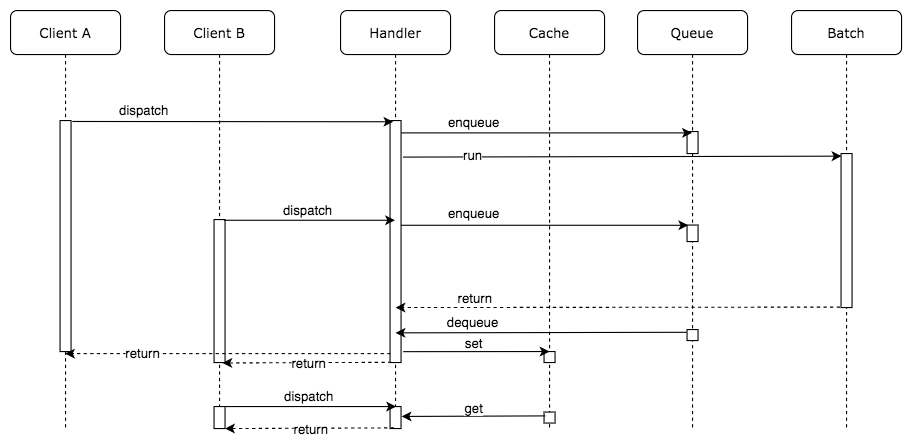
先ほどの Handler にキャッシュの機構を足していきます。集計処理が終わったら結果を一意なキー付きで Cache に格納します。一意となるキーは今回の場合、チーム名とします。キャッシュの保持期間は 10 秒とし、保持期間のうちに再度同じパラメータのリクエストがあった場合は Cache から値を取得してクライアントに返却します。
実際のユースケースではアプリケーションサーバはスケールアウトし、複数のプロセスに分散していることが一般的です。その場合は永続化する共有領域を Redis や memcached などに持たせることが好まれます。今回は説明を簡単にするため、グローバル変数にキャッシュを持つことにします。
import totalScore from "./totalScore";
const queues = {};
const cache = {};
export default async (team: string, callback) => {
if (cache[team]) {
console.log(`キャッシュ ${team}: ${cache[team]} にヒットしました。`);
return process.nextTick(callback.bind(null, null, cache[team]));
}
// 他のリクエストによってすでにキューに入っている場合は、自身のリクエストも同じキューに入れるだけ
if (queues[team]) return queues[team].push(callback);
queues[team] = [callback];
const score = await totalScore(team);
// キューに入っている全ての callback 関数に計算結果を渡す
queues[team].forEach(cb => cb(null, score));
// キューのクリア
queues[team] = null;
// キャッシュの保存
cache[team] = score;
// キャッシュの削除予約
scheduleRemoveCache(team);
};
function scheduleRemoveCache(team: string) {
function delteCache(team) {
console.log(`キャッシュ ${team}: ${cache[team]} を削除します`);
delete cache[team];
}
// 10 秒したらキャッシュを削除
setTimeout(() => delteCache(team), 10 * 1000);
}
実行してみると、その効果を体感できます。非同期バッチ処理パターンはそのまま保っています。さらに処理結果をキャッシュに保存することで、キャッシュの保持期間(10 秒間)は即座にレスポンスを返却できていることがわかります。また、実際に合計値計算を行わないためアプリケーションの負荷も下がることが期待されます。

それぞれの手法を評価する
最後に3つの実装方法でどの程度パフォーマンスに差が出るのか確認してみましょう。
検証には artillery を使用します。
秒間 100 リクエストが 10 秒間、合計 1000 リクエスト発生するように負荷をかけていきます。
$ artillery quick -d 10 -r 100 -o cache.json http://localhost:8080/?team=A
結果は以下のようになりました。
| No | バッチ処理 | キャッシュ | RPS | 最小(ms) | 最大(ms) | 平均(ms) |
|---|---|---|---|---|---|---|
| 1 | なし | なし | 66.8 | 5003.6 | 5029.1 | 5006 |
| 2 | あり | なし | 90.5 | 345.2 | 5340.8 | 2955.1 |
| 3 | あり | あり | 95.6 | 3.1 | 5021.9 | 325.8 |
テスト結果の詳細結果(クリックして開く)
1. キャッシュのないサンプルアプリケーション
All virtual users finished
Summary report @ 22:49:31(+0900) 2020-03-14
Scenarios launched: 1000
Scenarios completed: 974
Requests completed: 974
RPS sent: 66.8
Request latency:
min: 5003.6
max: 5029.1
median: 5006
p95: 5009.5
p99: 5017.5
Scenario counts:
0: 1000 (100%)
Codes:
200: 974
Errors:
ENOTFOUND: 26
2. 非同期バッチ処理パターン
Summary report @ 22:51:21(+0900) 2020-03-14
Scenarios launched: 1000
Scenarios completed: 975
Requests completed: 975
RPS sent: 90.5
Request latency:
min: 345.2
max: 5340.8
median: 2955.1
p95: 4904.8
p99: 5027.1
Scenario counts:
0: 1000 (100%)
Codes:
200: 975
Errors:
EMFILE: 15
ENOTFOUND: 10
3. キャッシュパターン
Summary report @ 22:53:23(+0900) 2020-03-14
Scenarios launched: 1000
Scenarios completed: 974
Requests completed: 974
RPS sent: 95.6
Request latency:
min: 3.1
max: 5021.9
median: 325.8
p95: 4610.3
p99: 4988.9
Scenario counts:
0: 1000 (100%)
Codes:
200: 974
Errors:
ENOTFOUND: 26
想定通り、キャッシュがあるの場合は最小数 ms でレスポンスを返却できています。あたりまえの話ですが、どの手法を使っても最大(ms)は 5 秒から変わりません。いくらキャッシュを使用しても、本来時間がかかる処理時間は減らないのです。キャッシュがない状態で受けたリクエストに対してはどうしても計算時間がかかってしまいます。ではこの課題に対する解決策はどのように考えたらよいでしょうか?
答えはいくつか考えられます。
-
本来時間がかかっている処理を見直す
DB からの取得がボトルネックであれば、DB のインデックスや検索条件をチューニングする。
アプリケーションの集計処理が雑なロジックの場合、高速化が見込めないか検討する。 -
別プロセスで実行するバッチ処理に任せる
リクエストを受けてから計算するのではなく、事前に計算しておいた結果をキャッシュ用データストアに保存しておく。
この方式を採用する場合、ほぼ全てのクエリパラメータに対してバッチによる計算処理を実行するため、よほどサーバリソースが豊富に使用できる場合に限られる。また、リクエストの多いクエリパラメータを判定し、優先度をつけてバッチ処理をするなどの複雑な機構が要求される。
今回は別プロセスで実行するバッチ処理に任せる方式を実装してみましょう。実行するマシン(あるいはプロセス)が異なるため、グローバル変数にキャッシュを持たせている今の仕組みは使えません。今こそ Redis を使用する時がきました。
Redis を使用して分散システムに対してキャッシュの機構を作る
スケーラブルなバッチ処理を行うために必要な永続化ストレージとして Redis を採用します。今回は Docker 上でオーケストレーションされるインフラを想定して、Redis は Docker コンテナで起動することとします。
$ docker run --name some-redis -d redis -p 6379:6379
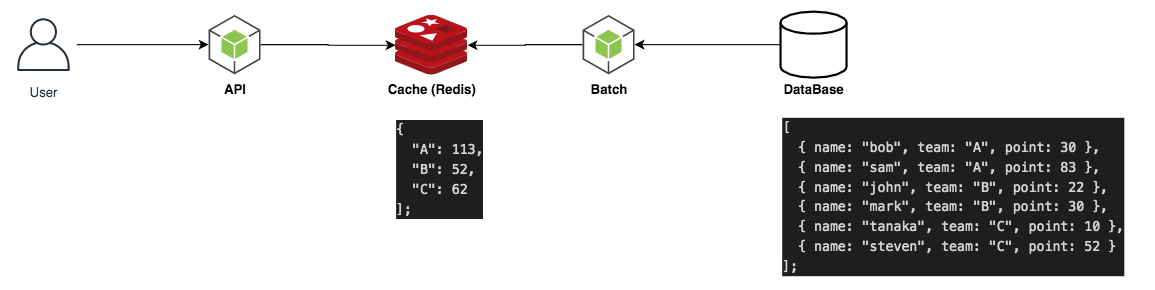
起動された Redis に対して、JavaScript からアクセスしましょう。まずはクライアントライブラリをインストールします。
$ npm install redis
いままでグローバル変数でキャッシュさせていた部分を Redis に接続するように変更するだけです。コールバック関数を Promise に変換する便利なライブラリ util/promisify を使用しています。コールバック関数で実装されている非同期処理を自分でラップして実装する手間が省けて便利です。
import totalScore from "./totalScore";
import * as redis from "redis";
import { promisify } from "util";
const client = redis.createClient();
const getAsync = promisify(client.get).bind(client);
const setAsync = promisify(client.set).bind(client);
const delAsync = promisify(client.del).bind(client);
const queues = {};
export default async (team: string, callback) => {
const cache = await getAsync(team);
if (cache) {
console.log(`キャッシュ ${team}: ${cache} にヒットしました。`);
return process.nextTick(callback.bind(null, null, cache));
}
// 他のリクエストによってすでにキューに入っている場合は、自身のリクエストも同じキューに入れるだけ
if (queues[team]) return queues[team].push(callback);
queues[team] = [callback];
const score = await totalScore(team);
// キューに入っている全ての callback 関数に計算結果を渡す
queues[team].forEach(cb => cb(null, score));
// キューのクリア
queues[team] = null;
// キャッシュの保存;
setAsync(team, score);
// キャッシュの削除予約;
scheduleRemoveCache(team);
};
async function scheduleRemoveCache(team: string) {
function delteCache(team) {
console.log(`キャッシュ ${team} を削除します`);
delAsync(team);
}
setTimeout(async () => delteCache(team), 30 * 1000);
}
バックエンドで完全に独立したバッチを実行する
さて、これで分散システムにおけるキャッシュ機構の準備が整いました。バックエンドで完全に独立して実行されるバッチを記述しましょう。
ここでは簡単のために node-cron ライブラリを使用して cron 実行することにしています。
サーバの cron によって実現したり、AWS であれば CloudWatch Events 、GCP であれば Cloud Scheduler などを使用すると良いでしょう。スケジューラとバッチ処理を分離することで、バッチ処理するサーバを常に起動することなく必要なときだけ立ち上げる構成を取ることができます。コンピューティング環境には Lambda や CloudFunction などの FaaS を使用しても良いでしょう。
import totalScoreBatchHandler from "./totalScoreBatchHandlerRedis";
const main = () => {
["A", "B", "C"].forEach(team => {
totalScoreBatchHandler(team, (err, sum) => {
console.log(`バッチ処理が完了しました。`);
console.log(`チーム${team}の合計点数は${sum}です。`);
});
});
};
const cron = require("node-cron");
cron.schedule("*/10 * * * * *", () => main());
結果は以下のようになりました。完全にバックグラウンドでバッチを独立して実行させることにより、常にキャッシュがある状態でユーザリクエストを受け付けることができるようになりました。実際のユースケースでは今回の例のようにチームが 3 つしかないような理想的な条件ではないでしょう。その場合はリクエストが多く集中するデータを優先的にキャッシュするような機構を考える必要がある場合もあるでしょう。
| 実装方式 | RPS | 最小(ms) | 最大(ms) | 平均(ms) |
|---|---|---|---|---|
| 従来のキャッシュ方式 | 95.6 | 3.1 | 5021.9 | 325.8 |
| 完全にバッチを独立させる | 95.5 | 5.7 | 139.3 | 9 |
最終的な構成はこのようになりました。複数のサーバが共有できるキャッシュ用の永続化ストレージを Redis を使用することで実現しました。あとは API サーバへのリクエストを LoadBalarncer によって分散させることでスケーラブルな Web API にできます。

以上が Node.js を使用したキャッシュの基本的な考え方と戦略です。最後に説明したバッチをバックグラウンドで処理する方法は、場合によっては求められる要件に対してオーバーエンジニアリングとなることもあるでしょう。ユーザリクエストが秒間 200~300 程度であれば特に気にする必要はないかもしれませんが、秒間 1000 リクエストを超えたあたりからキャッシュとは真剣に向き合わなければいけません。適切な構成を採用し、サイトのパフォーマンスを上げていきたいですね。