この記事は AWS Containers Advent Calendar 2021 の22日目の記事です。
この記事では、 AWS Fault Injection Simulator(AWS FIS) を使ってAmazon ECS のワークロードにカオスエンジニリングによる実験を行う方法の基礎をご紹介します。
前置き
本記事の前提条件になる知識や参照いただくたいリンクを記載します。(主にカオスエンジニアリングや、AWS FIS についての基本的なご紹介ですので、すでにご存知の方は読み飛ばしてください)
カオスエンジニアリングとは
カオスエンジニアリングは、Netflix 社がクラウド上で分散したアプリケーションを構築していく中で始めた、本番環境に意図的に障害を注入して、その際のアプリケーションやシステムの挙動を観察する実験を通して、システムの可用性や信頼性を高めていくプラクティスです。
複雑化し、常に変化していくクラウド上での分散システムにおいて、アプリケーションやシステムの振る舞い全てを事前に予測し、テストすることは現実的ではありません。このような予測不可能なシステムを「自信を持って安定して運用していく」ために、実環境において実験を行うことでシステムの振る舞いを学び、改善点を見つけたり、理解を深めていくことを目的としています。
詳しくは、下記のリンクをご参照ください。
- カオスエンジニアリングの原則
- 明日から始める!! Chaos Engineering 始め方ガイド (AWS Summit 2021 のセッションの録画)
- カオスエンジニアリングで本当にカオスにならないための進め方をグラレコで解説
AWS Fault Injection Simulator(AWS FIS) とは
AWS FIS はAWS が提供するフルマネージドの障害注入サービスです。AWS の各種サービスと統合されており、agent のインストールなどをせずに実験を開始することが可能です。
詳しくはドキュメントをご覧いただくとともに、基本的な実験の方法のハンズオン記事がこちら にありますので、お試しいただければと思います。
Amazon ECS とAWS FIS の連携について
ここでは、Amazon ECS を利用しているアプリケーションについて、AWS FIS で実施できる実験について説明します。
実験の対象について
カオスエンジニアリングの実験の方法には対象とするレイヤによって大きく2つの方法があります。「インフラレイヤ」と「アプリレイヤ」です。下記の表に特徴と実験の例を記載します
| 対象とするレイヤ | Pros | Cons | 例 |
|---|---|---|---|
| インフラ | 導入しやすい | 影響範囲のコントロールが難しい | EC2 インスタンスの一部を停止する |
| アプリ | 導入コストがかかる(アプリ改修が必要な場合が多い) | 影響範囲を細かく制御できる | 特定のUA からのリクエストのみ一定時間遅延させる |
AWS FIS で現状対応しているのは、基本的には インフラレイヤの実験 です。アプリレイヤでの実験を行いたい場合、別の方法を検討いただく必要があります。
コンテナ実行環境の選択肢
Amazon ECS では現在、起動タイプとして、下記の3つのコンテナ実行環境をサポートしています。
- Fargate 起動タイプ
- EC2 起動タイプ
- 外部起動タイプ (Amazon ECS Anywhere)
本記事では基本的には EC2 起動タイプ で稼働しているアプリケーションを対象とします。後述しますが、AWS FIS がネイティブにサポートしているアクションは、EC2 起動タイプと外部起動タイプを対象としています。また、AWS Systems Manager との連携によって、オートメーション や Run Command によってFargate で起動しているタスクを直接操作したり、外部で稼働しているコンテナ実行環境に障害を注入することも可能ですが、複雑さと実用性の観点から本記事では対象外とさせていただきます。
AWS FIS がサポートする Amazon ECS アクション
AWS FIS では、1つのAmazon ECS アクションをサポートしています。
aws:ecs:drain-container-instances
このアクションでは、AWS FIS がAmazon ECS のUpdateContainerInstancesState を利用してdurationパラメータで指定した期間(もしくは停止条件などにより実験が停止するまで)、ターゲットのAmazon ECS のクラスターのコンテナインスタンスのうち、 drainagePercentage パラメータで指定した割合のインスタンスをDRAININGステータスに変更します。
このアクションを利用することにより、スケールインやコンテナインスタンスの置き換えなどの目的でコンテナインスタンスをDRAININGに設定した際の、タスクの再配置の際に、アプリケーションが期待される振る舞いを取るかを確認することができます。
先述したとおり、この実験はコンテナインスタンスを対象とするため、Fargate 起動タイプで実行されいているアプリケーションに対しては意味がありません。
Amazon ECS のワークロードで利用できる関連するアクション
Amazon EC2 のアクション
EC2 起動タイプのワークロードの場合、コンテナインスタンスに対して、Amazon EC2 アクションを利用することで、インフラレイヤの実験を行うことが可能です。EC2インスタンスの再起動、停止、終了の他に aws:ec2:send-spot-instance-interruptionsを利用することで、スポットインスタンスの中断通知のテストを実施することもできます。(Amazon ECS でスポットインスタンスを使用する場合に自動的にドレインする設定はこちらを参照してください。)
Amazon RDS のアクション
コンテナで動かしているアプリケーションが、RDBMS を使用していることは多いかと思います。RDBMS をAmazon RDSで実行している場合、AWS FIS でDatabase の障害を再現する実験を行うことができます。Amazon RDS アクションを実行することで、Aurora のDBクラスタのフェールオーバーや、RDSのDBインスタンスのリブートの実験を行うことができます。この実験は、コンテナの実行環境に直接作用するものではないため、利用しているコンテナの実行環境に関係なく実施することが可能です。
より複雑な実験を行う
AWS FIS では事前に定義されたアクション以外に、Systems Manager アクションを使うことで事前に用意された、もしくは自分たちで作成したドキュメントを利用して、オートメーションや Run Commandを実行し、より複雑な実験を行うことも可能です。
AWS FISが事前に定義したドキュメントを参照するには、Systems Manager のドキュメントで、「AWSFIS」で検索してみてください。また、「AWSResilienceHub」で検索することで、AWS Resilience Hubがレジリエンステストの推奨で利用する、オートメーションのドキュメントを参照することもできます。
残念ながら現在提供されているドキュメントで、Amazon ECS のタスクやサービスなどのリソースを直接操作するものはないため、タスクやサービスを直接操作する実験を行いたい場合は、ご自身でAutomation タイプのドキュメントを作成いただく必要があります。
"AWSFIS" から始まる、Command タイプのドキュメントは、コンテナインスタンスに、SSM agent がインストールされており、適切なIAM ロールがアタッチされていれば、コンテナインスタンスに対して実行することが可能です。なお、Amazon ECS Optimized Linux 2 AMI にはこのupdate 以降SSM Agent がプリインストールされています。コンテナインスタンスをAWS Systems Manager を利用して管理する方法はこちらをご参照ください。
Fargate 起動タイプの場合、コンテナイメージにSSM Agent をインストールしているか、サイドカーとして、SSM Agent をインストールしたコンテナを実行することで、共有リソース(CPUやメモリ)へ負荷をかける実験を実施することは可能です。Amazon ECS Execがリリースされているため、SSM Agent をコンテナに含める必要性は減っているかと考えますが、Staging 環境での実験で使う場合や、すでにインストールされている場合は選択肢としてお考えください。なお、tcコマンドを使ってネットワークにレイテンシなどを注入するドキュメントはAWS Fargateで実行されているコンテナに許可されているパーミッションでは実行できません。
ここまでのまとめ
AWS FIS を使って、Amazon ECS のワークロードを実験する場合、
- サポートされているアクションを使ったコンテナインスタンスの中断や停止を再現するインフラレベルの実験
- 事前に定義されたCPUやメモリに負荷をかけたり、ネットワークの異常を発生させるCommand ドキュメントを利用した実験をコンテナインスタンスに実施する
の2つから検討いただくとスムーズに実施いただけます。
これらの障害が発生した場合にみなさんのシステムがどのように定常状態(ビジネスの目標を達成するために維持されるべき状態)を維持できるかの仮説をチームやステークホルダと話し合うところから初めて、実際にその仮説通りに動作するかを、AWS FIS を使って実験してみていただけると、システムの振る舞いについて、新たな発見を得たり、安全に運用していける自信を持てるかと思います。
カオスエンジニアリングの取り組みが進み、より複雑な実験を行うにはこちらで紹介したSystems Manager アクションをご検討いただくか、アプリレイヤで障害注入できる別の仕組みも検討いただければと思います。
簡単な実験を行ってみる
ここでは、シンプルなAmazon ECS のアプリケーションをデプロイし、AWS FIS で実際に障害を起こしてみたいと思います。AWS FIS の実験の方法をご紹介するのが目的ですので、実際のワークロードでの実験の際は影響範囲の考慮やアプリケーションのモニタリング、オブザーバビリティの確保などを考慮した上で実施してください。
事前準備
実験対象のアプリケーションをAmazon ECSでデプロイする
ここでは、AWS のドキュメントに記載されているチュートリアルのアプリケーションを対象に実験をしてみます。
下記の手順に従って、サンプルのアプリケーションを実行してみてください。
AWS FIS が利用するIAM ロールを作成する
下記の手順に従って、AWS FIS が利用するIAM ロールを作成します。(上記で紹介したワークショップを事前に実施した場合、この手順は不要です)
実験の内容
今回、事前準備でデプロイしたアプリケーションは1つのコンテナインスタンス上で1つのタスクを実行しているシンプルなアプリケーションです。このコンテナインスタンスは、Auto Scaling グループに所属しており、希望する容量は1に設定されています。
万が一、このコンテナインスタンスが何らかの理由で停止された場合、期待する挙動を考えてみます。
- コンテナインスタンスはAuto Scaling グループにより自動的に新しいインスタンスが立ち上がる
- ECSのタスクは一時的に中断されるが、コンテナインスタンスが復旧するとサービスにより再配置される
上記より、コンテナインスタンスを停止した場合でも、アプリケーションは自動的に復旧してくることが期待されます。
今回は簡単のため、ELB を利用しておりませんので、アプリケーションのPublic IP アドレスは変更されます。実際の環境では、コンテナインスタンスやタスクをAZを跨いで冗長化し、ELBによってロードバランシングをすることによって、一部のインスタンスが停止してもサービスを継続できる構成をお勧めします。
実験の手順
1. 実験テンプレートを作成する
AWS FIS のコンソールにアクセスします。「実験テンプレートを作成」ボタンをクリックします。
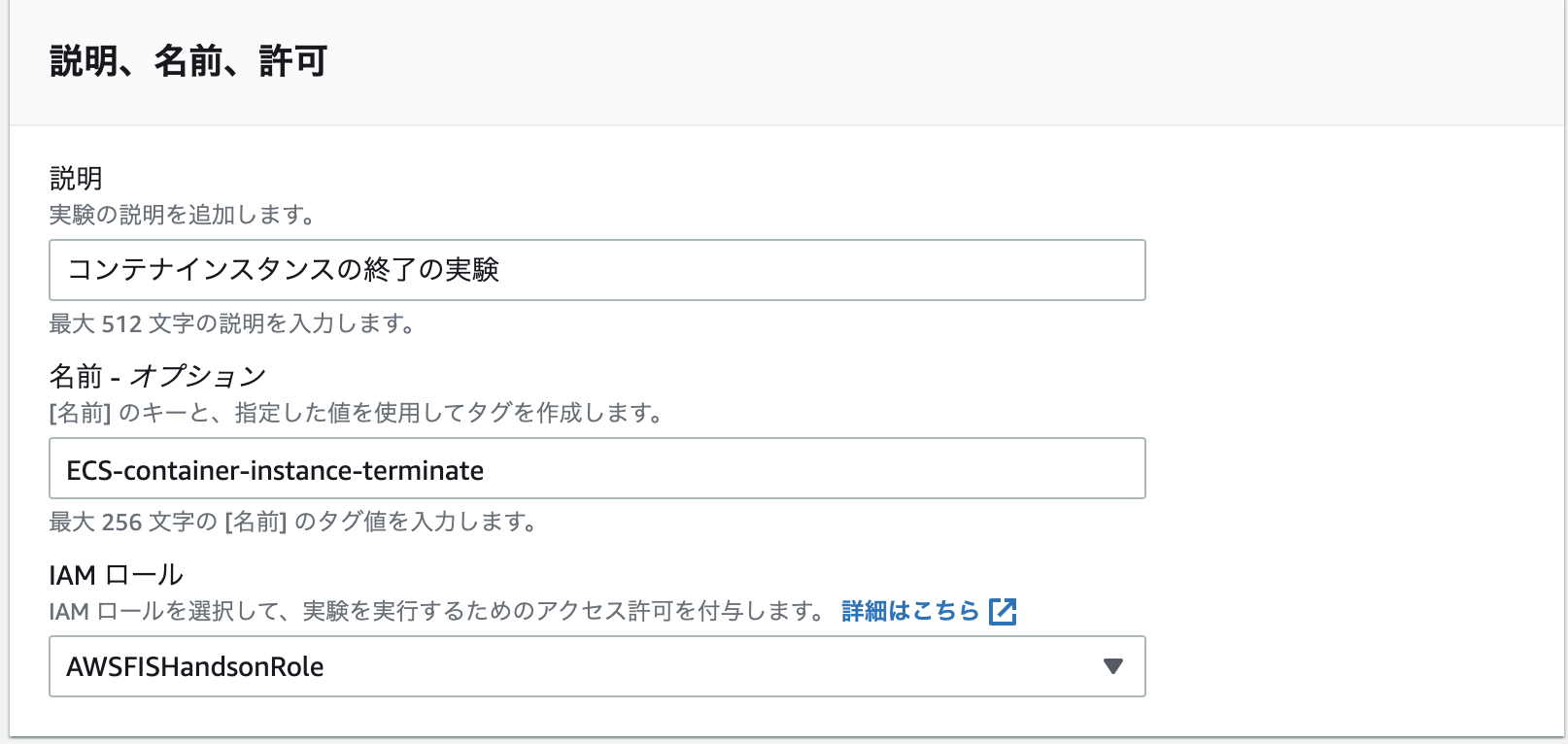
「実験テンプレートを作成」画面で下記を設定します。
- 説明 - この実験の説明を記載します。必須項目です。
- 名前 - Name タグに設定する名前を指定します。オプションですが、実験テンプレートの一覧画面での視認性を確保するため、設定することをお勧めします。
- IAM ロール - [上記](#AWS FIS が利用するIAM ロールを作成する)で作成したIAM ロールを選択します。
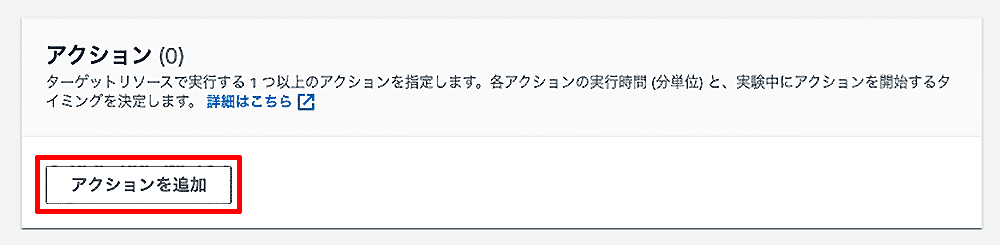
「アクション」カードの「アクションを追加」ボタンをクリックし、アクションを追加します。
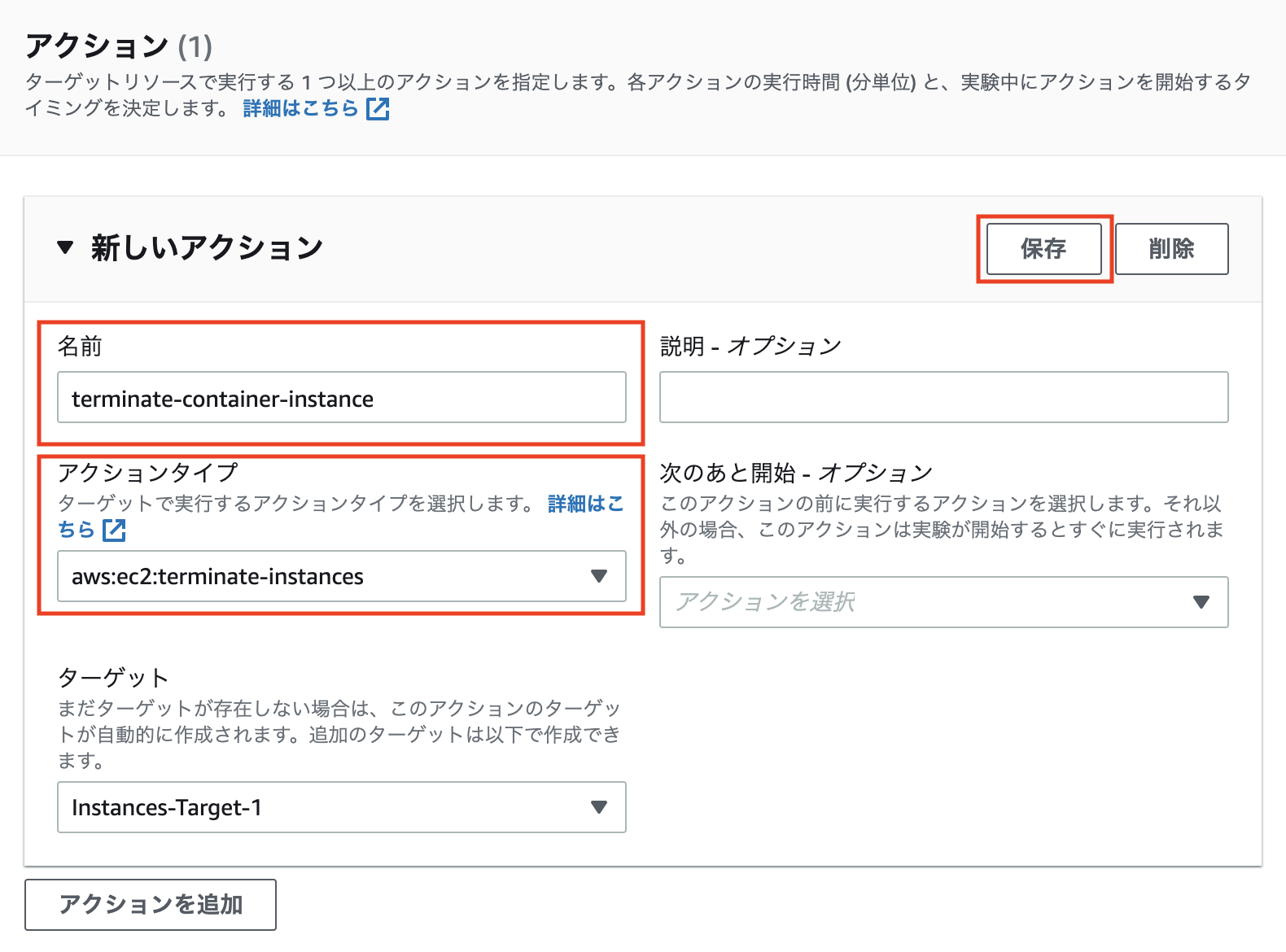
下記を設定します。
- 名前 - アクションを識別する任意の名前を設定します。
- アクションタイプ -
aws:ec2:terminate-instancesを選択します。
他の設定はデフォルトのまま、「保存」をクリックします。
「ターゲット」カードにInstances-Target-1(aws:ec2:insance) が追加されているはずです。「編集」ボタンを押します。
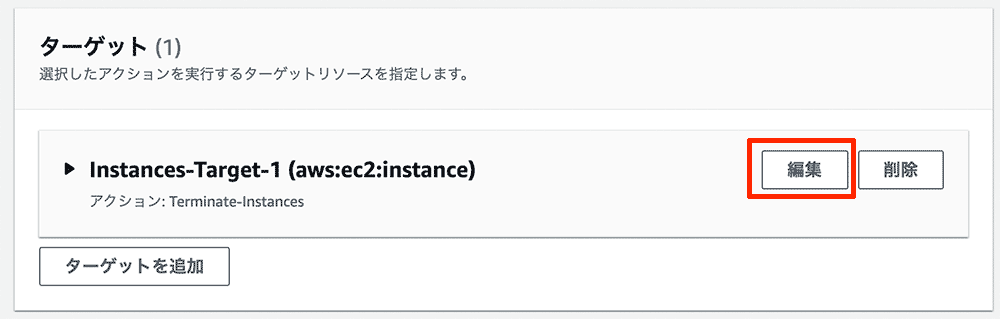
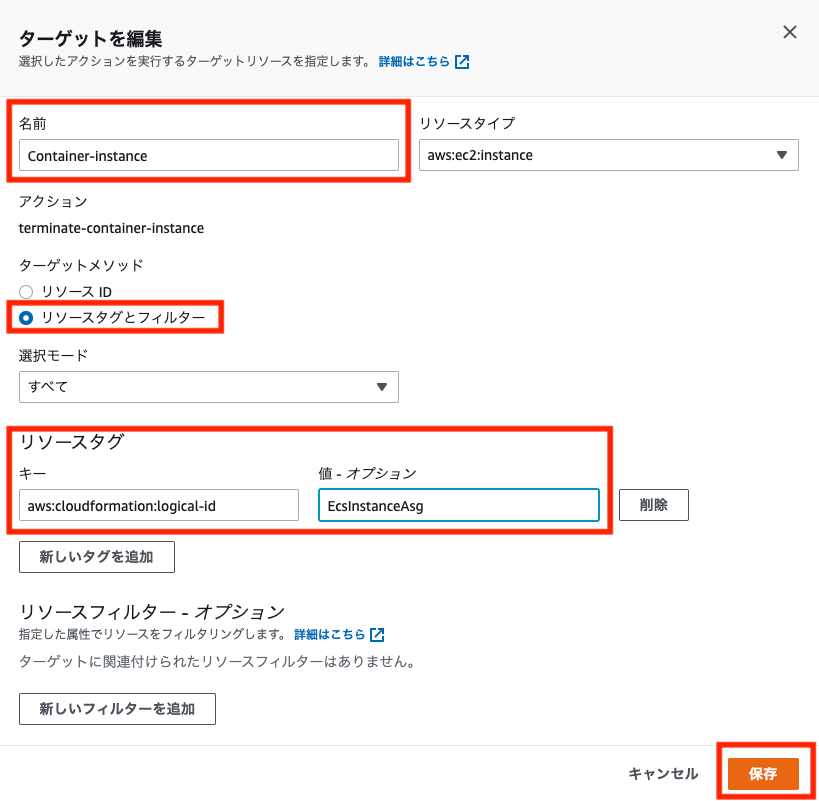
表示されたダイアログで下記を設定します
- 名前 - ターゲットを識別する任意の名前を設定します。
- ターゲットメソッド -
リソースタグとフィルターを選択します。 - リソースタグ - 「新しいタグを追加」ボタンをクリックし、キーに
aws:cloudformation:logical-id、値にEcsInstanceAsgを設定します
他の設定はデフォルトのまま、「保存」ボタンをクリックします。
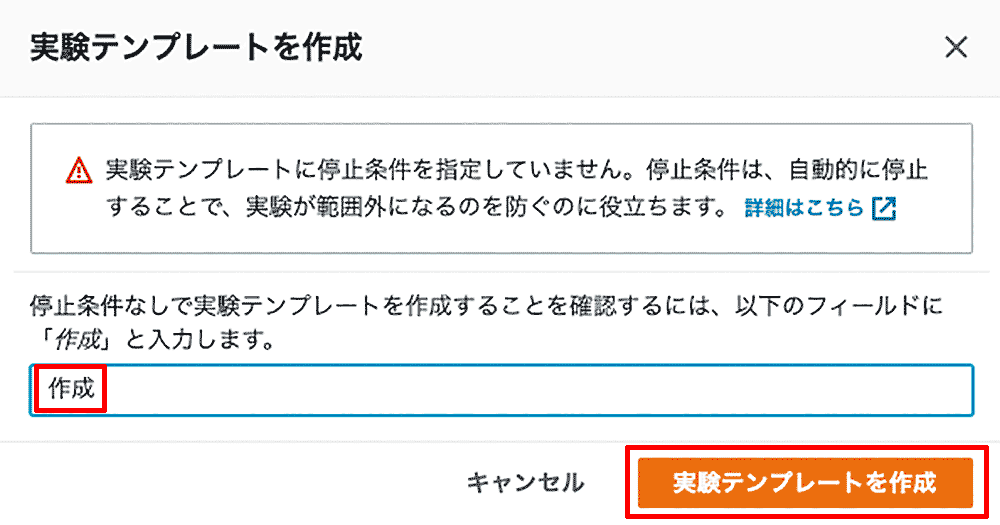
「実験テンプレートを作成」ボタンをクリックします。今回、停止条件なしで実験テンプレートを作成しているため確認のダイアログが表示されるので、作成と入力して、「実験テンプレートを作成」ボタンをクリックします。今回は簡単のために割愛しますが、実際のワークロードでの実験、特に本番環境での実験の際は、安全のため、停止条件を設定することを強くお勧めします。
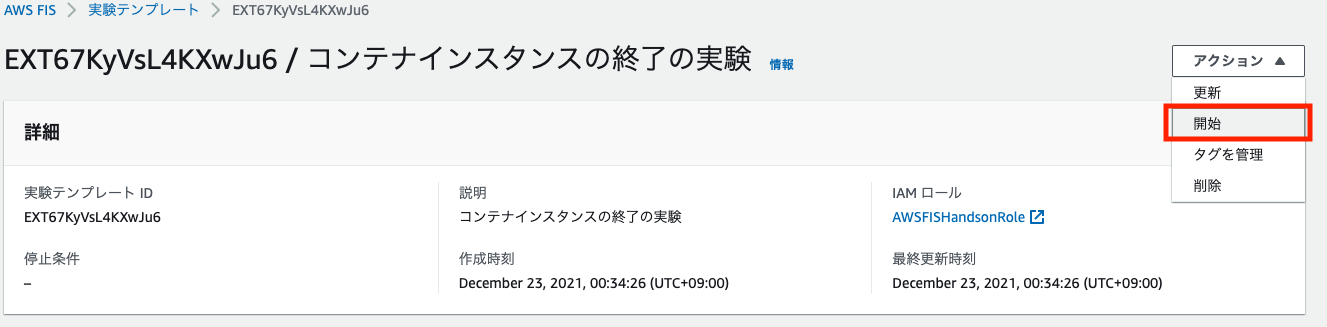
2. 実験を行う
実験テンプレートの画面右上の「アクション」ドロップダウンから、「開始」を選択します。
必要に応じてタグを設定して、「実験を開始」ボタンをクリックします。(実験を識別しやすくするためにName タグの設定をお勧めします)
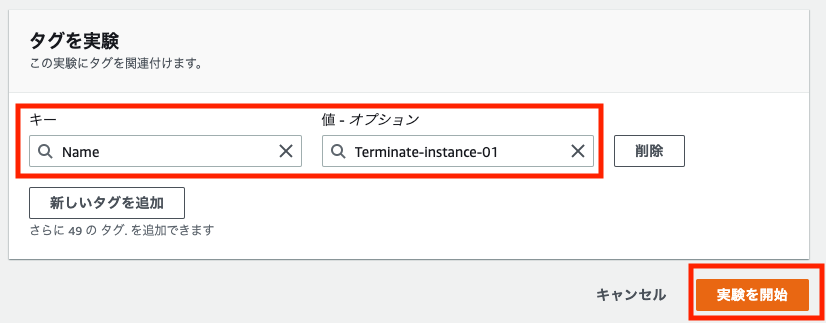
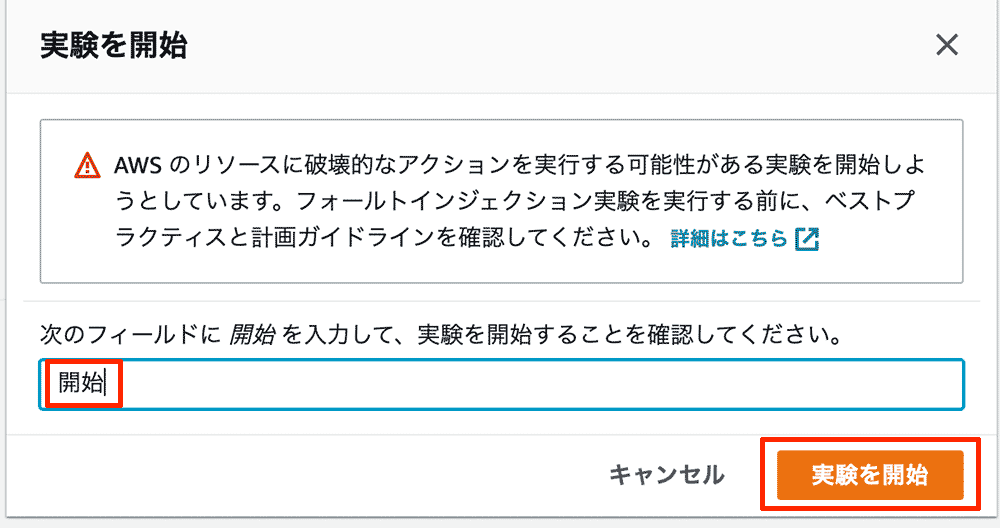
確認のためのダイアログが表示されるので、「開始」と入力して実験を開始します。
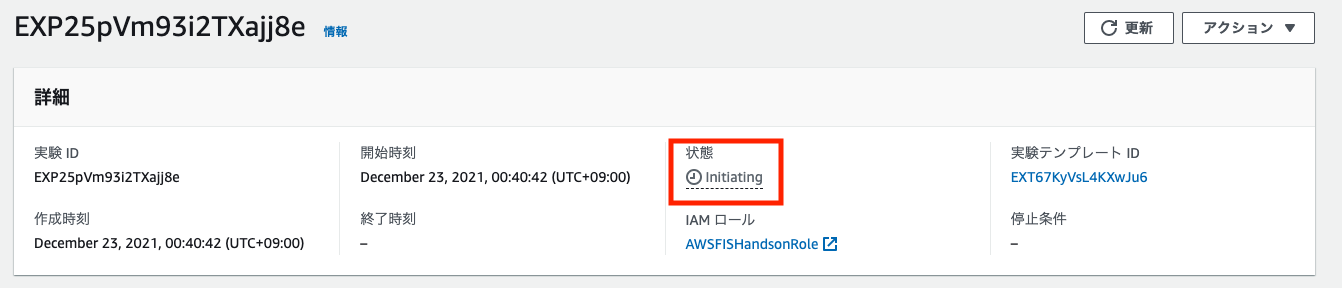
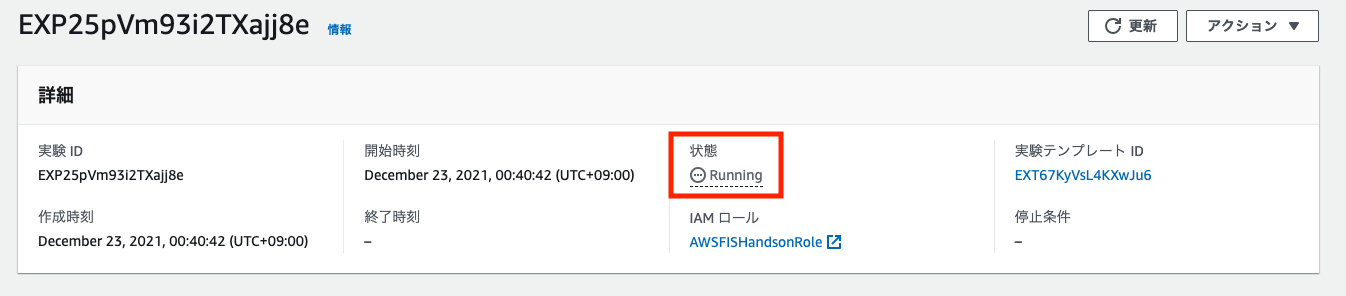
実験の状態が、initiating -> Running -> Completed と変化することを確認します。
3. 実験の結果を確認する
実験が無事成功すると、コンテナインスタンスが終了され、最初に起動したサンプルアプリケーションが停止しているはずです。下記を確認してみてください。
- サンプルアプリケーションのURLにアクセスし、アプリケーションが停止していることを確認する
- ECS のクラスターからサービスを確認し、タスクが起動していないことを確認する
- EC2 のコンソールから、コンテナインスタンスが終了されたことを確認する
しばらくすると、Auto Scaling グループによって、新しいコンテナインスタンスが立ち上がり、そのコンテナインスタンス上にサービスがタスクを配置して、アプリケーションが復旧することも確認できるはずです。もし、何らかの理由で復旧してこない場合、設定に何らかの不備があることが考えられるので、デプロイした際の手順や設定を見直してみてください。
4. 後片付け
余計な課金がかかることを抑えるため、動作確認が終わったらこの環境を削除しておきましょう。
- CloudFormation のコンソールに移動し、
EC2ContainerService-{クラスタ名}のスタックを削除します。 - AWS FIS のコンソールに移動し、実験テンプレートの一覧から今回作成したテンプレートを選択して、右上のアクションメニューから「実験テンプレートを削除」を選択し、画面の指示に従って、実験テンプレートを削除します。
AWS FIS はアクションの実行時間に対して課金されるため、実験テンプレートを削除しなくても実際に実験を行わなければ課金は発生しません。詳しくは https://aws.amazon.com/jp/fis/pricing/ をご覧ください
まとめ
AWS FIS を使って、Amazon ECS で稼働しているアプリケーションやシステムに障害を注入する方法について、基本的な解説と簡単な実験の手順を書いてみました。実際のアプリケーションでは、もっと複雑な構成やシナリオを想定する必要がありますが、AWS FIS の基本的な操作方法とAmazon ECSのワークロードへの適用方法の参考になれば幸いです。
実際のコンテナアプリケーションのワークロードでは、インフラレイヤだけではなく、アプリレイヤでの実験まで実施したい場合が多いかと思います。現状、AWS FIS だけでアプリレイヤの実験を行うことは難しいですが、AWS FIS の場合、基本的なインフラレイヤの実験はagent のインストールなどをしないで簡単に始めることが可能です。インフラレイヤの比較的実施しやすい実験からカオスエンジニアリングのプロセスを試行し、成功したり価値を見出した際にはアプリレイヤまで含めた実験を行う方法を模索していっていただければと思います。
カオスエンジニアリングにトライしてみて、自信を持ってシステムを運用していける自信を構築していきましょう!