What
これは機械学習の初歩的なモデルであるパーセプトロンモデルを実装するためのデータセットを可視化する記事です
Content
データセットの可視化 with Numpy Pandas Matplot
パーセプトロンモデルとは何か?についてはここでは述べません。有名なモデルですので調べればいろいろ出てきます。
機械学習を勉強し始めて初めてコーディングしたモデルなのでまとめます。
今回使用するデータセットは、UCI Machine Learning Repositoryという機関?orもしくは一種オープンソースから花に関するデータセットIrisを例題に使います。
まずは、データセットの確認をします。osモジュールとpandasライブラリを使ってオンラインからデータセットを取得し中身を表示します。
import os
import pandas as pd
s = os.path.join('https://archive.ics.uci.edu', 'ml', 'machine-learning-databases', 'iris', 'iris.data')
df = pd.read_csv(s, header=None, encoding='utf-8')
print(df)
上記のコードの実行結果は、
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
[150 rows x 5 columns]
とこんな感じで、列は以下の情報が格納されています。150個の花のデータセットとなっています。
ちなみにこのデータセットでは花の種類はIris-setonaとIris-virginicaの2種類となっています。
0列: Sepal length, #がくの長さ
1列: Separl width, #がくの幅
2列: Petak length, #花弁の長さ
3列: Petal width, #花弁の幅
4列: Class laber #花の名称
続いて、がくの長さとはなびらの長さを軸に取り2次元のグラフで中身をみてみます。ついでに、花の種類毎にプロットを分けます。
Matplotライブラリを使用してグラフを描画します。はじめにライブラリをインポートします。データ操作にはNumpyを使います
import matplotlib.pyplot as plt
import Numpy as np
続いて、0列:がくの長さ、と2列:花弁の長さを取得します。ilocを使い0〜100行目の0列目と2列目をそれぞれの値を取得します。[0列の値,2列の値]の2要素の1次元リストが返されます。気になる方はprint(X)推薦です。
X = df.iloc[0:100, [0, 2]].values #右側は1, 3列目のみ取り出している
今回は、予めデータセットの中身をみており、先頭50個がIris-setonaのデータとなっています。setosaのデータを赤丸、versicolorを青×でプロットします。2要素の右側の値をx軸に、左側の値をy軸にとるため、下記のように記述します。
# setosaの散布図プロット 赤丸表示
plt.scatter(X[:50,0], X[:50, 1], color='red', marker='o', label='setosa')
# versicolorのプロット 青×表示
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
# 軸ラベルの設定
plt.xlabel('sepal length [cm]') # がくの長さ
plt.ylabel('petal length [cm]') # はなびらの長さ
# 凡例の設定(左上に配置)
plt.legend(loc='upper left')
plt.show()
実行結果は下記、
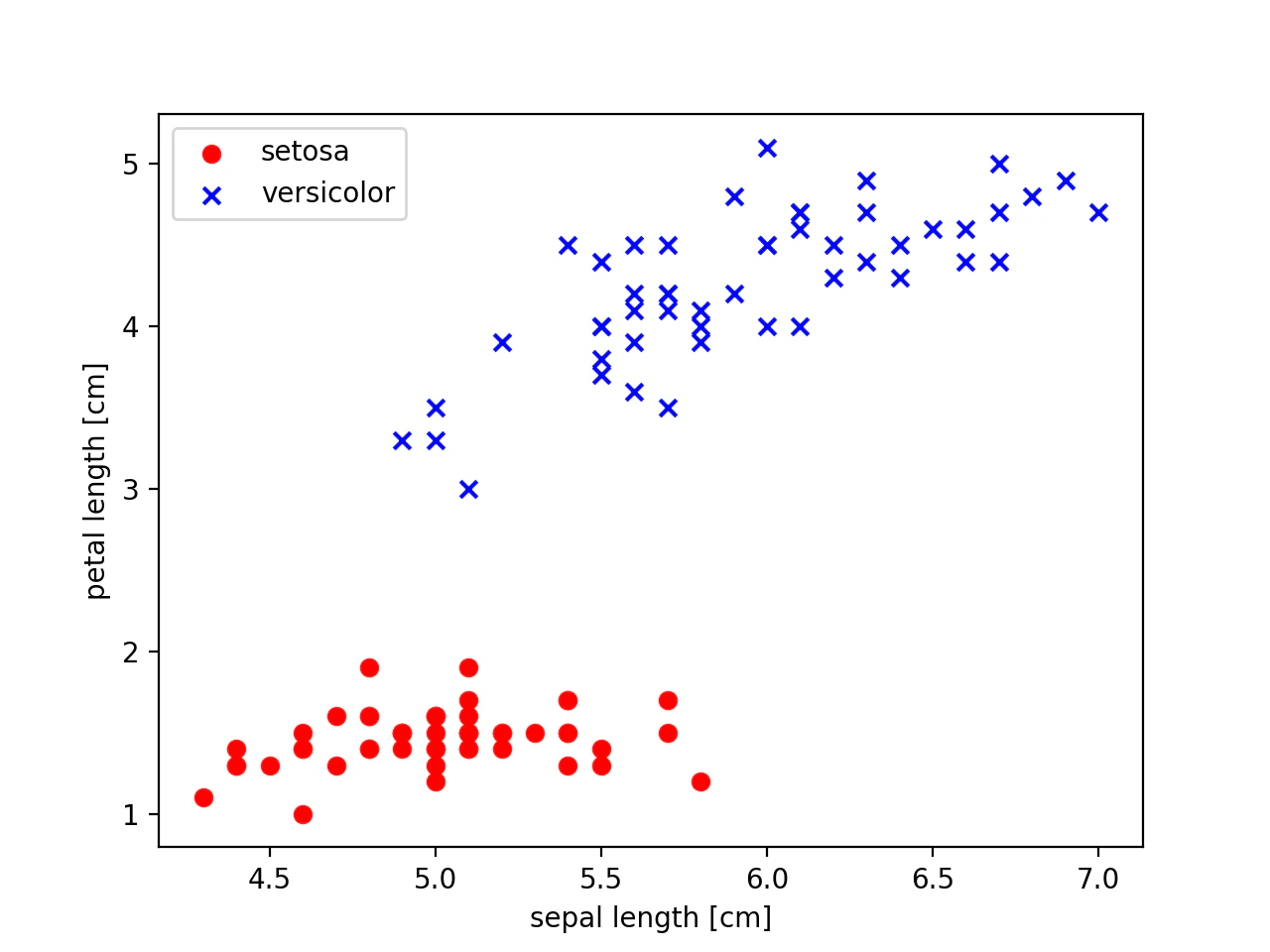
結果をみるとなんか法則がありそうです。。。
これを使って機械学習アルゴリズムを組みますが、流れはおおよそ以下の通り、(参考図書丸々写すわけにはいかないので・・・)
Step .1 がくの長さに対する学習率w_1, はなびらの長さに対する学習率w_2を適当に定義(乱数を使います)
Step .2 データセットと内積をとり、それぞれの内積計算結果を配列か何かで格納します
Step .3 内積計算結果がある値(例えば0)を境にsetosaかversicolorに分類する。
Step .4 実際のデータと分類結果が合っているかチェックしミスってたら学習率分だけパラメータを適宜更新(forループなどで全データセットについて実施)
Step .5 分類を間違っていた場合をフラグで管理する
Step .6 誤分類が0個になるまでひたすら実施
以上の過程を踏めば無事機械学習が完了します。
実装はここでは載せません、(参考図書の著作権に引っかかりそうなので)
Comment
これ実は、学習1サイクル毎に誤分類の数をカウントすると、単調に減少せず増加している場面があります。ちゃんと良い方向に学習できているか監視するのも大事ですね・・・