0. はじめに
0.1 この記事を書くきっかけ
みずほ銀行のトラブルですが、終息したのでしょうか。この件に関して、新聞、雑誌、ネットなどで多くの記事が書かれています。そんな中で、日経BP社から「ポストモーテム みずほ銀行システム障害事後検証報告」(以下 ポストモーテムの本)という書籍が出版されました。この本は、障害とその原因について大変詳しく記載されています。本記事でも随分参考にさせていただきました。しかし、この本に書かれている事に、どうも腑に落ちない部分があるので僭越ながらこの記事を書いてみました。
日本のITを提供する業界(ベンダー)、ITを利用する企業(ユーザー)そしてITマスコミ、これを一まとめにしてITムラと呼ぶことにします。筆者の考えでは、このITムラの闇こそ、みずほ銀行のトラブルの根源ではないかとの思いです。因みに筆者はみずほに銀行口座は持っていますが、みずほ銀行とは何の関係もありません。また銀行システムに関しても、大昔、銀行システムの端で仕事をした経験がある程度です。
0.2 サマリー
長文になるので以下概要を記します。
<教訓1>運用へのリスペクト
ITILやSREも大事だが、本当に大事なのは運用へのリスペクト
<教訓2>障害対応は一筋縄では行かない
障害検知や障害時のオペレーションは難しい
<教訓3>お金は大切に使う
開発や運用に適切にお金を使う、無駄な開発をしない
<教訓4>テクノロジーを過信するな
疎結合分散システムやテストを過信してはいけない
<教訓5>日本の常識、世界の非常識
日本のITの問題点
1. <教訓1>運用へのリスペクト
1.1 運用軽視は、みずほ銀行だけではない
「運用へのリスペクト」この教訓を書くにあたって、次のようないくつかの候補がありました。
・システムは運用が大切
・システムは運用ファーストで作る
・システム運用を軽視すると、会長、社長、頭取の首が跳ぶ
実際、頭では運用が大事と思っても、あるいは口では運用が大切と言っても、その実、システム運用を軽視しているというのが今の日本のITの状況です。
ITムラでは、以前より開発重視、運用軽視の因習があります。いまだに、運用なんて毎日同じことをやっているのでは、という誤解さえあります。中には、開発の尻拭いで、「後は運用でカバーして」などという暴論を吐く者もいます。実は、ピカピカのシステムでも運用が悪ければ、エンドユーザーからボロクソに叩かれるし、逆にポンコツのシステムでも運用が良ければ、お客様の賞賛を得る、あるいは賞賛を得ないまでも、クレームなしで使ってもらえる。このように運用がとても大事な要素であり、運用者の視点、発言力の強化がなされないとなかなかシステムの安定稼働には結びつきません。また、運用自体はとても地味な世界で、うまく動いて当たり前、障害が出ると非難されるという損な役回りであります。
運用は時として開発より難しいこともあります。開発でもトラブルで、にっちも、さっちも行かないことがあります。しかし、いざとなれば、リリースを延期したり、リリースを止めたりすることもできます。もちろん、これはこれで大変なことではありますが。しかし、運用の場合どうでしょう。明日から運用を止めますというのは、今どき事業を畳みますに等しいです。つまりトラブルが出ても継続しなければいけない。また、開発の場合、ある程度計画的に要員を揃えられますが、運用の場合、いつ起こるかわからない障害のために要員を確保しておくことは普通しません。ちょうど、100年に一度の感染症のために、感染症病院や感染症医師を大量に用意しないのと似ています。
みずほの件で言うと、いくら会長や社長やCIOの給料を下げても、障害が減ることはありません。運用担当者を罵倒しても同じです。またシステムが極めて稚拙に作られていたかというと、それも考えにくい。なにしろ日本を代表するSI企業(IBM、富士通、日立、NTTデータ)が総力を挙げて作っているのです。本質的には、運用を軽視していたことが、一連のトラブルの要因でしょう。しかし、それはみずほ銀行だけではありません。
1.2 運用のモチベーション
コンピュータシステムの障害原因について、大きく分けると以下の4つに分類されます。
・ハードウェア障害
・ソフトウェア障害
・構築担当者又は運用担当者の設定ミス
・運用担当者又はエンドユーザーの操作ミス
一連のみずほ銀行のトラブル11件(2021年2月28日〜2022年2月11日)を見てみると、以下の通りになります。これはポストモーテムの本から抜粋したものです。
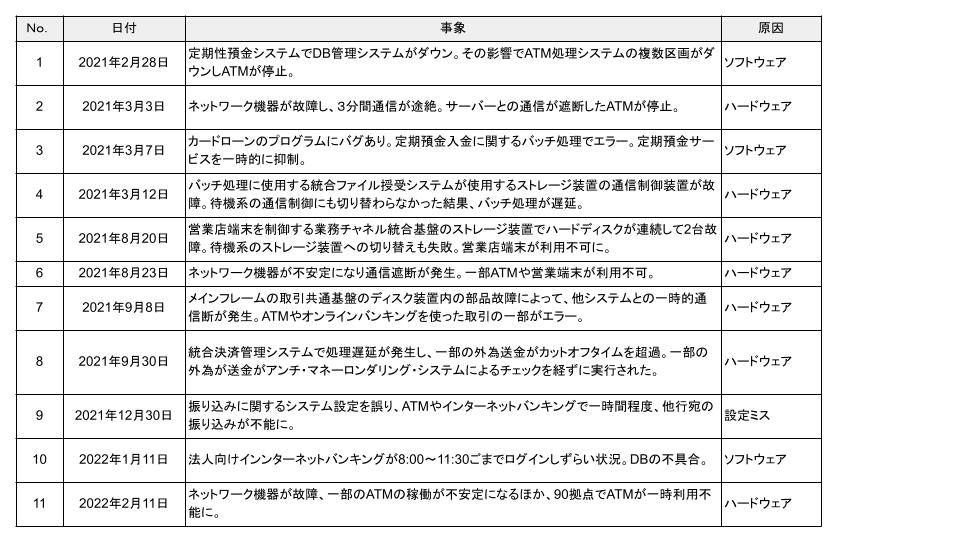
またみずほ銀行の障害と先ほどの障害原因と件数を突き合わせてみると、以下のとおりになります。
| 項目 | 件数 |
|---|---|
| ハードウェア障害 | 7 |
| ソフトウェア障害 | 3 |
| 運用担当又は構築担当の設定ミス | 1 |
| 運用担当又はエンドユーザーの操作ミス | 0 |
予想通り、ハードウェア障害が一番多いです。ある程度リリースから時間を経たシステムでは、ハードウェアの障害に起因するトラブルが一番多くなります。操作ミスが0件ですが、これは障害対応中の操作は含んでいません。あくまでも障害の原因となった一次トラブルです。
よく運用担当者のモチベーションを上げるため、何日間、無事故であれば表彰するとか、ボーナスを上げるとか行なわれますが、あれはあまり効果がありません。何故かというと、ハードウェア障害とかソフトウェア障害が、運用担当者のコントロールが効かない事に由来してるからです。要するに運用担当者からみると、自分たちの責任範囲以外で起きることで責められても納得感がないのです。いやハードウェアの障害に対応できるよう、きちんと運用設計しておけと言う声がきこえそうですが、これはなかなか難しい。ありとあらゆる障害を想定しておくことは困難です。
1.3 DevOps
最近(と言っても結構前ですが)DevOpsという言葉が出てきて、ようやく開発と運用を対等に見ようという動きが出てきました。このDevOpsを最初に提起したFlickr社のプレゼンに以下のような文章があります。
運用部門のミッションは安定稼働でも最適化でもない
運用部門のミッションはビジネスを有効にする事である。(開発部門も同じである)
上の文書に続いてFlickr社は1日10回のデプロイをするため、変化のリスクをツールと文化によって低減すると言ってます。とりあえずツール部分は省いて、文化の面を抽出すると以下のようになります。開発と運用それぞれが
・相手を尊重する(Respect)
・相手を信頼する(Trust)
・失敗に対する前向きな姿勢
・非難をしないこと
今回の教訓はここから借用しました。しかし 筆者はこれを読んだ時、とてもアメリカ的だなという印象がありました。失敗やミスをおおらかに受け入れるアメリカの楽観主義文化に対して、失敗やミスを認めない日本の悲観主義文化で果たして受け入れられるのだろうか。これについては、また後で述べます。いずれにしろ開発と運用という立ち位置で参考になる話だと思います。ITILやSREも大事ですが、運用をリスペクトする文化も無視できないものがあります。そしてこの文化を広めなかったITムラにも大きな責任があります。そもそも、運用者に対するリスペクトを欠いたというのは、どのような状態でしょうか。例を挙げてみます。これはあくまでも架空の会社の架空の事例です。
企画担当:例の通帳の電子化のバッチジョブまた流してもらえないかな。
運用担当:わかりました。何件くらいですか。
企画担当:270万件ぐらい。
運用担当:それでは、1日45万件実施すれば6日で終了するので、繁忙期を避けて3月6日(土)から土日を使えば21日で終わりますね。
企画担当:それが3月15日までに何とか終わらして欲しいのよ。
運用担当:そうすると2月27日から始めないと、うーむ月末処理とぶつかりますね。ちょっとヤバイです。
企画担当:別に土日なら支店も閉まってるし、月末でも大丈夫だろ。
運用担当:いや月末は避けた方が。。。
企画担当:障害が起きるエビデンスはないんだろう。これ3月15日まで終わらないと16億円の印紙代がかかる。
運用担当:しかし。。。
企画担当:とりあえず、今度の土曜日45万件流して、うまくいったら継続して。開発の連中も待機させておくから。
運用担当:やはり月末は何が起こるかわからないですから。
企画担当:これからは、うちの会社もジョブ型の仕事の進め方をする。ジョブ型は決められたことを確実にやるのだ。君たちも言われたことだけやればいいのだ。
運用担当:。。。。。。
結局
土曜日はうまく行ったものの、日曜日にコケた。これは他のJOBのメモリー専有率が高まり、当該JOBを圧迫したため。
運用者の言うことを無視すると悲惨な結果になるということです。
みずほのトラブルに戻ると、あちらのソフトウェアを改定しろ、こちらのハードウェアを取り替えろとか、確かに大事な事ではありますが、運用をリスペクトする文化がないと、なかなかスムーズにいかないでしょう。因みにAWSなどは、開発と運用の境目なしに開発者が積極的に運用に関わるべきと謳っています。「you build it,you run it」あなたがそれを開発したなら、あなたが運用すべきである。多くの現場では、現実的ではないかもしれませんが、深く傾聴すべき格言です。
2.<教訓2>障害対応は一筋縄でいかない
2.1 障害検知は難しい
「障害なんか出たら、切り替えればいいんだろう」運用を理解しない人間からはこんな言葉が聞こえることがあります。そもそも障害を検知しないこともある。よくあるのは動いているのか、動いていないのか分からない状態。動いているのだけど、もの凄く動きが遅いケース。こういう場合の判断はとても難しいです。思い切って該当のハードウェアなりソフトウェアを落とすこともありますが、うまくいかないケースもあります。
また一つのエラーから多数のエラーメッセージが上がりパニックになることがあります。例えばネットワーク機器が故障してバックアップがされないケースでは、そのネットワーク機器にぶら下がっている各種機器から一斉にエラーメッセージが上がって何が何んだかわからなくなってしまいます。エラーメッセージが大量に上がって、どのエラーが起点になっているか分からなくなってしまいます。監視プログラムが自動で監視しているから楽ちんと言う世界では無いと思います。
最近のハードウェアはとても性能が良く滅多に故障しません。これは大変良いことなのですが、若い運用担当者から見ると滅多に起こらないことが起きてしまうと、パニックになって正常な判断を下せないことがあります。この辺の訓練は必要かもしれません。「マニュアルに書いてあるだろ」では通用しません。
2.2 障害時のオペレーションは博打である
システムの世界では、コーディングして、単体テスト、結合テスト、システムテストを実施し、本番にリリースされても一度も動かないプログラムがあります。どういうプログラムかと言うと、リカバリー処理やエラー対応のプログラムです。この手のプログラムは、稼働が少なければ少ないほどシステムにとって都合のよいものになります。一方プログラムの世界では稼働すればするほど、バグが取れて完成度、安全度が高まります。業務だと、日次処理より月次処理、月次処理より期末処理、期末処理より年末処理と使用頻度が少ないほうが不安定です。より多く使うことによりこなれててきます。反対に障害対応など使用頻度の少ないものは安定していません。障害が起きると、エラー処理でまたエラーが出たり、2次3次とエラーが連鎖することが多いのもエラー処理の実施回数が少ないからでしょう。
さて2021年8月20日のみずほ銀行のトラブルでは、データベースの不具合が発生、システム全体のバックアップは想定していたものの、部分的バックアップは想定していませんでした。このため手動によるバックアップを模索しましたが、なかなか決断できず最終的にバックアップオペレーションを実施したものの、営業開始時間に間に合わせることができませんでした。後から考えればもっと早くバックアップオペレーションンを実施しておけばと言うことになるのですが、これを責めることはできません。何故ならバックアップを実施した後に新たなトラブルが出る可能性が高く、しかもその時のリカバリ処理がより複雑になると担当者が思ったのでしょう。できるだけ、今の環境で復旧させたいと願ったのが、結果的にはバックアップの手続きの遅れにつながった訳です。
別な例として、現在の障害が過去に起きた事例とよく似ているケースです。その時行った操作でうまくいった。そこで現在のトラブルを解決するために同じ操作を実施してみる。これもよく行われる事ですが、神様はそんなに優しくありません。もちろん、これでうまく行く時もありますが、何も変わらない、ひどい時には事態をますます悪化させてしまいます。しかし、この操作者を誰も責めることはできません。障害時のオペレーションは、じっくり考えて実施する余裕はありません。非常にタイトな時間の中で決断しなければなりません。
以下余談ですが、筆者が以前大型コンピュータのプログラムを作成していた頃言われたこととして、究極のユーザーインターフェースは何かということでした。それはユーザーに何も入力させないことである。まるで中島敦の「名人伝」みたいな話ですが、人間は常にミスする。ミスしないためには入力しないで済むものは、自動でトコトンやれということです。しかしこの全自動、障害には強くない。障害が起きた時に初めからやり直しでは芸がない。やはり手動に切り替えて途中から再開とかいろんな設定を変えるものが欲しい。GUI(グラフィカル・ユーザー・インターフェース)全盛の今でも、CLIとかpromptが残るのは結局この自動化と自動化のリカバリの側面が大きいと思います。
2.3 障害後の処理
障害が起きたらどうするか、教科書的に言うとまず目の前の障害を一時的にでも取り除いて、速やかに定常処理に戻す。その後障害の原因を調査して、抜本的対策をとる。間違ってもシステムを止めたまま長々と原因の調査などを行うことはありません。とにかく定常状態に戻すことが最優先されます。前世紀の話で恐縮ですが、当時センターにあるメインフレームコンピュータはホストと呼ばれていました。昔はハードウェアの障害はとても多かった。メモリー、ディスク、周辺装置、ありとあらゆるモノが壊れたのです。もちろんシステムもいろんなモノが壊れると言う前提で作られていました。そんな中でホストのリカバリーには異常な執念を見せていました。ホストの再立ち上げは1分以内とか言われて、ATMとか窓口の端末とかでホストがダウンしたことを感じさせないようにしたものです。
先日、KDDIの回線で障害が発生し、リカバリの段階で「輻輳(ふくそう)」という言葉が出てきました。これは銀行システムでも似たようなことが発生します。長時間止めてしまうとトランザクションが滞留して、それを一度にもとに流すとまたダウンしてしまう。少しずつ小分けにして(例えばいくつかの支店群)復旧させるなどの処理が必要になります。
最終的にエラーの原因がハードウェアなら、ハードウェアを取り替える。ソフトウェアならエラーの修正を行うわけですが、これが他に影響がないかなどの検証を行うため大変時間がかかります。プログラム一行直すのに2ヶ月かかるというのも、あながちウソではありません。このように巨大システムのプログラム修正は簡単には行えません。
3. <教訓3>お金は大切に使う
3.1 そもそもIT投資が少ない
今から4年前に経済産業省から「2025年の崖」というレポートが出ました。筆者は、この内容についてどうも納得できずにいました。その理由は次の2つの事象をごっちゃにしてる感があるからです。
・レガシーシステムのモダナイゼーション(近代化)
・デジタルトランスフォーメーション(DX)
また、このレポートで記載されているように2025年に12兆円の損失は、ベンダーもユーザーも居眠りして何もしない限り、絶対に起こらないと思うからです。
もう一度言うと、レガシーシステムのモダナイゼーションとDXは別の概念です。レガシーシステムの改善に無理やりDXを当てはめてはいけません。こう書くと、DX反対派のように思われますが、DXは推進すべきだが、レガシーシステムのモダナイゼーションに適用するのは最小限ににすべきです。筆者の考えでは、レガシーシステムのモダナイゼーションには、あまり金をかけず、どうしても必要な分にだけ出費します。逆にDXは、既存のビジネス及びシステム環境とは切り離して、ビジネスの変革と合わせて資金を投入します。
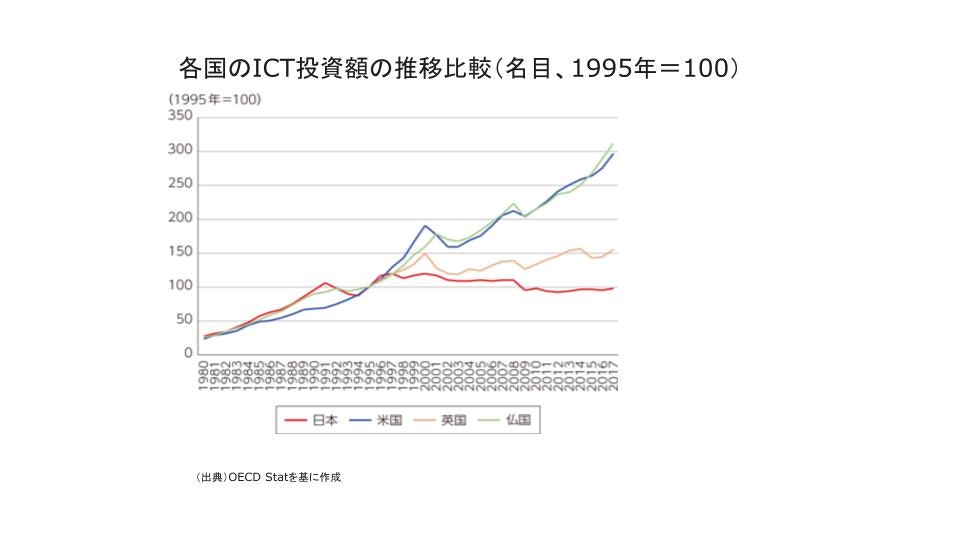
そもそも経済産業省が2025年に大変な事が起こると、エンドユーザーを脅かすような文章を書いているのは何故だろうか、ずうと考えていました。そして、ようやくわかったのは、これは経済産業省がエンドユーザーにIT投資を促すための文章ではないか。何故IT投資を促すか、下の図をみて貰えば、一目瞭然ですが、1995年を100とすると、アメリカ、フランスは2017年で、300近く、投資の少ないイギリスでも150くらい、日本は100前後と惨憺たるものです。実際、この文章が出てから、ITムラは散々、DX、DXと煽った結果ウハウハ儲かったようで、ご同慶の至りです。この文章の効果はてきめんでした。尤も日本で不足しているのは、IT投資だけではなく、あらゆる国内投資が不足して、大いなる停滞を招き、賃金が延びず、失われた30年だか40年という結果になりました。
3.2 みずほ銀行のIT投資は適正か
さてみずほ銀行ですが、筆者は2,3,4と覚えています。3行統合されてから、統合システム(MINORI)を作るにあたり、20年の歳月、35万人月、4500億円の費用がかかったそうです。やれ、現代のサグラダファミリアだ、スカイツリーが7本建つ等、さんざん揶揄されていますが、実際はどうでしょうか。米国のJPモルガン・チェース銀行は、年間1兆円を超えるIT投資を行うそうです(日本経済新聞2021年12月1日朝刊)。それに比べれば随分かわいいものです。確かに日本の他の会社のIT部門から見れば突出しているように見えますが、現代の金融機関はもはやIT産業と言っても良いくらいのものですから、当然でしょう。
問題は先の日経新聞の記事にもある通り、この3年間で人員を6割削減するなど、運用・保守費用を大幅にカットしたことです。要するに開発費にお金をかけ過ぎたと判断して、それが原因かどうかわかりませんが、運用・保守費用を大幅に削ったというのが真相のようです。運用・保守費用を削って、開発に回す。一見正しいように見えますが、みずほの事例で分かるように一番賢くないやり方と言いたいですね。何故、開発費が大幅にかかったのか、何故開発が長期にわたってしまったのか、次に述べたいと思います。
3.3 なぜ開発費用が大幅に膨らんでしまったか
あれはいつ頃だったろうか。日本にいるJavaプログラマーの半数が、みずほ銀行のプロジェクトに動員されているのではという都市伝説がありました。Javaの技術者だけではなく、様々な分野の技術者がみずほ銀行に投入されたものです。当時ITの景気はあまり良くなかったので、多くのIT会社がみずほ銀行のプロジェクトは「干天の慈雨」だったと聞いています。実際、一部の分野では技術者の手当が困難を極めたものです。まさか日本のITを下支えするために複雑なシステムにした訳ではないでしょうが。
ここで、もう一度レガシーシステムのモダナイゼーションについて見ていきましょう。一般には次の4つの方法があります。
| 名称 | 内容 |
|---|---|
| リビルド(Rebuild) | 現行システムをベースとして新システムを再定義する。 |
| リライト(Rewrite) | 現行システムのプログラムをベースとして、新言語に変換する。※COBOLからJavaなど |
| リホスト(Rehost) | 現行システムのプログラムを新言語に適合した状態にコンパイルしなおして稼働させる。※COBOLからOpenCOBOLなど |
| リプレース(Replace) | 新システムの構成を保持したまま、ハードウェアのみ変更する。 |
TIS株式会社の資料より
前記4つの方法はそれぞれ一長一短がありますが、一番失敗が多いのはリビルドになります。これは筆者の感想ではありません(参考:失敗しないレガシー・マイグレーション)。ですから、まずリプレースが可能か判断して、できなければリホスト、さらにできなければリライト、最後にリビルドを試していくのが順番でしょう。しかしプログラミング言語の変更はハードルが高いです。
そもそもCOBOL言語はALGOL系(ALGOL,C,Java...)の言語と非常に相性が悪いです。COBOLで最適化された設計というのは、ALGOL系では良い設計とはなりません。またCOBOLとオブジェクト指向との相性も良くありません。COBOLではデータと手続きは厳密に分離されています。1つの手続きが複数のデータを次から次へ処理するのがCOBOLの発想です。逆に一つのデータを複数の手続き(プログラム)で処理することもあります。COBOLから他の言語に自動で変換するツールもいくつかありますが、このような特性上あまりうまく行かないようです。結局、一からシステム全体の設計を見直し、個々のプログラムの設計を見直し、開発、テストと進んで行かなければなりません。実質リビルドですが、これは膨大な工数がかかります。ユーザーから見ると、膨大な工数をかけて作り直したのに、以前とあまり変わらないとしたら失望します、本当は以前と変わらないように作ったのですが。一方オブジェクト指向にすると生産性が高まるとか、保守が容易になると言われますが、オブジェクト指向でもプログラムは劣化していきます。その証拠に「リファクタリング」なる言葉がオブジェクト指向界隈でよく耳にします。もちろんオブジェクト指向にすればCOBOLより多少生産性や保守性は向上するでしょうが、そこに至るまでに膨大なコストをかける意味があるのか、大金はたいて僅かな利益を得る、バランスの問題となります。
みずほ銀行の開発の問題は何もCOBOLをJavaに変えたからだと言ってる訳ではありません。ポストモーテムの本の5章によれば、開発における様々な問題が浮き彫りになっています。しかし、メインフレームやCOBOLは良くないもの、とにかく早く取り除かなければという思いが開発側に多少でもあったのではないかと思うからです。
コンピュータシステムの設計に正解はないと言われますが、みずほ銀行の場合、多くのサブシステムをオープン系とJavaに切り替えたのは果たして正しかったのかどうか。筆者がこのような事を言うのも、システムをオープン系に全面切り替えた静岡銀行がリリース直後に多数の障害に見舞われた事件や、経済産業省のレポートに触発されて、第2、第3のみずほ銀行が出てこないのか懸念しているためです。みずほ銀行とは関係ありませんが、最近のデジタル庁と地方自治体の関係も同じ理由から心配です。
4.<教訓4>テクノロジーを過信するな
4.1 疎結合分散システムのワナ
最初に簡単な頭の体操をして見ましょう。統計的に1年に1度故障するサーバー(ハードウェア)があったとします。このサーバー1台で組んだシステムと、このサーバーを10台連結したシステムを考えて見ます。そうするとサーバー1台のシステムは1年に1度故障する。では10台連結したシステムでは、10年に1度故障するではなく、1年に10回故障する。何が言いたいかというと、分散システムはそれだけ障害が起きる確率が高いということです。
筆者は何も分散システムをやるなとか否定する訳ではありません。分散システムにはそれなりの長所もあります。何といっても障害を局所化するというメリットがあります。では障害を局所するとはどういう事でしょうか。例えば、銀行の例で見ると、ある支店は正常に動いているが、別な支店はトラブルで止まっている。或いは、あるATMは動いているけど別なATMは止まっている。またはある人の口座は正常な取引ができても、別の人はできない。このように、分散システムで動かした場合、末端では、部分的な不具合が起きることを想定してなければなりません。誰が?それは上は頭取から、下は支店の入り口で案内している派遣のオバサン、オジサンまで全てです。多くの人がシステムの細かな内容について理解している必要はありませんが、システムの特性について知っておく必要があるでしょう。また全支店が停止しても、一部の支店が止まっても同じようにマスコミの餌食になると言うことも覚悟しておかなければなりません。一部の障害で済んだから良かったとは、日本人は思いません。
分散が良いか、集中が良いか。これはコンンピュータの歴史が始まって以来、振子のように揺れ動いていました。ですからみずほが分散を選択するのは悪いこととは思いません。要は、分散を選んだ人が適切に説明すべきであったと思います。
余談ながら、大昔、コンピュータは大型であればあるほどコストパフォーマンスが上昇すると言われ、米国の学者が世界にコンピュータは4台あれば十分と宣わり、それを伝え聞いた日本の学者が、ぜひ1台をアジアへできれば日本へ誘致したいと真剣に議論していました。実際には、今やスマホを含めれば個人で4台も珍しくない世界になってしまいました。この話あまり笑えないのは、最近のクラウドの状況です。結局、米国3社と中国1社が世界のクラウドを支配しそうで怖いです。サーバーなんぞはもう市販されなくなるかもしれません。
4.2 テストを通しましたは信用できるか
「テストを通しました」この言葉は信用して良いものでしょうか。答えは否です。2021年3月7日のみずほ銀行のカードローンのトラブルの原因は結局委託先、再委託先で開発したプログラムを十分検証しなかったことに由来します。また2021年2月28日、みずほ銀行の一連のトラブルの最初にあった通帳のe口座への変更プログラムですが、事前のテストで問題を出すのは無理でしょう。結局、DBのインデックスがパンクしてしまう訳ですが、他のジョブのDBアクセス頻度との兼ね合いで発生する事象で、事前にテストで見つけることはできなかったでしょう。ここから得られる教訓は、我々は神ではない、人間です。完璧なシステムを作れないと同様に完璧なテストはできません。いくらテストを行なっていても、エラーはゼロになりません。
そうは言うもののテストをたくさんすれば、さまざまなエラーを事前に検知して、安全性の高いシステムができます。そんな事は小学生でも分かります。しかし、世の中テストを疎かにしてるプロジェクトが多いのも事実です。その理由は
時間が無い
人がいない
技術が無い
金が無い
先立つモノが無いのが一番の原因でしょう。テストが非常に難しいのは、それを実施してもしなくても、プログラムの機能に何ら影響を与えないということです。ある意味ここを省くことにより、コストを削減できるという誘惑に陥りやすいことです。コストだけではなく時間、人といったリソースも同様です。
この話はITだけではなく他の分野でも起こり得ます。ここ数年、日本の製造業で品質の問題が数多く出ていますが、以下のような言い訳が多いのも特徴です。
契約(又は法令)の定める検査は実施していませんが、納品した商品は性能、安全性に特段の問題はございません。
検査とか検証は、商品の機能には影響がないため、コスト削減の標的になりやすいです。度重なるコスト削減の圧力に耐えかねて、つい不正に手を染めてしまう。これはどこでも起きる可能性があります。
ITの場合、テストの見える化が重要なポイントになります。見積や契約の中にテストの実施を明記して工数(テスト実施のみならず、準備の工数も含む)を積み上げる。コンペの場合発注側がテスト内容やテスト結果について明記する。そうしないと、受注側がいくらでも削減しようとする。また最終のアウトプットの中にもログだけではなく、テストコードも含める。但し、これだけやっても全ての障害をなくすことができないと言うことをユーザー、ベンダーとも肝に銘じておくべきでしょう。
4.3 バベルの塔
旧約聖書によれば、人類は天にも上る塔を建設していたのですが、人間の傲慢さを見抜いた神は人々の言葉を乱し、お互いに通じないようにしました。この為塔の建設は中断を余儀なくされ、この町はバベルと呼ばれています(参考)。それ以来、人間は地域ごとに別な言葉を話すようになりました。
筆者もいろいろな会社/お客様でお仕事をしたのですが、ITの用語なんてどこでも同じだろうと高を括っていると、とんでもないしっぺ返しを喰らいます。実は会社によって微妙に意味が異なっていたり、考え方が違っているものです。みずほ銀行のプロジェクトで勘定系の開発を複数のベンダーに分けたこと、とてもコミュニケーションの取りずらくなってたことがあるのではないでしょうか。
IT用語の齟齬は実は会社間だけではなく、使用するOS、言語などの環境にもよります。例えばCOBOL文化圏では、ソース(SOURCE)プログラムをコンパイルするとオブジェクト(OBJECT)プログラムになります。これはオブジェクト指向プログラムが出現するはるか以前よりの決まりです。実際、SOURCE-COMPUTERとかOBJECT-COMPUTERなるキーワードが文法的に規定されていたと思います。さすがに今どき、COBOLのオブジェクトとオブジェクト指向のオブジェクトを混同する人はいないと思いますが、ITの世界では曖昧な用語がヤマのようにあり、お互いに意味を確定していないと後で大きな禍根を残すことになるかもしれません。例えばクラスとか、モデルとか、エンティティ、タスク等々お客様の発する言葉、ベンダーの発する言葉、ここにも誤解の種が隠されています。
5. <教訓5>日本の常識、世界の非常識
5.1 これは大きなトラブルか
筆者が直接確かめた訳ではありませんが、世界の中では銀行のシステムが止まるのは当たり前、ATMが通帳を飲み込んで返さないのも日常茶飯事と言う説があります。実際、シンガポールの最大手DBS銀行が2021年11月に2日間も停止しました。もちろんCEOは何のお咎めもなし。また米FRBも半日間システムが止まるなどの不都合がありました。何も銀行システムだけではありません。みんな大好きなGAFAMも、しょっちゅう止まるし、呆れるほど長時間止まっています。我々日本人は、そろそろシステムは絶対に止まらないと言う完璧主義の罠から脱却すべき時期に来ているのではないでしょうか。そもそも金融庁には、1年に1,500〜2,000件ぐらいの障害報告が全国の金融機関から上がっているそうです。この罠から抜け出せずにいると、IT労働者は、夜間残業、休日出勤の長時間労働を強いられ、人手不足の負のスパイラルに陥り、社会全体が不幸になります。ITムラもこの事を警告すべき時期に来ていると思います。
ITで日本とヨーロッパがアメリカに遅れをとった理由の一つとして、アメリカでは最初から完璧な商品を提供せず、とりあえず完成度の高くない商品なりサービスを出してユーザーの反応を見ながら改良を加えていく。こういうアメリカンプラグマティズムがITの商品、サービスとうまくはまったと思います。典型的なのがiphoneで、出始めの頃は繋がらない、熱くてヤケドしそうになる。一歩間違えれば消費者相談センター行きでしたが、改良を加えながらシェアを大きくのばしてきました。日本とヨーロッパでは、商品やサービスについてある程度完成度を高めないとダメと言ったところが出遅れた原因でしょう。もっとも1台10万円以上のスマホは壺ビジネスじゃないかと思いますけど、こんな事をしているとGAFAの落日もそう遠くはないと思います。奢る平家は久しからず。
5.2 パッケージ嫌いの日本人
みずほ銀行のトラブルの記事を見ると、パッケージを使えばよいのにとか、クラウドで実施すればと言う意見もありました。クラウドに関しては、そもそも富士、一勧、興銀3行統合時には影も形もなかったので、選択肢にはなり得なかったでしょう。ここでは少しパッケージについて考えてみたいと思います。
統計をとってるわけではありませんが、日本ではパッケージの導入に関する裁判沙汰は結構あると思います。これは外国製、国産に関わらず多いと思います。割と有名な国産ERPベンダーが訴訟をいくつも起こされて会社がガタガタになってしまったとか、IBMとスルガ銀行のトラブルも洋物パッケージが原因でした。しかも以前はベンダーが敗北するケースが圧倒的に多かった。結局、顧客からの細かい修正、追加要望がとても多く、それにアドオンでいちいち対応していく、最後対応しきれずにギブアップ状態になって顧客から訴えらえるという繰り返しです。断れば、別のベンダーがスクラッチで一から作ってしまいます。
よく日本人は同調圧力が強いと言われますが、筆者はこの論調にはあまり同意しません(参考)。逆にシステムの面で見ると、日本の企業、地方自治体は、よくもこんなにバラバラにシステムを組んだなと思えるほどです。パッケージをいれてもアドオンの山となっています。
なぜこんな事態になってしまったかと言うと、日本では競争が非常に激しくユーザーの要望を次々と取り入れないと、競争に負けてしまうからです。それと顧客に細かいこだわりがあり、差別化を好みます。日本では、日本酒にしろ、醤油にしろ、味噌にしろ何百、何千と言う小さな会社が独自ブランドを提供してちゃんとビジネスになってます。こだわりで言えば、有名な話でネスレ社のKitKatというお菓子が世界中で売られているのですが、大体どこの国でも数種類しか売られていないのに、日本だけ何百種類も売られています。訪日外国人が面白がってお土産に買って行くという状態です。この細かいこだわりの強さが、IT分野で様々な追加要望に結びついていると思います。最近デジタル庁が、地方自治体と組んで統一したシステム作りを模索していますが、この辺の折り合いがうまく取れるのか見ものです。
5.3 言うべきことを言わない、言われたことしかしない
これが金融庁の文章から出たのは驚きです。数年前に言うべきことを言えずに自殺に追い込まれた役人がいたと言うのに、あれは財務省か。この文を金融庁の職員が書いたのか、出入りのコンサルかいずれにしても、もう少し言い方があったのではないでしょうか。例えば「心理的安全性」を高める組織に変えていくべきだとか。
筆者も長年いくつかのIT現場を回ってよく耳にするのが「あいつは評論家だから」と言うものです。要するに、色々と言うのだが、自分では何もしない責任も取らない。またベンダーの立ち位置では、提案するのは構わないのだけど、お金を払ってくれないのであれば仕事を増やすだけで会社が損する。だから黙っていた方が得なわけです。なお、全国の評論家の皆さんこれは決して職業を馬鹿にしているわけではありません。また、オマエはどうなんだと言われれば、はい、過去に何度も知ったかぶりをして多くの人にご迷惑ご心配をおかけしました。
この件で思い出したのですが、「日本の企業はOSにパッチを当てないで放置しているところが多い。問題だ!」こういう内容の記事を見たことがあります。これOSにパッチを当ててアプリケーションが突然動かなくなる。こういう悲劇を経験した人でないと中々わからないのですね「被災者にしか本当の気持ちが理解できない。」と言うやつですね。事前にアプリのテストをすれば良いだろうとも言われますが、数千本、いや万単位のプログラムのテストが簡単にできる訳がありません。よしんば数百本のプログラムで済んだとして、例えば数個のパッチを当てるだけで膨大なテスト工数をベンダーに請求されたら、あなたは支払いますか。おそらく現状では本当に必要なパッチだけ当てて、定常処理の確認で終わりというのが一般的な流れです。ここで問題が起きてもお互いに文句言わないという大人の対応でほとんど済ませていると思います。逆にパッチを当てないで起きる不具合についても同様だと思います。そういう意味でパッチを当てないというユーザーの判断も理解できます。つまりOSのパッチですら、苦渋の決断をしながら当てているのです。
6. おわりに
2つだけ書いておきます。
1つ目、みずほ銀行のトラブルですが、ITムラにとって一番 不都合な真実は何かといえば、メインフレーム+COBOLでガッチリ作ってる、三菱UFJ銀行や三井住友銀行ではあまり大きなトラブルが出ず、メインフレーム+COBOLを中心に残すも、オープン系サーバー+Javaで多くを構築したみずほのシステムでトラブルが頻発した事でしょう。実際、ポストモーテムの本でもサラっと触れていますが、三井住友銀行でメインフレームからオープン系への全面刷新を3年間と50億円の費用をかけて調査・検討(普通の会社なら10個くらいシステムができてしまう)したにもかかわらず、みずほ銀行の2011年のトラブルを見て刷新をやめてしまった事です。筆者は何も古いもの固執しろと言ってる訳ではありません。古いものについて何でも切り捨てるのではなく、何故そうなってるのか、十分に理解を深めつつ新しいものに取り組むべきだと思います。レガシーに取り組む人には温故知新と言う言葉を送りたいと思います。
2つ目、日本では、AIとかDXが今一つ伸び悩んで、ブームも去り、もうオワコンかの声も聞かれます。経営者がとか、抵抗勢力がとか、泣きが入るケースがあります。しかしユーザーの立場にたてば、いざAIだDXだとベンダーに煽られて導入してみたものの、使い物にならなければ金をドブに捨てることになります。いや使えないのならまだしも、みずほ銀行のような大トラブルにみまわれたら目も当てられません。新しいことに挑戦して失敗して某雑誌の 「動かないコンピュータ」 に掲載されるくらいなら、古いモノにこだわっていた方が安全な訳です。このような状況にどう対応していけば良いでしょうか。ユーザーが一番困るのは今動いているものが動かなくなることです。繰り返しになりますが、AIやDXを現行システムに適用するのではなく、新しく作るシステムに適用することが肝心かと。さらにこれもコロナ禍が参考になるかもしれませんが、お隣の国のゼロ・コロナでは何も進まず経済は止まったままです。同じようにゼロ・リスクでは何事も前に進みません。ITムラの方には、萎縮することなく挑戦してもらいたいです。そして失敗しても新しいモノを育む文化がなければ、WEB3.0も、メタバースも、量子コンピュータも、日本では一つも成功しないでしょう。