はじめに
Papers with Codeにて論文を斜め読みしていたら、一度学んでみたかった技術である白黒画像のカラー画像化について紹介されていました。
概要を訳しましたので、参考になれば幸甚です。
Instance-aware Image Colorization
https://paperswithcode.com/paper/instance-aware-image-colorization
物体分割を利用した白黒画像のカラー画像化技術について、最近arxiv上に掲載されたものです。
要約:Abstract
- カラー画像化は、マルチモーダル[*1]な不確実性を含んでいることが問題である。
- 既存のモデルは、画像全体で学習及びカラー化を行っていたため複数のオブジェクトがあると失敗する。
- 著者らは既成のオブジェクト検出器を用いて、領域分割と画像レベルの特徴づけを行った。
- 既存の手法と比較して優れた性能を見出した。
*マルチモーダル:動物の五感を指す意味と理解しました。直感的に物体が何者か認識できること等。
1.背景:Introduction
白黒画像をもっともらしいカラー画像へ変換することは、今注目の研究テーマである。
しかし、白黒画像から2つの欠落したチャンネルを予測することは、本質的に難しい問題がある。
さらに物体の色付けには複数の選択肢があるため、色付け作業は複数解釈できる可能性がある(例えば、車両は白、黒、赤など)。
従来報告されてきた技術では、雑然とした背景上に多数物体がある場合は上手くカラー化されない課題があった(下記図)。

本論文では、上記の問題点を解決するために、新しいディープラーニングのフレームワーク及び領域分割を意識した色分けを実現した。
特にポイントとして、物体と背景を明確に分けることがカラー化の性能改善に効果があることが分かった。
著者らのフレームワークは大きく以下の3つから成る。
- 領域分割及び、分割された物体画像を生成するための既製の事前学習モデル
- 分割された物体及び画像全体のカラー化のために学習された2つのバックボーンネットワーク
- 2つのカラー化ネットワークのレイヤーから抽出された特徴を選択的に混ぜるための融合モジュール
2.関連技術:Related works
学習に基づいたカラー化Learning-based colorization
近年、機械学習を利用したカラー化処理の自動化が注目されている。既存の研究の中では、大規模なデータセットから色予測を学習するために、深層畳み込みニューラルネットワークが主流となっている。
領域分割に基づいた画像生成・操作:Instance-aware image synthesis and manipulation
領域分割を考慮した処理によって、物体と地面の分離が明確になるため、視覚的な外観の合成と操作が容易になる。
- 単一物体に注目するDC-GAN, FineGANと比較して、複雑な領域について対応可能
- 重なりが自然にみえる技術であるInstaGANと比較して、同時に全て重なっている可能性を考慮可能
- 合成の品質を改善するため領域分割の境界を使っているPix2PixHDと比較して、学習された重みづけを多数の領域合成で使用
3. 概観:Overview
本システムでは、白黒画像$X∈R^{H×W×1}$を入力とし、その欠落した2つの色チャンネル$Y∈R^{H×W×2}$を$CIE L∗a∗b∗色空間$内でエンドツーエンドで予測する。
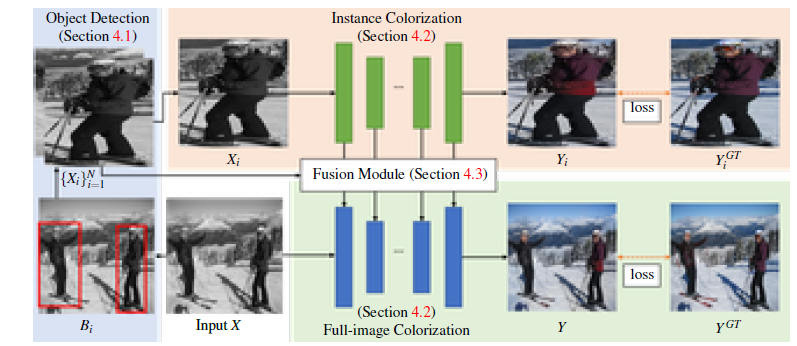
下記図にネットワークの構成を示す。まず事前学習済み物体検出器を用いて、白黒画像から複数の物体バウンディングボックス$(B_i)^N_{i=1}$($N$はインスタンス数)を取得する。
次に、検出したバウンディングボックスを用いて白黒画像から切り出した画像をリサイズして、インスタンス画像$(X_i)^N_{i=1}$を生成する。
次に、各インスタンス画像$X_i$と入力グレースケール画像$X$を、それぞれインスタンスカラー化ネットワークとフルイメージカラー化ネットワークに流す。ここでは、第$j$番目のネットワーク層におけるインスタンス画像$X_i$とグレースケール画像$X$の抽出された特徴マップを$f^{Xi}_j$及び $f^X_j$と呼ぶ。
最後に、各層のインスタンス特徴量$(f_j^{Xi}) ^N_ {i=1}$とフル画像特徴量${f_j^X}$を融合する融合モジュールを用いる。融合された全画像特徴$f^X_j$は、$j+1$番目のレイヤーに転送される。このステップを最後の層まで繰り返し予測カラー画像$Y$を得る。
本研究では、まず全画像ネットワークを学習し、次にインスタンスネットワークを学習し、最後に上記2つのネットワークをフリーズさせて融合モジュールを学習するという逐次的なアプローチを採用している。
4.手法:Method
4.1物体検知 Object detection
検出した物体インスタンスを利用して画像の色付けを行う。このために、物体検出器として市販の事前学習済みネットワークMask R-CNN を用いた。
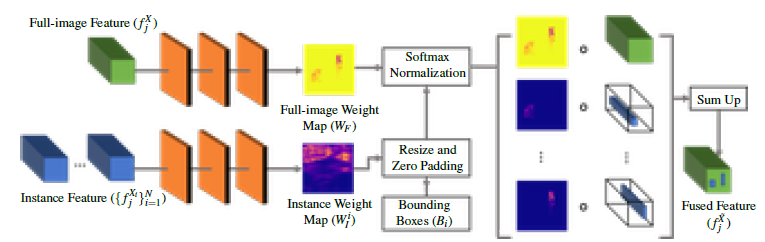
4.3.融合モジュール:Fusion module
融合モジュールは、以下のような入力を受け取ります。融合モジュールは、(1)フル画像の特徴量$f^X_j$、(2)インスタンス特徴量の束とそれに対応するオブジェクト境界ボックス$(f_j^{Xi}) ^N_ {i=1}$を入力とする。 両種類の特徴に対して、3つの畳み込み層を持つ小型のニューラルネットワークを考案し、フル画像重みマップ$W_F$とインスタンス毎の重みマップ$W_I^i$を予測する。
4.4.損失関数と訓練:Loss Function and Training
ネットワーク全体を以下手順で学習する。まず、全画像色化を学習し、学習した重みをインスタンス色化ネットワークに転送して初期化します。 次に、インスタンス色化ネットワークを学習する。最後に、全画像モデルとインスタンスモデルの重みを解放し、融合モジュールの学習に移る。
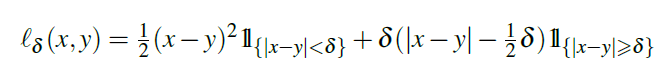
5.実験:Experiments
5.1.実験条件:Experimental setting
データセット:Dataset
- ImageNet, COCO-Stuff, Places205の3つのデータセットを使用
訓練手法:Training details
ImageNetデータセットについて以下の3つ訓練プロセスを実施した。
- 全画像カラー化ネットワーク:既存のモデルの重みパラメータで初期化(学習率$10^{-5}$)
- 領域分割ネットワーク:データセットから抽出されたインスタンスでモデルをファインチューニング
- 融合モジュール:13層のニューラルネットワークで融合
- 最適化手法はADAMを使用( $\beta_1=0.99, \beta_2 = 0.999$)
- 単一のRTX 2080Ti GPUを使って3日間訓練させた(ImageNet)
5.2.定量値の比較: Quantitative comparisons
Comparisons with the state-of-the-arts.
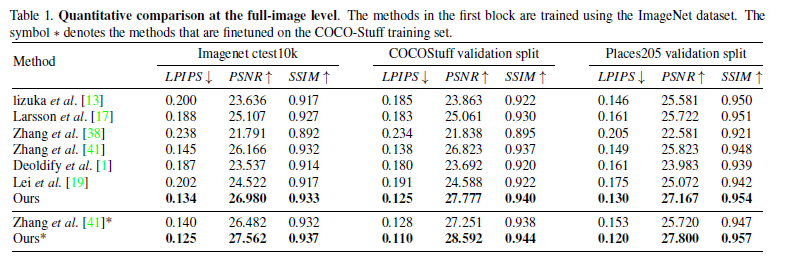
3つのデータセットに関する定量値の比較を上表に示す。どの指標においてもこれまでの方法より良いスコアとなった。
※
LPIPS:元画像と潜在空間に射影した後、画像を再生成したものとの距離(低いほど距離が近く似ている)
SSIM:輝度、コントラスト、構造を元に周囲のピクセル平均、分散・共分散をとったもの
PSNR:2枚の画像で同じ位置同士のピクセルの輝度の差分を2乗したもの(高いほうが高画質)
User study
参加者には、着色した結果のペアを見せ、好みを尋ねる(強制選択比較)。その結果、Zhanget al. (61%対39%)、DeOldify(72%対28%)と比較して平均的に著者らの手法が好まれる結果となった。
興味深いことに、DeOld-ifyはベンチマーク実験で評価された正確な着色結果が得られないが、飽和着色された結果の方がユーザに好まれることがある。
5.7失敗例:Failure cases

上図に 2 つの失敗例を示す。著者らの手法では、色が洗い流されていたり、オブジェクトの境界をまたいでいるような目に見えるアーチファクトが発生する可能性がある。
6.結論: Conclusions
本研究では、既製のオブジェクト検出モデルを用いて画像を切り出すことで、インスタンスブランチとフルイメージブランチから特徴量を抽出した。
そして、新たに提案したフュージョンモジュールと融合させることで、より良い特徴量マップを得ることを確認した。実験の結果、既存の手法と比較して、3つのブランチマークのデータセットにおいて、本研究の成果が優れていることが示された。
終わりに
領域分割(インスタンスセグメンテーション)技術を取り入れたカラー画像化の技術を学びました。
技術自体は理解できたのですが、カラー画像化したときに尤もらしい画像であることを定量的に議論することの難しさを感じました。
車の色や草木の色など、複数の選択肢がある場合、どれがもっともらしいかと決めるアルゴリズムをどのように決めるのでしょう。
著者らは人に判断してもらうテストもしていますが、このマルチモーダルな領域についてアルゴリズムができるとより人工知能感ある技術になるのでしょう。