はじめに
ベイズ統計学について絶賛勉強中です。今回は混合モデルと事後分布の推論に関して、考え方を整理しました。
今回も参考にさせて頂いた資料は下記です。
ブログ記事としてもこちらにまとめました。
https://fumio-eisan.hatenablog.com/entry/2020/05/22/171742
混合モデルと事後分布の推論
確率分布を予測するうえで、観測データを単純な離散分布やガウス分布で近似することは解析的に可能です。
しかしながら、現実の複雑な観測データや課題の解決を行うためには、これら離散分布やガウス分布を単体で表すことは不十分な場合が多いです。
従い、実際は**混合モデル(mixture model)**と呼ばれる考え方を適用して、確率分布を細かくブロックごとに分けてモデルを構築することが多いです。この考え方により、モデルの表現力を高めることができるのです。
下記例で考えてみましょう。
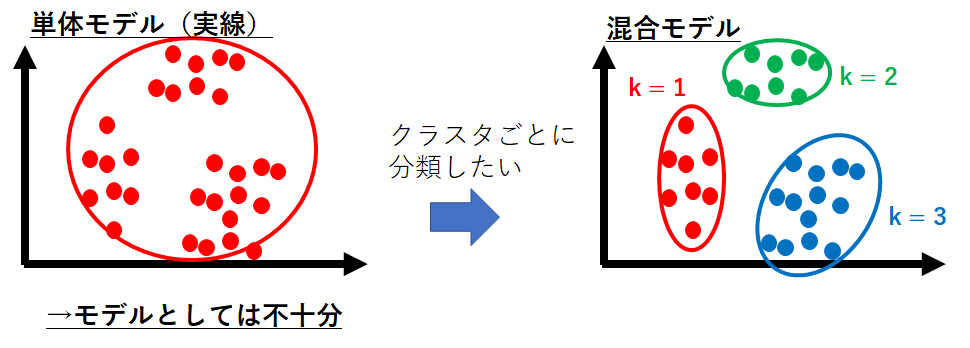
この観測データは、**クラスタ(cluster)**と呼ばれる集団が複数個ありそうなことが推測できます。これを、単一の2次元ガウス分布で表そうとすると左図のようになります。
これはクラスタの構造を表現できているといえません。
このようなデータはクラスタ数が3個のガウス混合モデルを使うことで表現が可能になります。それが右図のような形になるのです。
混合モデルのデータ生成過程
さて、この混合モデルを構築するアルゴリズムについて考えてみます。$N$個のデータ$X ={\bf x_1,...x_N}$が生成される過程を次のように決めるとします。
ここでクラスタ数は$K$とします。
- クラスタの混合比率$ \bf {π} = (π _ {1}, ... ,π _ {K}) ^ {T}$が事前分布$p(\bf π)$から生成される。ただし、$π_ {k} \in (0,1)$ かつ$\sum _ {k=1} ^ {K} π _ {k} = 1$
- それぞれのクラスタ $k = 1,...K$ に対する観測モデルのパラメータ $θ _ {k}$(平均値、分散等)が事前分布$p(θ_{k})$から生成される
- $n = 1,...N$ に関して、$\bf x_ {n}$ に対応するクラスタの割り当て$\bf s _ {n}$が比率$π$によって選ばれる。
- $n = 1,...N$ に関して、$s _ {n}$によって選択された$k$ 番目の確率分布$p(\bf{x} _ {k}|θ _ {k})$ からデータ$\bf x _ {n}$ が生成される
このようなアルゴリズムを通して$N$個全てのデータ$X = x _ 1,... x _ N$が生成されたとします。このように、データの生成過程に関する過程を元に構築したモデルを**生成モデル(generative model)**と呼びます。
この例で出てきた$s _ n$は隠れ変数(hidden variable)、または**潜在変数(latent variable)**と呼ばれます。つまり、$x _ n$を発生させる確率分布を潜在的に決めている因子であることを意味しています。
確率分布の意味付け
先に説明したステップ4.について、点$x _ n$に対する確率分布を定義します。クラスタの数$ K $個の確率分布を用意する必要があります。つまり、
p(x _ n| θ _ k) = \mathcal{N}(x _ n|μ _ k, \Sigma _ k) \hspace{1cm} for \hspace{0.1cm} k=1,...K
と表すこととします。ここで$θ = {μ _ k, \sigma _ k}$を観測モデルのパラメータとしています。
続いて、ステップ3の$K$個の観測モデルを各データ点に割り当てる手段ですが、$s _ n$に対して$1 of K$表現を適用します。
p(s _ n|\pi) = Cat(s _ n|\pi) \hspace{1cm} \sum _ {k = 1} ^ {K} \pi _ k =1
ここで、$\pi$として混合比率を定義しています。
ステップ3,4を組み合わせると、$x _ n$を生成するための確率分布をは下記と表すことができます。
p(x _ n |s _ n,\Theta) = \prod _ {k=1} ^ {K} p(x _ n|\theta _ k) ^{s _ {n,k}}
ここで、観測モデルのパラメータを$\Theta = {\theta _ 1 ,....\theta _ K}$としてまとめて書いています。
次にステップ2に関してですが、これはステップ4.で定義した観測モデルのパラメータ$\theta _ k$に関する事前分布$ p(\theta _ k)$を定義します。
最後にステップ1.の混合比率$\pi$についてです。こちらも十分な量のデータが観測されるまでは、未知である場合が多いです。従い、何らかの事前分布を持たせると良いでしょう。
$\pi$はカテゴリ分布のパラメータなので、共役事前分布である$K$次元のディリクレ分布とします。
p(\pi) = Dir (\pi|\alpha)
ここで$\alpha$は$K$次元ベクトルのハイパーパラメータとします。
さて、これまでの確率分布を用いて$N$個のデータに関する同時分布を考えることでモデル全体を表すことが可能になります。
p(X, S, \Theta, \pi) = p(X, S, \Theta)p(S, \pi)p(\Theta)p(\pi)\\
=( \prod _ {n=1} ^ {N} p(x _ n| s _n , \Theta)p(s _ n, \pi))( \prod _ {k=1} ^ {K}p(\theta _ k))p(\pi)\\
ここで、$S={s _ 1 ,... ,s _ N}$とおきました。この混合モデルにおける観測モデル$p(x _ n|\theta _ k )$と対応する事前分布$ p(\theta _ k)$を定義することによってポアソン混合やガウス混合モデルといった具体的な例を作っていくことになるのです。
混合モデルの事後分布
さて、混合モデルにおいて推論問題を考えます。観測データ$X$から未知の変数$ S, \pi, \Theta$の事後分布を計算する必要があります。これは、
p(S, \Theta, \pi|X) = \frac {p(X, S, \Theta, \pi)}{p(X)}
と表される条件付き分布となります。また、データ$X$が属するクラスタ$S$の推定を行うためには、
\begin{align}
p(S|X) = \int\int p(S, \Theta, \pi|X)d\Theta d\pi
\end{align}
とおいて計算すれば良いのです。
しかし、混合モデルにおいてこれらの計算が非常に負荷がかかる、または解析的に解けない場合が発生します。従い、[tex:p(X)]の計算を真面目にやろうとすると下記の周辺化が必要です。
\begin{align}
p(X ) &= \sum_ S \int \int p(X, S, \Theta, \pi)d\Theta d\pi\\
&=\sum _ S p(X, S)
\end{align}
この2行目については$S$の取りうる全て組み合わせについて評価する必要があり、$K ^ N$解の計算が必要になります。データ数$N$は機械学習では非常に膨大な数字のため、計算が現実的ではありません。
従い、ここで近似推論といった考え方で計算を進めていく手法が現在一般的となっています。
終わりに
今回は、混合モデルの表現方法及び事後分布についてまとめました。次回は実際にこれを近似する手法をまとめられればと思います。