はじめに
ニューラルネットワークにおける最適化手法は日々新しいアルゴリズムが生み出されています。前の記事では、SGDからADAMまでその開発された経緯をまとめました。
今回の記事では、その最適化手法を実装して、ニューラルネットワークにおける収束の速さを確認したいと思います!。といきたいところですが、今回はこの最適化手法を簡単な2次関数に適用したいと思います。
教科書などでは基本的にはMNISTなどの手書き数字画像を例にとって損失関数の値が下がっていくことを確認します。しかし、ニューラルネットワークにおける損失関数は非常に複雑であるため、いまいち最小値を導けているのか実感がわきません。
従って、今回は2次関数を例にすることで、最小値へ向かっていくことを見ていきたいと思います。
また、自分でクラスを定義して読み込むことを実装しましたが、そこで理解したことも記しておきます。
今回の概要です。
- 対象とする関数
- SGD(確率的勾配降下法)を実装する
- Momentumを実装する
- AdaGradを実装する
- class,initについて理解したこと
対象とする関数及び最適化手法の目的
今回対象にする2次関数及び最適化手法で行いたい目的はこちらです。

非常にわかりやすい関数の最小値を求めることとしました。$y=x^2$ですので、最小値を取る$y$は$x=0$のときに、$y=0$となります。
感覚的にも可視的にも分かりやすいこの関数を用いて、$x$を更新し続けて$y=0$に近づいていくことを確認していきたいと思います。
実装の内容
今回は、関数を定義したプログラムをoptimizers.pyへ格納しています。そして、sample.ipynbにてその関数を読み込み計算・図示させる構成にしています。
従って、実装の際はこの2つのプログラムを同一フォルダに格納して実行して頂けると幸甚です。
SGD(確率的勾配降下法)を実装する
まずは、基本となるSGDです。下記に式を記載しています。
\mathbf{x}_{t + 1} \gets \mathbf{x}_{t} - \eta g_t\\
g_t = 2 *\mathbf{x}_{t}
$\eta$は学習率、$g_t$は関数の勾配になります。$g_t$は今回は$2 *\mathbf{x}_{t} $となるため、簡便ですね。
次に、この手法を実装します。
class SGD:
def __init__(self, lr = 0.01,x=100):
self.lr = 0.01
self.x =100.0
def update(self,x):
x+= -self.lr * 2*x
return x
式自体はシンプルですので、プログラムを見て理解しやすいかと思います。次ステップの$x$を計算して$x$を返すといった関数にしています。$\eta$はここでは$lr$という表記になっています。
さて、実際に最小値を求めるために$x$を繰り返し計算させるプログラムがこちらになります。
max_iterations = 100
y7=[]
y8=[]
y9=[]
v7=[]
v8=[]
v9=[]
optimizer = optimizers.SGD()
x = 100
optimizer.lr =0.1
for i in range(max_iterations):
x = optimizer.update(x)
y7.append(x)
v7.append(optimizer.lr)
x = 100
optimizer.lr =0.01
for i in range(max_iterations):
x = optimizer.update(x)
y8.append(x)
v8.append(optimizer.lr)
x = 100
optimizer.lr =0.9
for i in range(max_iterations):
x = optimizer.update(x)
y9.append(x)
v9.append(optimizer.lr)
$\eta$を0.1,0.01,0.9と変化させたときに関数の収束がどのように変化するか確認しましょう。
※xを初期値化させることや、lrすら変数としてfor loopとする案が思いつかなかったため、汚いプログラムとなっています。
x = np.arange(max_iterations)
plt.plot(x, y7, label='lr=0.1')
plt.plot(x, y8, label='lr=0.01')
plt.plot(x, y9, label='lr=0.9')
plt.xlabel("iterations")
plt.ylabel("y")
plt.ylim(-5, 120)
plt.legend()
plt.show()
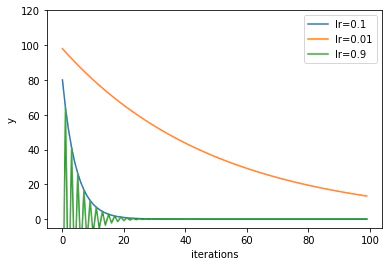
縦軸である$y$の値が0に近づくほど収束していくことが分かります。
$\eta$が0.01だと収束に時間がかかります。$\eta$が逆に0.9まで大きすぎるとハンチングしながら収束に向かうことが分かります。この値が今回の関数だと1以上だと発散してしまいます。従って、$\eta$が0.1あたりが収束も早く発散を抑えられる丁度良い値であることが分かります。
Momentumを実装する
次にMomentumを実装していきます。このアルゴリズムは先ほどのSGDと比較して、$x$自身の動きを考慮させることで振動を抑えるようにしています。
\mathbf{x}_{t + 1} \gets \mathbf{x}_{t} + h_t\\
h_t=-\eta * g_t +\alpha * h_{t-1}
関数を定義します。
class Momentum:
def __init__(self,lr=0.01,alpha=0.8,v=None):
self.lr = 0.01
self.v = 0.0
self.alpha = 0.8
def update(self,x):
self.v = self.v*self.alpha - (2.0)*x*self.lr
x += + self.v
return x
そして、実行します。今回は、ハイパーパラメータとして$\alpha$の値を変化させて影響を評価します。
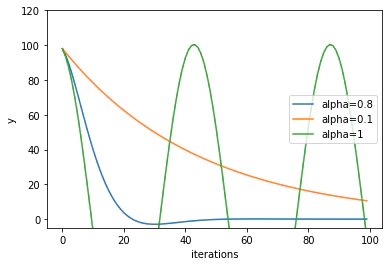
標準的な$\alpha$は0.8といわれています。今回の結果でも0.8が丁度よさそうな値であることが分かります。これ以上値が大きいと、大きくハンチングしてしまっていますね。
AdaGradを実装する
さて、今回最後はAdaGradです。これまでは学習率$\eta$は定数でした。しかしこの学習率自体が計算回数につれて段々小さくなっていく効果を入れていることが特徴です。
h_{0} = \epsilon\\
h_{t} = h_{t−1} + g_t^{2}\\
\eta_{t} = \frac{\eta_{0}}{\sqrt{h_{t}}}\\
\mathbf{x}_{t+1} = \mathbf{w}^{t} - \eta_{t}g_t
関数を定義します。
class AdaGrad:
def __init__(self,h0=10.0):
self.v = 0.0
self.h = 0.0
self.h0 = 10.0
def update(self,x):
self.h += + (2.0*x)**2
self.v = -self.h0/(np.sqrt(self.h)+1e-7)
x += + self.v*2*x
return x
さて、今回は学習率の初期値$\eta_0$(プログラム中ではh0)を変えて計算しました。
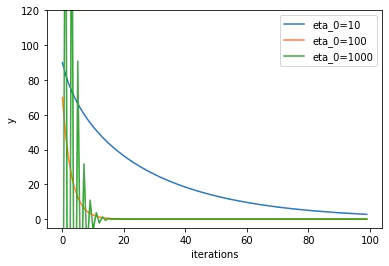
$\eta_0$は100あたりが収束も早くなり、かつ発散しないことが分かりました。
class,initについて理解したこと
Pythonに関して初学者であるため、classの中でもinitに関してはおまじない感強く使っていました。今回、分かったことは下記です。
-
init(self,引数)で定義した引数は、classを呼び出した後に引用して引数のパラメータを変えることができる。
-
逆にこの引数を書いておかないと、classを呼び出した後にパラメータを変えることができない。
おわりに
今回は3種類の最適化手法によって関数の最小化を行わせました。いわゆる高校数学で習う漸化式の考え方を用いることが分かります。また、numpy以外は自作しましたが、プログラミング自体の理解を深めることに繋がりました。
また、オライリーの深層学習本で学んでいますが、ここには実際にニューラルネットワーク上で最適化手法を実装しています。
関数や細かい変数の定義、活性化関数の入れ方、逆誤差伝搬法での勾配算出、重みパラメータの初期値決め等一つ一つの内容は理解できます。しかし、それをいざプログラミングするとなると非常に複雑になっていきます。
改めて、プログラマーの方はこれら多くの規則や構造に関する知識を組み合わせて実装されているんだなぁ、さぞかし大変な苦労なんだろう、と思いを巡らせました。その苦労を元にクラスやメソッドとして呼び出して簡単に機能を使えることにありがたみを感じたいと思います。
プログラム全文はこちらに格納しました。
https://github.com/Fumio-eisan/optimizers_20200326