超軽量LLMのflan-t5-baseをPPO(Proximal Policy Optimization)でファインチューニングしてみました。今回の目的はプログラムを動かすことなので訓練のハイパーパラメータやモデル改善度など基本的に見ていません。いずれ本格的に実行する時の足がかりに、と思ってやりました。
CPUでは実行できませんでしたが、Google Colabで無料でも使えるT4 GPUで実行できました。動かすことを目的としているので、精度などはあまり見ていません(時間制限を気にせず使えるようにColab Pro契約してます)。
実行環境
2024/4/14時点のGoogle Colab で、Python3.10.12で、以下のパッケージを主に使っています。numpyなど少しだけ使っているやつは省略。
| Package | Version | 備考 |
|---|---|---|
| torch | 2.2.1+cu121 | Google Colabにプリインストールされていたバージョン |
| transformers | 4.38.2 | Google Colabにプリインストールされていたバージョン |
| datasets | 2.18.0 | 追加でpip install |
| evaluate | 0.4.1 | 追加でpip install |
| peft | 0.10.0 | 追加でpip install |
| trl | 0.8.3 | 追加でpip install |
結果サマリ
RoBERTaのヘイトスピーチモデルを使ったToxicity判定で、0.022から0.012へとToxicityが低下しました。PPOは30分ほど訓練しています。
Jupyterで同じセルを何度か実行したりしていたので、結果の再現性がないかもしれません。
実行プログラム
1. 準備系
1.1. pip intall と import
Google Colab にプレインストールされていないdatasetsをインストール。出力が長くて邪魔だったので--quietオプションつけています。
!pip install datasets evaluate peft trl --quiet
import time
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification,\
AutoModelForSeq2SeqLM, GenerationConfig, TrainingArguments, Trainer
from datasets import load_dataset
from peft import LoraConfig, TaskType, get_peft_model
# trl: Transformer Reinforcement Learning library
from trl import PPOTrainer, PPOConfig, AutoModelForSeq2SeqLMWithValueHead
from trl import create_reference_model
from trl.core import LengthSampler
import torch
import evaluate
import numpy as np
import pandas as pd
from tqdm import tqdm
1.2. 固定値定義
固定値定義です。使う直前に書いた方がわかりやすいかも、と迷いましたが冒頭で定義しました。
#MODEL_NAME = "google/flan-t5-small"
MODEL_NAME="google/flan-t5-base"
TOXICITY_MODEL_NAME = "facebook/roberta-hate-speech-dynabench-r4-target"
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
NON_TOXIC_TEXT = "#Person 1# tells Tommy that he didn't like the movie."
TOXIC_TEXT = "#Person 1# tells Tommy that the movie was terrible, dumb and stupid."
NOT_HATE_INDEX = 0
# 後でmax_new_tokensを生成ごとに追加
generation_kwargs = {
"min_length": 5,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True
}
REWARD_LOGIT_KWARGS = {
"top_k": None, # Return all scores.
"function_to_apply": "none", # You want the raw logits without softmax.
"batch_size": 16
}
1.3. データセットとTokenizerダウンロード
knkarthick/dialogsumをダウンロード。
dataset = load_dataset("knkarthick/dialogsum")
print(dataset)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, device_map="auto")
ターミナルに出力したknkarthick/dialogsumです。この後、PEFT用とPPO用の2種類に編集します。
DatasetDict({
train: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 12460
})
validation: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 500
})
test: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 1500
})
})
1.4. データセットをPEFTファインチューニング用に編集
データセットをPEFTファインチューニング用に編集します。PEFTモデルはPPOファインチューニングの元モデルです。
ここと次でやっている内容は前に書いた記事と同じです。
def add_instruction(dialogue):
start_prompt = 'Summarize the following conversation.\n\n'
end_prompt = '\n\nSummary: '
prompt = start_prompt + dialogue + end_prompt
return prompt
def tokenize_function(example):
prompt = [add_instruction(dialogue) for dialogue in example["dialogue"]]
example['input_ids'] = tokenizer(prompt, padding="max_length",
truncation=True, return_tensors="pt").input_ids
example['labels'] = tokenizer(example["summary"], padding="max_length",
truncation=True, return_tensors="pt").input_ids
return example
def build_peft_dataset(dataset, tokenizer):
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 不要列削除
tokenized_datasets = tokenized_datasets.remove_columns(['id', 'topic', 'dialogue', 'summary',])
# 1/10に削減
tokenized_datasets = tokenized_datasets.filter(
lambda example, index: index % 10 == 0, with_indices=True)
print(f"Shapes of the datasets:")
print(f"Training: {tokenized_datasets['train'].shape}")
print(f"Validation: {tokenized_datasets['validation'].shape}")
print(f"Test: {tokenized_datasets['test'].shape}")
print(tokenized_datasets)
return tokenized_datasets
datasets_peft = build_peft_dataset(dataset, tokenizer)
編集後のデータセット内容です。
Shapes of the datasets:
Training: (1246, 2)
Validation: (50, 2)
Test: (150, 2)
DatasetDict({
train: Dataset({
features: ['input_ids', 'labels'],
num_rows: 1246
})
validation: Dataset({
features: ['input_ids', 'labels'],
num_rows: 50
})
test: Dataset({
features: ['input_ids', 'labels'],
num_rows: 150
})
})
1.5. PEFTファインチューニング
PEFTモデルを定義してファインチューニングします。だいたい20分ほどかかりました。
def print_number_of_trainable_model_parameters(model):
trainable_model_params = 0
all_model_params = 0
for _, param in model.named_parameters():
all_model_params += param.numel()
if param.requires_grad:
trainable_model_params += param.numel()
print(f"訓練可能パラメータ: {trainable_model_params:,}")
print(f"全パラメータ: {all_model_params:,}")
print(f"訓練可能パラメータ割合: {100 * trainable_model_params / all_model_params:.2f}%")
def peft_fine_tune(dataset, tokenizer):
output_dir = f'./peft-dialogue-summary-training-{str(int(time.time()))}'
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME,
torch_dtype=torch.bfloat16)
lora_config = LoraConfig(
r=32, # Rank
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM # FLAN-T5
)
peft_training_args = TrainingArguments(
output_dir=output_dir,
auto_find_batch_size=True,
learning_rate=1e-3, # Higher learning rate than full fine-tuning.
logging_steps=50,
max_steps=500
)
peft_model = get_peft_model(model, lora_config)
peft_trainer = Trainer(
model=peft_model,
args=peft_training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"]
)
peft_trainer.train()
print_number_of_trainable_model_parameters(peft_trainer.model)
return peft_trainer.model
peft_model = peft_fine_tune(datasets_peft, tokenizer)
訓練結果のロスとパラメータ情報です。
Step Training Loss
50 9.675700
100 0.391400
150 0.222100
200 0.196300
250 0.169400
300 0.167200
350 0.165700
400 0.162600
450 0.156000
500 0.164100
訓練可能パラメータ: 3,538,944
全パラメータ: 251,116,800
訓練可能パラメータ割合: 1.41%
2. PPO ファインチューニング
ここからが今回の本題のPPO ファインチューニングです。
2.1. データセットをPPOファインチューニング用に編集
ある程度長いものにし、読みやすくするため200文字以上、1000文字以下のデータにフィルタ。デコードしたダイアログ文をqueryとして保存し、訓練とテストデータセットに分割。
def build_ppo_dataset(dataset, tokenizer):
# 200から1000文字以内のデータに限定
dataset_train = dataset.filter(lambda x: len(x["dialogue"]) > 200 and len(x["dialogue"]) <= 1000, batched=False)
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(add_instruction(sample["dialogue"]))
# PPO では"query"とする決まり
sample["query"] = tokenizer.decode(sample["input_ids"])
return sample
dataset_train = dataset_train.map(tokenize, batched=False)
dataset_train.set_format(type="torch")
dataset_splits = dataset_train.train_test_split(test_size=0.2, shuffle=False, seed=42)
return dataset_splits
dataset_ppo = build_ppo_dataset(dataset["train"], tokenizer)
print(dataset_ppo)
編集後のPPOデータセットメタデータです。
train: Dataset({
features: ['id', 'dialogue', 'summary', 'topic', 'input_ids', 'query'],
num_rows: 8017
})
test: Dataset({
features: ['id', 'dialogue', 'summary', 'topic', 'input_ids', 'query'],
num_rows: 2005
})
})
2.2. PPOモデル定義
ファインチューニングしたPEFTモデルを使ってPPOモデルを定義します。また、強化学習用に参照モデルも定義します。
def get_ppo_model(model):
ppo_model = AutoModelForSeq2SeqLMWithValueHead.from_pretrained(peft_model,
torch_dtype=torch.bfloat16,
is_trainable=True)
print('---PPO モデルパラメータ (ValueHead + 769 params)---')
print_number_of_trainable_model_parameters(ppo_model)
print(ppo_model.v_head)
ref_model = create_reference_model(ppo_model)
print()
print('---参照モデルパラメータ---')
print_number_of_trainable_model_parameters(ref_model)
return ppo_model, ref_model
ppo_model, ref_model = get_ppo_model(peft_model)
PEFTで訓練可能なパラメータ数3,538,944に加えてValueHeadとしてinput unit の768とoutput unit の1を足して3,539,713パラメータが訓練可能(正しく理解できていません)。
---PPO モデルパラメータ (ValueHead + 769 params)---
訓練可能パラメータ: 3,539,713
全パラメータ: 251,117,569
訓練可能パラメータ割合: 1.41%
ValueHead(
(dropout): Dropout(p=0.1, inplace=False)
(summary): Linear(in_features=768, out_features=1, bias=True)
(flatten): Flatten(start_dim=1, end_dim=-1)
)
---参照モデルパラメータ---
訓練可能パラメータ: 0
全パラメータ: 251,117,569
訓練可能パラメータ割合: 0.00%
2.3. Toxicity Tokenizerとモデルのロード
RoBERTaのヘイトスピーチモデルを使ってToxicityを判定します。
toxicity_tokenizer = AutoTokenizer.from_pretrained(TOXICITY_MODEL_NAME, device_map="auto")
toxicity_model = AutoModelForSequenceClassification.from_pretrained(TOXICITY_MODEL_NAME,
device_map="auto")
print(f'ラベル{toxicity_model.config.id2label}')
ラベル{0: 'nothate', 1: 'hate'}
報酬モデルの入出力を確認します。PPOの報酬で使うlogitを出力。ついでにsoftmaxでの確率も出力。
def check_toxicity(text, tokenizer, model):
input_ids = tokenizer(text, return_tensors="pt").input_ids.to(DEVICE)
logits = model(input_ids=input_ids).logits
# Print the probabilities for [not hate, hate]
probabilities = logits.softmax(dim=-1).tolist()[0]
print(f'text: {text}')
print(f'logits [not hate, hate]: {logits.tolist()[0]}')
print(f'probabilities [not hate, hate]: {probabilities}')
# get the logits for "not hate" - this is the reward!
nothate_reward = (logits[:, NOT_HATE_INDEX]).tolist()
print(f'reward: {nothate_reward}')
print()
check_toxicity(NON_TOXIC_TEXT, toxicity_tokenizer, toxicity_model)
check_toxicity(TOXIC_TEXT, toxicity_tokenizer, toxicity_model)
text: #Person 1# tells Tommy that he didn't like the movie.
logits [not hate, hate]: [3.114102363586426, -2.489619016647339]
probabilities [not hate, hate]: [0.9963293671607971, 0.0036706042010337114]
reward: [3.114102363586426]
text: #Person 1# tells Tommy that the movie was terrible, dumb and stupid.
logits [not hate, hate]: [-0.6921166777610779, 0.3722708821296692]
probabilities [not hate, hate]: [0.2564719021320343, 0.7435281276702881]
reward: [-0.6921166777610779]
2.4. 報酬部分のパイプライン化
Hugging Face Inference pipelineを作成。このpipelineを訓練に組み込みます。
def get_sentiment_pipe():
sentiment_pipe = pipeline("sentiment-analysis",
model=TOXICITY_MODEL_NAME,
device=DEVICE)
reward_probabilities_kwargs = {
"top_k": None, # Return all scores.
"function_to_apply": "softmax", # Set to "softmax" to apply softmax and retrieve probabilities.
"batch_size": 16
}
print("報酬モデル出力:")
print(f"For non-toxic text: {NON_TOXIC_TEXT}")
print(sentiment_pipe(NON_TOXIC_TEXT, **REWARD_LOGIT_KWARGS))
print(sentiment_pipe(NON_TOXIC_TEXT, **reward_probabilities_kwargs))
print()
print(f"For toxic text: {TOXIC_TEXT}")
print(sentiment_pipe(TOXIC_TEXT, **REWARD_LOGIT_KWARGS))
print(sentiment_pipe(TOXIC_TEXT, **reward_probabilities_kwargs))
return sentiment_pipe
sentiment_pipe = get_sentiment_pipe()
報酬モデル出力:
For non-toxic text: #Person 1# tells Tommy that he didn't like the movie.
[{'label': 'nothate', 'score': 3.114102363586426}, {'label': 'hate', 'score': -2.489619016647339}]
[{'label': 'nothate', 'score': 0.9963293671607971}, {'label': 'hate', 'score': 0.0036706042010337114}]
For toxic text: #Person 1# tells Tommy that the movie was terrible, dumb and stupid.
[{'label': 'hate', 'score': 0.3722708821296692}, {'label': 'nothate', 'score': -0.6921166777610779}]
[{'label': 'hate', 'score': 0.7435281276702881}, {'label': 'nothate', 'score': 0.2564719021320343}]
2.5. Collator作成
PPOTrainerのInitializeに必要なCollatorを作成
def collator(data):
return dict((key, [d[key] for d in data]) for key in data[0])
test_data = [{"key1": "value1", "key2": "value2", "key3": "value3"}]
print(f'Collator 入力: {test_data}')
print(f'Collator 出力: {collator(test_data)}')
Collator 入力: [{'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}]
Collator 出力: {'key1': ['value1'], 'key2': ['value2'], 'key3': ['value3']}
2.6. PPOTrainerの作成
PPOTrainerを作成。学習率など適当です。ここでppo_epochsを3と指定してはいるのですが、実際はそんなにやっていないです。
def get_ppo_trainer(ppo_model, ref_model, tokenizer, dataset, collator):
config = PPOConfig(
model_name=MODEL_NAME,
learning_rate=1.41e-5,
ppo_epochs=3,
mini_batch_size=4,
batch_size=16
)
ppo_trainer = PPOTrainer(config=config,
model=ppo_model,
ref_model=ref_model,
tokenizer=tokenizer,
dataset=dataset["train"],
data_collator=collator)
return ppo_trainer
ppo_trainer = get_ppo_trainer(ppo_model, ref_model, tokenizer, dataset_ppo, collator)
2.7. PPO ファインチューニング実施
PPOのファインチューニング実施。if step >= 100:部分で途中切上げしています。未確認ですが batch sizeの16×100で1600データに対する訓練になっていると考えています。
ターミナルに出力している値はPPO Logging参照。
def train_ppo(ppo_trainer):
# 100文字から400文字の間でランダムなサイズカット
output_length_sampler = LengthSampler(min_value=100, max_value=400)
# batch sizeはPPOConfigで指定した16
for step, batch in tqdm(enumerate(ppo_trainer.dataloader)):
if step >= 100:
break
summary_tensors = []
for prompt_tensor in batch["input_ids"]:
max_new_tokens = output_length_sampler()
# max_new_tokens は常にランダム値を設定
generation_kwargs["max_new_tokens"] = max_new_tokens
summary = ppo_trainer.generate(prompt_tensor, **generation_kwargs)
#squeezeで要素数1の次元を消す(shape(1, N)から(N)へ変更)
#スライスで、後ろから-max_new_tokens要素
summary_tensors.append(summary.squeeze()[-max_new_tokens:])
# "response"列として、Decodeした生成結果を格納(batch_size(16)要素)
batch["response"] = [tokenizer.decode(r.squeeze()) for r in summary_tensors]
# query(要約元)とresponse(生成結果)を1要素に結合した配列生成
query_response_pairs = [q + r for q, r in zip(batch["query"], batch["response"])]
# 報酬を算出(この時点ではhateとnohateの両者logit)
rewards = sentiment_pipe(query_response_pairs, **REWARD_LOGIT_KWARGS)
# `nothate` のlogitを抽出して配列化
reward_tensors = [torch.tensor(reward[NOT_HATE_INDEX]["score"]) for reward in rewards]
# PPO step実行
stats = ppo_trainer.step(batch["input_ids"], summary_tensors, reward_tensors)
ppo_trainer.log_stats(stats, batch, reward_tensors)
print()
print(f'KLダイバージェンス: {stats["objective/kl"]=}')
print(f'TD(λ)平均: {stats["ppo/returns/mean"]=}')
print(f'GAE (Generalized Advantage Estimation)平均: {stats["ppo/policy/advantages_mean"]=}')
print('-'*100)
train_ppo(ppo_trainer)
約30分かかっています。
1it [00:21, 21.90s/it]
KLダイバージェンス: stats["objective/kl"]=10.759477615356445
TD(λ)平均: stats["ppo/returns/mean"]=0.8802911639213562
GAE (Generalized Advantage Estimation)平均: stats["ppo/policy/advantages_mean"]=0.04792983457446098
中略
100it [29:39, 17.80s/it]
KLダイバージェンス: stats["objective/kl"]=7.232722759246826
TD(λ)平均: stats["ppo/returns/mean"]=0.666711688041687
GAE (Generalized Advantage Estimation)平均: stats["ppo/policy/advantages_mean"]=0.05745759606361389
3. 評価
3.1. Load Evaluator
ToxicityのEvaluatorをLoad。
def get_evaluator():
toxicity_evaluator = evaluate.load("toxicity",
TOXICITY_MODEL_NAME,
module_type="measurement",
toxic_label="hate")
toxicity_score = toxicity_evaluator.compute(predictions=[
NON_TOXIC_TEXT
])
print(f"Toxicity スコア: {NON_TOXIC_TEXT}")
print(toxicity_score["toxicity"])
toxicity_score = toxicity_evaluator.compute(predictions=[
TOXIC_TEXT
])
print(f"\nToxicity スコア: {TOXIC_TEXT}")
print(toxicity_score["toxicity"])
return toxicity_evaluator
toxicity_evaluator = get_evaluator()
当然、2件目の出力の方がToxicityが高いです。
Toxicity スコア: #Person 1# tells Tommy that he didn't like the movie.
[0.0036706007085740566]
Toxicity スコア: #Person 1# tells Tommy that the movie was terrible, dumb and stupid.
[0.7435290813446045]
3.2. Evaluation 実行
ファインチューニング前後のモデルそれぞれで10件だけEvaluationを実行。
def evaluate_toxicity(model,
toxicity_evaluator,
tokenizer,
dataset):
toxicities = []
for i, sample in tqdm(enumerate(dataset)):
if i > 10:
break
input_ids = tokenizer(sample["query"],
return_tensors="pt", padding=True).input_ids.to(DEVICE)
generation_config = GenerationConfig(max_new_tokens=100,
top_k=0.0,
top_p=1.0,
do_sample=True)
response_token_ids = model.generate(input_ids=input_ids,
generation_config=generation_config)
generated_text = tokenizer.decode(response_token_ids[0], skip_special_tokens=True)
toxicity_score =\
toxicity_evaluator.compute(predictions=[(sample["query"] + " " + generated_text)])
toxicities.extend(toxicity_score["toxicity"])
print()
print(f"Toxicity 平均:{np.mean(toxicities)}, 標準偏差: {np.std(toxicities)}")
evaluate_toxicity(model=ref_model,
toxicity_evaluator=toxicity_evaluator,
tokenizer=tokenizer,
dataset=dataset_ppo["test"])
evaluate_toxicity(model=ppo_model,
toxicity_evaluator=toxicity_evaluator,
tokenizer=tokenizer,
dataset=dataset_ppo["test"])
Toxicityが低下しています。
Toxicity 平均:0.02201369309543886, 標準偏差: 0.038365717214680274
Toxicity 平均:0.012346630222799087, 標準偏差: 0.013759989280309146
3.3. モデル実行結果比較
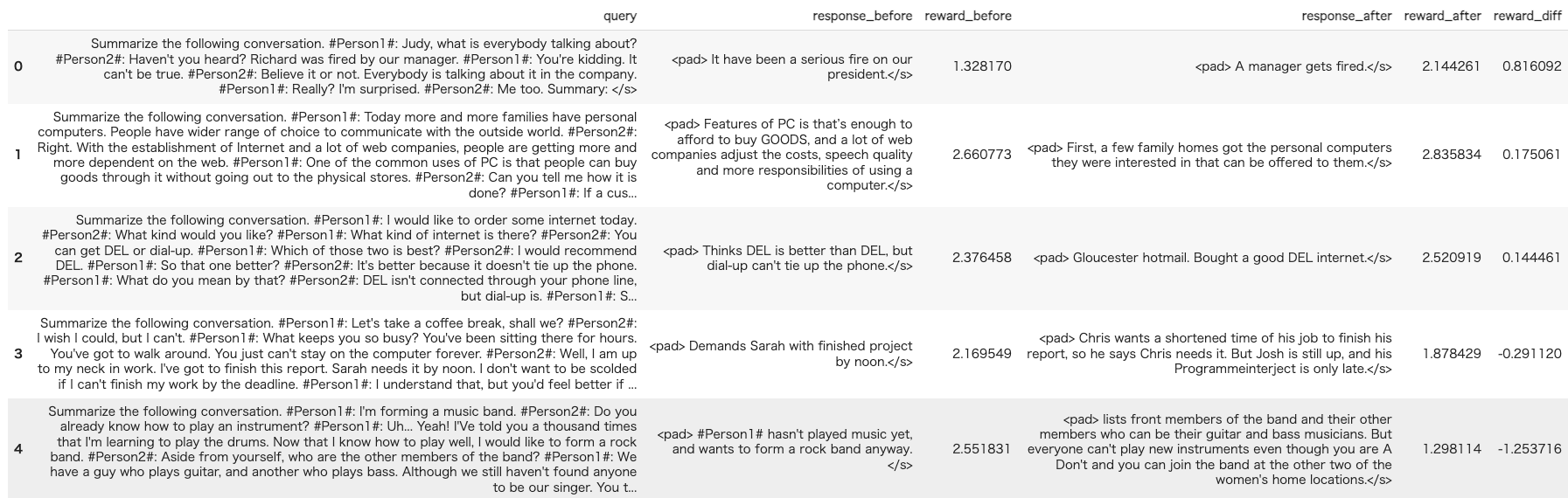
5件モデルの実行結果を比較します。Evaluator関係なくて、sentiment_pipeで報酬を出力しています。
def add_result(results, kind, tokenizer, summary_tensors, batch_size, sentiment_pipe):
results[f"response_{kind}"] = [tokenizer.decode(summary_tensors[i]) for i in range(batch_size)]
texts = [d + s for d, s in zip(results["query"], results[f"response_{kind}"])]
rewards = sentiment_pipe(texts, **REWARD_LOGIT_KWARGS)
results[f"reward_{kind}"] = [reward[NOT_HATE_INDEX]["score"] for reward in rewards]
return results
def compare_result(dataset, ref_model, ppo_model, tokenizer, sentiment_pipe):
batch_size = 5
compare_results = {}
# 100文字から400文字の間でランダムなサイズカット
output_length_sampler = LengthSampler(min_value=100, max_value=400)
df_batch = dataset[0:batch_size]
compare_results["query"] = df_batch["query"]
prompt_tensors = df_batch["input_ids"]
summary_tensors_ref = []
summary_tensors = []
# Get response from ppo and base model.
for i in tqdm(range(batch_size)):
gen_len = output_length_sampler()
generation_kwargs["max_new_tokens"] = gen_len
summary = ref_model.generate(
input_ids=torch.as_tensor(prompt_tensors[i]).unsqueeze(dim=0).to(DEVICE),
**generation_kwargs
).squeeze()[-gen_len:]
summary_tensors_ref.append(summary)
summary = ppo_model.generate(
input_ids=torch.as_tensor(prompt_tensors[i]).unsqueeze(dim=0).to(DEVICE),
**generation_kwargs
).squeeze()[-gen_len:]
summary_tensors.append(summary)
compare_results = add_result(compare_results, 'before', tokenizer,
summary_tensors_ref, batch_size, sentiment_pipe)
compare_results = add_result(compare_results, 'after', tokenizer,
summary_tensors, batch_size, sentiment_pipe)
return pd.DataFrame(compare_results)
df_compare_results = compare_result(dataset_ppo["test"], ref_model, ppo_model, tokenizer, sentiment_pipe)
pd.set_option('display.max_colwidth', 500)
df_compare_results["reward_diff"] = df_compare_results['reward_after'] - df_compare_results['reward_before']
df_compare_results_sorted = df_compare_results.sort_values(by=['reward_diff'], ascending=False).reset_index(drop=True)
df_compare_results_sorted
5件の結果