PandasのDataFrameをいつもググりながら使っていましたが、同じことをやろうとしてもいくつか方法があり、整理をしてみました。Jupyter前提で、行と列を指定して内容を見る方法の整理です。
「pandasで任意の位置の値を取得・変更するat, iat, loc, iloc」を参考にしました。
似た内容として記事「DataFrameレシピ: データ抽出条件」にブールインデックスやquery関数を使った抽出方法も書いています。
環境
2021年2月にGoogle Colaboratory使っています。そのため、Pythonやそのパッケージはそのままのバージョンで使っています。
| 種類 | バージョン |
|---|---|
| Python | 3.6.9 |
上記環境で、以下のPython追加パッケージバージョンでした。
| 種類 | バージョン |
|---|---|
| jupyter | 1.0.0 |
| numexpr | 2.7.2 |
| numpy | 1.19.5 |
| pandas | 1.1.5 |
基本: 4つのプロパティ(iat, at, iloc, loc)
DataFrameには任意の位置を取得するためのプロパティがあります(関数ではありません)。そのためdf.loc()ではなくdf.loc[]のように使います。
| 数字アクセス | 名前アクセス | |
|---|---|---|
| 単独値アクセス | iat | at |
| 複数値アクセス | iloc | loc |
まとめ
まとめからです。データ作成部分と行列指定部分だけピックアップしました。
データ作成
> df = pd.DataFrame({'A': [-20, -10, 0, 10, 20],
'B': [1, 2, 3, 4, 5],
'C': ['a', 'b', 'b', 'b', 'a'],
'D': ['abc', 'bbb', 'bcb', 'bbb', 'abb']})
> print(df)
A B C D
0 -20 1 a abc
1 -10 2 b bbb
2 0 3 b bcb
3 10 4 b bbb
4 20 5 a abb
行列指定
# 行列指定
print(df.at[1, 'B'])
print(df.loc[1, 'B'])
print(df.iat[1, 1])
print(df.iloc[1, 1])
print(df.B.at[1])
# 単一列のみ指定
print(df['B'])
print(df.loc[:,['B']]) #df.loc[:,'B'] でもOKだが出力がストライプなし
print(df.iloc[:, [1]]) #df.iloc[:,1] でもOKだが出力がストライプなし
# 複数列指定
print(df.loc[:,['B', 'C']])
print(df.iloc[:, [1, 2]])
print(df.loc[:,'B':'D']) # スライス方式
print(df.iloc[:, 1:4]) # スライス方式
# 単一行指定
print(df.loc[1, :])
print(df.iloc[1, : ]) # indexが数値なのでlocと変わらず
# 複数行指定
print(df.loc[[1, 2], :])
print(df.iloc[[1, 2], : ]) # indexが数値なのでlocと変わらず
print(df.loc[1:3, :]) # スライス方式
print(df.iloc[1:3, : ]) # スライス方式: indexが数値なのでlocと変わらず
詳細説明
DataFrame作成
まずはDataFrameを作成。
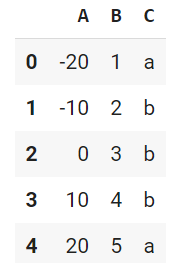
df = pd.DataFrame({'A': [-20, -10, 0, 10, 20],
'B': [1, 2, 3, 4, 5],
'C': ['a', 'b', 'b', 'b', 'a']})
loc / ilocプロパティ
locプロパティまたはilocプロパティを使って列と行を指定します。最初の引数がインデックス名で最後のインデックスが列名です。
> df.loc[1, 'A']
-10
> df.iloc[1, 0]
-10
両引数とも配列で複数指定ができます。引数を配列形式にするとストライプのかかった表形式で出力してくれ、少し見やすいです([]で囲むのが少し面倒ですが)。
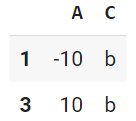
df.loc[[1, 3],['A','C']]
# df.iloc[[1, 3],[0, 2]] でも同じ
行指定
行だけを指定すると各列を返します。
> df.loc[1]
# df.iloc[1]でも同じ
A -10
B 2
C b
Name: 1, dtype: object
複数インデックスの場合はこんな感じ。
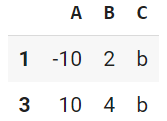
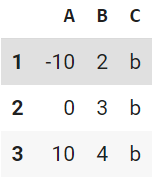
df.loc[[1, 3]]
スライスを使った範囲指定も可能
df.loc[1:3]
# df.iloc[[1, 3]] でも同じ
列指定
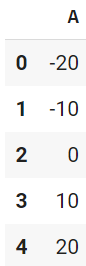
1列だけ出します。
df.loc[:,'A']
> df.A や df.iloc[:, 0]でも同じ
0 -20
1 -10
2 0
3 10
4 20
Name: A, dtype: int64
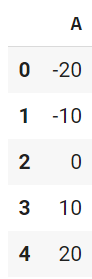
配列にして列を渡せばストライプの表形式で出力できます。少し見やすいですね。
df.loc[:,['A']]
# df.iloc[: , [0]] でも同じ
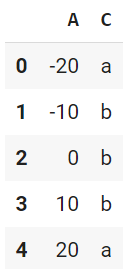
複数列を配列で渡します。
df.loc[:,['A', 'C']]
# df.iloc[:,[0, 2]] でも同じ
スライス
start:stop:stepのスライスを使って指定ができます。stepは省略可能で、あまり使わないと思います。注意点は、ilocの場合はstopの数の1つ前までですが、locの場合はstopの行/列までアクセスします。
df.loc[:, 'B':'C']
# df.iloc[:, 1:3] も同じ
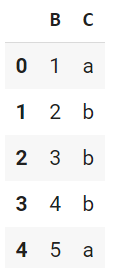
行のスライス使用。
df.loc[1:3, :]
# df.iloc[1:3, :] も同じ
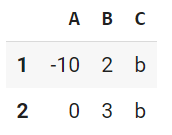
行・列のスライス使用。
df.loc[1:3, 'B':'C']
# df.iloc[1:3, 1:3] も同じ

at / iat プロパティ
本当はこちらの方がシンプルなのでloc / ilocより先に書くべきかもしれませんが、あまり使いたいと思ったことがないので後ろにしています。loc / iloc と違って単独値にアクセスするためのプロパティです。
> df.at[1, 'B']
# df.iat[1, 1] でもOK
2
DataFrameだけだなくSeriesオブジェクトにも使えます。
df.B.at[1]
実践 Tips
基本: Boolean で対象判定
locプロパティでTrueとFalseを使うこともでき、これによる応用が役に立ちます。Trueだとアクセス対象です。ブールインデックスと呼ぶようです。
イマイチ違いがわかりませんが、locプロパティなしでも可能です。
df[[True, False, True, False, True]]
# df.loc[[True, False, True, False, True]] も同じ
# df.iloc[[True, False, True, False, True]] も同じ
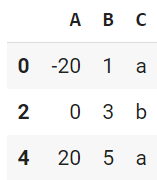
もちろん、列指定してもよし。ただし、列指定もすると、locプロパティが必要
df.loc[[True, False, True, False, True],['B']]
# この場合はdf[[True, False, True, False, True],['B']] はNG
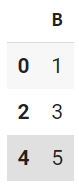
以下の書き方でもいいが、ストライプ形式では出力されない。この場合は列指定をプロパティ内でしていないのでloc不要。
> df[[True, False, True, False, True]].B
0 1
2 3
4 5
Name: B, dtype: int64
抽出との組み合わせ
ここからが実践的な内容です。
例えば、列で値がXXと一致する場合の各行の値を見たければこう書きます。
df[df['C']=='b']
# df['C']=='b' の部分が True/ Falseを返す
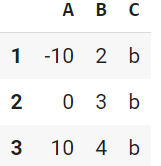
抽出して値設定
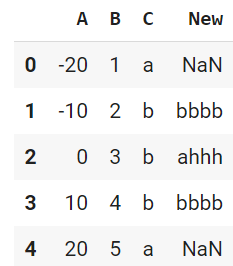
値が一致したらば新しい列'New'を作って値を設定することもできます。query関数はTrue, Falseを返さないので、この場合は使えない気がします(あまり調べていないです)。
df.loc[df['C']=='b', 'New'] = 'bbbb'
df
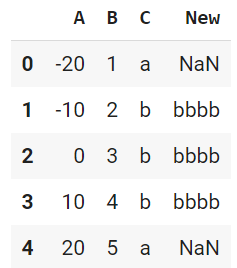
上ではNew列がなかったので新列を作るような動きになっています。列名が存在する場合には、その列名にアクセスします。上の状態の後に実行すると、列Newが既に存在するので新規列は作成されません。
df.loc[df['B']==3, 'New'] = 'ahhh'
df